Parallel index building for REORG TABLESPACE
Parallel index building reduces the elapsed time for a REORG TABLESPACE job by sorting the index keys and rebuilding multiple indexes in parallel, rather than sequentially. Optimally, a pair of subtasks processes each index; one subtask sorts extracted keys, whereas the other subtask builds the index.
REORG TABLESPACE begins building each index as soon as the corresponding sort emits its first sorted record. The following figure shows the flow of a REORG TABLESPACE job that uses a parallel index build. Db2 starts multiple subtasks to sort index keys and build indexes in parallel. If you specify STATISTICS, additional subtasks collect the sorted keys and update the catalog table in parallel, eliminating the need for a second scan of the index by a separate RUNSTATS job.
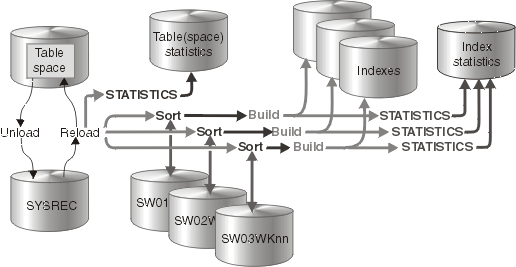
REORG TABLESPACE uses parallel index build if more than one index needs to be built (including the mapping index for SHRLEVEL CHANGE). You can either let the utility dynamically allocate the data sets that SORT needs for this parallel index build or provide the necessary data sets yourself. The number of subtasks must be less than or equal to the number that is specified by the PARALLEL option. If you do not specify the PARALLEL option, the PARAMDEG_UTIL subsystem parameter determines the maximum degree of parallelism for the utility.
Select one of the following methods to allocate sort work and message data sets:
REORG TABLESPACE determines the optimal number of sort work data sets and message data sets.
- Specify the SORTDEVT keyword in the utility statement.
- Allow dynamic allocation of sort work data sets by not supplying SORTWKnn DD statements in the REORG TABLESPACE utility JCL.
- Allocate UTPRINT to SYSOUT.
Control allocation of sort work data sets, while REORG TABLESPACE allocates message data sets.
 Provide
DD statements with DD names in the form SWnnWKmm. The
first of these DD statements must be SW01WK01.
Provide
DD statements with DD names in the form SWnnWKmm. The
first of these DD statements must be SW01WK01.
- Allocate UTPRINT to SYSOUT.
Exercise the most control over rebuild processing; specify both sort work data sets and message data sets.
- Provide
DD statements with DD names in the form SWnnWKmm. The
first of these DD statements must be SW01WK01.
- Provide DD statements with DD names in the form UTPRINnn.
Data sets used
If you select Method 2 or 3 in the preceding information, define the necessary data sets by using the following information.
Each sort subtask must have its own group of sort work data sets and its own print message data set. Possible reasons to allocate data sets in the utility job JCL rather than using dynamic allocation are:
- To control the size and placement of the data sets
- To minimize device contention
- To optimally use free disk space
- To limit the number of utility subtasks that are used to build indexes
The DD name SWnnWKmm defines the sort work data sets that are used during utility processing. nn identifies the subtask pair, and mm identifies one or more data sets that are to be used by that subtask pair. For example:
- SW01WK01
- Is the first sort work data set that is used by the subtask that builds the first index.
- SW01WK02
- Is the second sort work data set that is used by the subtask that builds the first index.
- SW02WK01
- Is the first sort work data set that is used by the subtask that builds the second index.
- SW02WK02
- Is the second sort work data set that is used by the subtask that builds the second index.
The DD name UTPRINnn defines the sort work message data sets that are used by the utility subtask pairs. nn identifies the subtask pair.
Every time you invoke REORG TABLESPACE, new UTPRINnn data sets are dynamically allocated. REORG TABLESPACE does not reuse UTPRINnn data sets from previous job steps. This behavior might cause the available JES2 job queue elements to be consumed more quickly than expected.
Number of sort subtasks
The maximum number of utility subtask pairs that are started for parallel index build is equal to the number of indexes that need to be built.
REORG TABLESPACE determines the number of subtask pairs according to the following guidelines:
- The number of subtask pairs equals the number of allocated sort work data set groups.
- The number of subtask pairs equals the number of allocated message data sets.
- If you allocate both sort work data sets and message data set groups, the number of subtask pairs equals the smallest number of allocated data sets.
Allocation of sort subtasks
REORG TABLESPACE attempts to assign one sort subtask pair for each index that is to be built. If REORG TABLESPACE cannot start enough subtasks to build one index per subtask pair, it allocates any excess indexes across the pairs; therefore one or more subtask pairs might build more than one index.
During parallel index build processing, REORG distributes all indexes among the subtask pairs according to the index creation date, assigning the first created index to the first subtask pair. For SHRLEVEL CHANGE, the mapping index is assigned last.
Estimating the sort work file size
If you choose to provide the data sets, you need to know the size and number of keys that are present in all of the indexes that are being processed by the subtask in order to calculate each sort work file size. After you determine which indexes are assigned to which subtask pairs, use the following formula to calculate the required space:
2 * (longest index key + c) * (number of extracted keys)
- longest key
- The length of the longest index key that is to be processed by the subtask. If the index is of
varying length, the longest key is the maximum possible length of a key with all varying-length
columns that are padded to their maximum length, plus 2 bytes for each varying-length column in the
index. For example, if an index with three columns (A, B, and C) has length values of CHAR(8) for A,
VARCHAR(128) for B, and VARCHAR(50) for C, the longest key is calculated as follows:
For SHRLEVEL CHANGE, the mapping index key length is 21.8 + 128 + 50 + 2 + 2 = 190 - c
- A value as follows:
- 14 if the
indexes that are being rebuilt are a mix of data-partitioned secondary indexes and nonpartitioned
indexes
- 12 if the
indexes that are being rebuilt are partitioned, or if none of them are data-partitioned secondary
indexes.
- number of extracted keys
- The number of keys from all indexes that need to be sorted and that are to be processed by the subtask.
When you calculate the sort work data set size, do not count keys that are not sorted. Keys are not sorted when both of the following conditions are true:
- SORTDATA is in effect for REORG TABLESPACE, and the keys belong to a partitioning, clustering index.
- The table space is a partitioned table space, and data partitions are not being unloaded and reloaded in parallel.
The space estimation formula might indicate that 0 bytes are required, because the only index that is processed is the partitioning, clustering index. In this case, if you allocate your own groups of sort work data sets, you still need to allocate sort work data sets, but you can use a minimal allocation, such as 1 track.