Moving data using a customized application (user exit)
The load SOURCEUSEREXIT option provides a facility through which the load utility can execute a customized script or executable, referred to herein as a user exit.
The purpose of the user exit is to populate one or more named pipes with data that is simultaneously read from by the load utility. In a multi-partition database, multiple instances of the user exit can be invoked concurrently to achieve parallelism of the input data.
As Figure 1 shows, the load utility creates a one or more named pipes and spawns a process to execute your customized executable. Your user exit feeds data into the named pipe(s) while the load utility simultaneously reads.
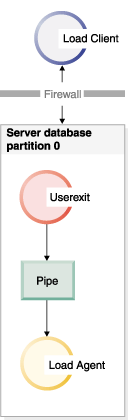
The data fed into the pipe must reflect the load options specified, including the file type and any file type modifiers. The load utility does not directly read the data files specified. Instead, the data files specified are passed as arguments to your user exit when it is executed.
Invoking your user exit
<base pipename> <number of source media>
<source media 1> <source media 2> ... <user exit ID>
<number of user exits> <database partition number>- <base pipename >
- Is the base name for named-pipes that the load utility creates and reads data from. The utility
creates one pipe for every source file provided to the LOAD command, and each of these pipes is
appended with
.xxx, wherexxxis the index of the source file provided. For example, if there are 2 source files provided to the LOAD command, and the <base pipename> argument passed to the user exit ispipe123, then the two named pipes that your user exit should feed with data arepipe123.000andpipe123.001. In a partitioned database environment, the load utility appends the database partition (DBPARTITION) number.yyyto the base pipe name, resulting in the pipe namepipe123.yyy.xxx.. - <number of source media>
- Is the number of media arguments which follow.
- <source media 1> <source media 2> ...
- Is the list of one or more source files specified in the LOAD command. Each source file is placed inside double quotation marks.
- <user exit ID>
- Is a special value useful when the PARALLELIZE option is enabled. This integer value (from 1 to N, where N is the total number of user exits being spawned) identifies a particular instance of a running user exit. When the PARALLELIZE option is not enabled, this value defaults to 1.
- <number of user exits>
- Is a special value useful when the PARALLELIZE option is enabled. This value represents the total number of concurrently running user exits. When the PARALLELIZE option is not enabled, this value defaults to 1.
- <database partition number>
- Is a special value useful when the PARALLELIZE option is enabled. This is the database partition (DBPARTITION) number on which the user exit is executing. When the PARALLELIZE option is not enabled, this value defaults to 0.
Additional options and features
The following section describes additional SOURCEUSEREXIT facility options:
- REDIRECT
- This option allows you to pass data into the STDIN handle or capture data from the STDOUT and STDERR handles of the user exit process.
- INPUT FROM BUFFER <buffer>
- Allows you to pass information directly into the STDIN input stream
of your user exit. After spawning the process which executes the user
exit, the load utility acquires the file-descriptor to the STDIN of
this new process and passes in the buffer provided. The user exit
reads from STDIN to acquire the information. The load utility simply
sends the contents of <buffer> to the user exit using STDIN
and does not interpret or modify its contents. For example, if your
user exit is designed to read two values from STDIN, an eight-byte
userid and an eight-byte password, your user exit executable written
in C might contain the following lines:
A user could pass this information using the INPUT FROM BUFFER option as shown in the following LOAD command:rc = read (stdin, pUserID, 8); rc = read (stdin, pPasswd, 8);LOAD FROM myfile1 OF DEL INSERT INTO table1 SOURCEUSEREXIT myuserexit1 REDIRECT INPUT FROM BUFFER myuseridmypasswdNote: The load utility limits the size of <buffer> to the maximum size of a LOB value. However, from within the command line processor (CLP), the size of <buffer> is restricted to the maximum size of a CLP statement. From within CLP, it is also recommended that <buffer> contain only traditional ASCII characters. These issues can be avoided if the load utility is invoked using the db2Load API, or if the INPUT FROM FILE option is used instead. - INPUT FROM FILE <filename>
- Allows you to pass the contents of a client side file directly into the STDIN input stream of your user exit. This option is almost identical to the INPUT FROM BUFFER option, however this option avoids the potential CLP limitation. The filename must be a fully qualified client side file and must not be larger than the maximum size of a LOB value.
