Characteristics of secondary indexes
Secondary indexes can be used with HISAM, HDAM, PHDAM, HIDAM, DEDB, and PHIDAM databases.
A secondary index is in its own a separate database and must use VSAM as its access method. Because a secondary index is in its own a database, it can be processed as a separate database.
Secondary indexes for full-function databases are invisible to the application program. When an application program needs to access a full-function database using the secondary index, this fact is communicated to IMS™ by coding the PROCSEQ= parameter in the PCB. If an application program needs to do processing using the regular processing sequence, PROCSEQ= is not coded. If the application program needs to do processing using both the regular processing sequence and the secondary index, the PSB for the application program must contain two PCBs, one with PROCSEQ= coded and one without.
Secondary indexes for Fast Path databases are also invisible to the application program. When a DEDB database needs to be accessed using its Fast Path secondary index, the PROCSEQD= parameter in the PCB is used to specify the name of the Fast Path secondary index database to use to access the primary DEDB database. The PROCSEQD= parameter has the same function as the full-function PROCSEQ= parameter. The PROCSEQD= parameter stands for PROCSEQ for DEDB databases.
When two PCBs are used, it enables an application program to use two paths into the database and two sequence fields. One path and sequence field is provided by the regular processing sequence, and one is provided by the secondary index. The secondary index gives an application program both an alternative way to enter the database and an alternative way to sequentially process database records.
If a PSB contains only a Fast Path secondary index PCB to access the Fast Path secondary index database as a separate database, the associated DEDB PCB must be included in the PSB. The minimal DEDB PCB requires a SENSEG statement for the root segment of the associated DEDB database.
A final characteristic of full-function secondary indexes is that there can be 32 secondary indexes for a segment type and a total of 1000 secondary indexes for a single full-function database.
Fast Path secondary index databases can be HISAM or SHISAM databases.
- User data partitioning
- A single Fast Path secondary index can span multiple physical
databases, each of which is considered a partition. Each partition
can contain a range of keys. Index keys are assigned to a partition
by a user partition selection exit routine. The index databases can
be accessed individually or as one logical separate database.The partitions for a Fast Path secondary index are created using the DBD generation utility. When user partitioning for a Fast Path HISAM secondary index database or a Fast Path SHISAM secondary index database is requested:
- The PROCSEQD= parameter specifies the name of the first partition database in the user partition group.
- The PSELRTN= parameter specifies the DEDB partition selection exit routine that is used to determine the actual partition. The sample that is shipped with IMS is the Data Entry Database Partition Selection exit routine (DBFPSE00).
When the DEDB Partition Selection exit routine is not called, the PSELOPT=MULT|SNGL parameter can be used to indicate how many partition databases are processed before a GB status code is returned to an application to indicate the end of the database. PSELOPT= can be specified in both XDFLD statement or PCB with PROCSEQD= statement. If both are specified, the one in the PCB statement takes precedence.
Each Fast Path secondary index database can have a maximum of 101 user partition databases. Two or more user partition databases, separated by commas and enclosed in parentheses can be specified after the secondary index segment name in the NAME= parameter on the LCHILD statement in the primary DEDB database.
User data partitioning can be used with multiple secondary index segments.
The following figure illustrates the concept of partitioning Fast Path secondary indexes.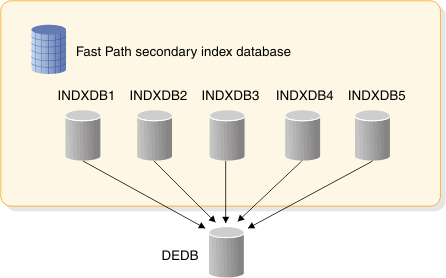
- Multiple secondary index segments
- You can create multiple index entries from different fields in
the same source segment.
This is done by defining two or more LCHILD/XDFLD statement pairs under the SEGM statement of a target segment and specifying the MULTISEG=YES on the LCHILD statement.
A final characteristic of Fast Path secondary indexes is that there can be a maximum of 32 secondary indexes per segment and 255 secondary indexes per DEDB. Each multiple LCHILD/XDFLD statement pair counts towards the 32 secondary indexes per segment limit. When a Fast Path secondary index consists of partition databases, only the Fast Path secondary index database itself (not the partitions) is counted toward the 255 secondary indexes per DEDB limit.