- OUTPUT TO FILE <filename>
- Allows you to capture the STDOUT and STDERR streams from your user exit process into a server side file. After spawning the process which executes the user exit executable, the load utility redirects the STDOUT and STDERR handles from this new process into the filename specified. This option is useful for debugging and logging errors and activity within your user exit. The filename must be a fully qualified server side file. When the PARALLELIZE option is enabled, one file exists per user exit and each file appends a three-digit numeric identifier, such as filename.000.
- PARALLELIZE
- This option can increase the throughput of data coming into the load utility by invoking multiple user exit processes simultaneously. This option is only applicable to a multi-partition database. The number of user exit instances invoked is equal to the number of partitioning agents if data is to be distributed across multiple database partitions during the load operation, otherwise it is equal to the number of loading agents.
i = <user exit ID>
N = <number of user exits>
foreach record
{
if ((unique-integer MOD N) == i)
{
write this record to my named-pipe
}
}- As Figure 2 shows, one user exit
process is spawned for every pre-partitioning agent when PARTITION_AND_LOAD (default)
or PARTITION_ONLY without PARALLEL is specified.
.
Figure 2. The various tasks performed when PARTITION_AND_LOAD (default) or PARTITION_ONLY without PARALLEL is specified. 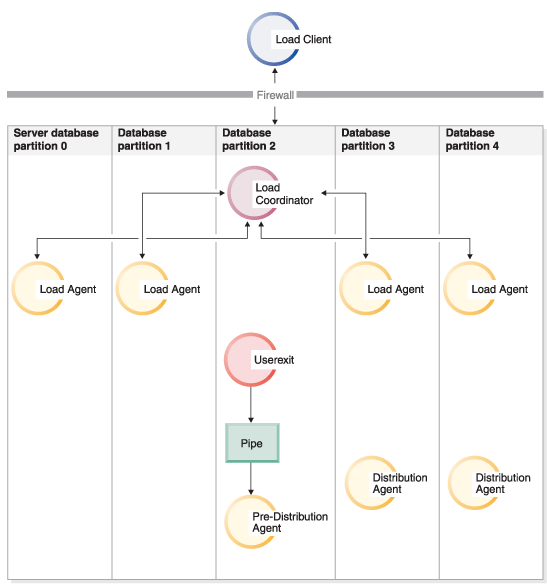
- As Figure 3 shows, one user exit
process is spawned for every partitioning agent when PARTITION_AND_LOAD (default)
or PARTITION_ONLY with PARALLEL is
specified.
Figure 3. The various tasks performed when PARTITION_AND_LOAD (default) or PARTITION_ONLY with PARALLEL is specified. 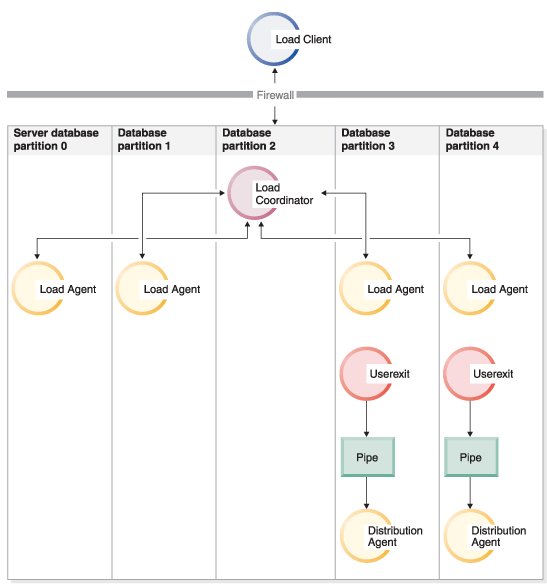
- As Figure 4 shows, one user exit
process is spawned for every load agent when LOAD_ONLY or LOAD_ONLY_VERIFY_PART is
specified.
Figure 4. The various tasks performed when LOAD_ONLY or LOAD_ONLY_VERIFY_PART is specified. 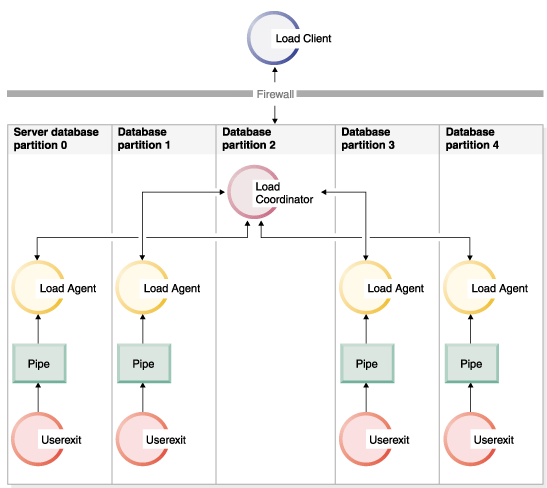
Restrictions
- The LOAD_ONLY and LOAD_ONLY_VERIFY_PART partitioned-db-cfg mode options are not supported when the SOURCEUSEREXIT PARALLELIZE option is not specified.
Examples
DB2 LOAD FROM /path/file1 OF DEL INSERT INTO schema1.table1
SOURCEUSEREXIT example1.pl REDIRECT INPUT FROM BUFFER " ," OUTPUT TO FILE /path/ue_msgs.txt#!/bin/perl
# Filename: example1.pl
#
# This script is a simple example of a userexit for the Load utility
# SOURCEUSEREXIT feature. This script replaces old delimiter character with new
# as specified using the input buffer option.
#
# For example: we could replace all tab character '\t'
# with comma character ',' from every record of the source media file.
#
# To invoke the Load utility using this userexit, use a command similar to:
#
# db2 LOAD FROM /path/file1 OF DEL INSERT INTO schema1.table1
# SOURCEUSEREXIT example1.pl REDIRECT INPUT FROM BUFFER \"\t ,\" OUTPUT TO FILE /path/ue_msgs.txt
#
# The userexit must be placed into the sqllib/bin/ folder, and requires
# execute permissions.
#--------------------------------------------------------------------
if ($#ARGV < 5)
{
print "Invalid number of arguments:\n@ARGV\n";
print "Load utility should invoke userexit with 5 arguments (or more):\n";
print "<base pipename> <number of source media> ";
print "<source media 1> <source media 2> ... <user exit ID> ";
print "<number of user exits> <database partition number> ";
print "<(old delimiter to replace) (new delimiter to replace with)> \n";
die;
}
my $delimiters = <STDIN>;
my ($old, $new) = split / /, $delimiters;
# Open the output fifo file (the Load utility is reading from this pipe)
#-----------------------------------------------------------------------
$basePipeName = $ARGV[0];
$outputPipeName = sprintf("%s.000", $basePipeName);
open(PIPETOLOAD, '>', $outputPipeName) || die "Could not open $outputPipeName";
# Get number of Media Files
#--------------------------
$NumMediaFiles = $ARGV[1];
# Open each media file, read the contents, replace '\t' with ',', send to Load
#-----------------------------------------------------------------------------
for ($i=0; $i<$NumMediaFiles; $i++)
{
# Open the media file
#--------------------
$mediaFileName = $ARGV[2+$i];
open(MEDIAFILETOREAD, '<', $mediaFileName) || die "Could not open $mediaFileName";
# Read each record of data
#------------------------
while ( $line = <MEDIAFILETOREAD> )
{
# Replace old delimiter character with new
#------------------------------------------
$line =~ s/$old/$new/g;
# send this record to Load for processing
#-----------------------------------------
print PIPETOLOAD $line;
}
# Close the media file
#---------------------
close MEDIAFILETOREAD;
}
# Close the fifo
#---------------
close PIPETOLOAD;
exit 0;