 Monitoring, Version 6.2
Monitoring, Version 6.2
There are two primary technological approaches to configure resiliency or high availability for the Tivoli monitoring platform components. One approach exploits common, commercial high availability cluster manager software. (Examples are High-Availability Cluster Multi-Processing (HACMP) and System Automation-Multi Platform (SA-MP) from IBM, or Microsoft Cluster Server (MSCS).) An alternative approach may be applicable for some sites to make the hub monitoring server resilient to specific failure scenarios. This alternative approach is called Hot Standby in the Tivoli publications. The two approaches provide different resiliency and failover characteristics, depending on your requirements.
The first approach requires the use of a high availability cluster manager such as IBM's SA-MP, HACMP or Microsoft's MSCS. You are entitled to cluster management software with some operating systems and platforms. Using this approach, you can configure all of the components of the monitoring platform for resiliency in the case of component failure. IBM has produced white papers describing specific resiliency configurations using common commercial HA solutions. In addition, since so many users use such a wide range of customized HA solutions, we also provide a general description of Tivoli monitoring platform resiliency requirements that should suffice to set up any typical HA configuration. For more information about using IBM Tivoli Monitoring in a clustered environment, search for "Clustering IBM Tivoli Monitoring" at the IBM Tivoli Open Process Automation Library (OPAL) Web site.
For users primarily concerned with the availability of the hub monitoring server, the monitoring platform provides the built in Hot Standby option. This solution replicates selected state information between the hub monitoring server and a secondary hub monitoring server running in a listening standby mode, heart-beating the active hub and keeping current with much of the hub's environment information. In an appropriately configured environment, the secondary hub monitoring server takes over as the acting hub in the event that the primary hub fails. This solution operates without the requirement for shared or replicated persistent storage between the two monitoring server computers, and does not require cluster manager software. However, it only addresses the hub monitoring server component of the monitoring platform, and is therefore suited to customers without stringent resiliency requirements on the other components of the monitoring platform. See Table 8 for the failover options available for each monitoring component and Table 9 for the resiliency characteristics for each option.
| Component | Potential single point of failure? | Cluster failover available? | Hot Standby failover available? |
|---|---|---|---|
| Hub monitoring server | Yes | Yes | Yes |
| Portal server | Yes | Yes | No |
| Tivoli Data Warehouse database | Yes | Yes | No |
| Warehouse proxy | Yes, if single Warehouse Proxy in environment. | Yes | No |
| Summarization and Pruning agent | Yes | Yes | No |
| Remote monitoring server | No. Another monitoring server can assume the role of a remote monitoring server for connected agents. This is known as "agent failover". | N/A | N/A |
| Agent | Not a single point of failure for the whole monitoring solution, but a specific point of failure for the specific resource being monitored. | Yes | No |
| Component/Feature | Characteristics on hub cluster failover | Characteristics on hub Hot Standby failover |
|---|---|---|
| Hub monitoring server |
The hub monitoring server is restarted as soon as the cluster manager detects failure. |
Communication failure between hubs causes the standby hub to start processing to establish itself as master. |
| Portal server |
The portal server reconnects to hub as soon as it is restarted. |
The portal server needs to be reconfigured to point to the new hub. |
| Tivoli Data Warehouse database |
No relationship to hub |
No relationship to hub |
| Warehouse proxy |
As an agent, the Warehouse Proxy reconnects to its hub and continues to export data from agents to the Tivoli Data Warehouse. |
As an agent configured with secondary connection to hub, the Warehouse Proxy connects to its secondary hub and continues to export data from agents to the Tivoli Data Warehouse. |
| Summarization and Pruning agent |
As an agent, the Summarization and Pruning agent reconnects to its hub and continues to summarize and prune data from the Tivoli Data Warehouse. |
As an agent configured with secondary connection to hub, the Summarization and Pruning agent connects to its secondary hub and continues to summarize and prune data from the Tivoli Data Warehouse. |
| Remote monitoring server |
The remote monitoring server detects the hub restart and tries to reconnect, synchronizing with the hub. |
When configured with secondary connection to hub, the remote monitoring server retries the connection with the primary hub and if unsuccessful tries to connect to the secondary hub. When the new hub has been promoted to master, the remote monitoring server detects the hub restart and tries to reconnect, synchronizing with the hub. |
| Agent |
All agents directly connected to the hub reconnect to the hub after restart and begin synchronization. |
When configured with secondary connection to hub, agents directly connected to the hub perceive the loss of connection and retry. With the first hub down, the agent tries to connect to the second hub, and begin synchronization which includes restarting all situations. |
| Event data |
Agents resample all polled situation conditions and reassert all that are still true. Situation history is preserved. |
Agents resample all polled situation conditions and reassert all that are still true. Previous situations history is not replicated to mirror and thus lost. To persist historical event data, use the OMNIbus or Tivoli Enterprise Console. |
| Hub failback | Available through cluster manager administration/configuration | The secondary hub must be stopped so that primary hub can become master again. |
| Time for failover |
The detection of a failed hub and restart is quick and can be configured through the cluster manager. The synchronization process until all situations are restarted and the whole environment is operational depends on the size of the environment, including the number of agents and distributed situations. |
The detection of a failed hub is quick. There is no restart of the hub, but the connection of remote monitoring server and agents to the standby hub require at least one more heartbeat interval, because they try the primary before trying the secondary. The synchronization process until all situations are restarted and the whole environment is operational depends on the size of the environment, including the number of agents and distributed situations. |
| z/OS environments |
The z/OS hub clustered solution has not yet been tested and therefore is not a supported configuration. Remote monitoring servers on z/OS are supported. |
Hot Standby not supported on z/OS. Hot Standby has not been tested with remote monitoring servers on z/OS and therefore is not a supported configuration. |
| Data available on failover hub |
All data is shared through disk or replication. |
All EIB data, except for the following, is replicated through the mirror synchronization process:
|
| Manageability of failover |
Failover can be automatic or directed through cluster administration. You control which hub is currently the “master" and the current state of the cluster. |
Failover can be directed by stopping the hub. Note that starting order controls which hub is the “master". |
Figure 7 depicts an environment with the Hot Standby feature configured.
The following sections provide an overview of how each component in the IBM Tivoli Monitoring environment is configured to enable the Hot Standby feature.
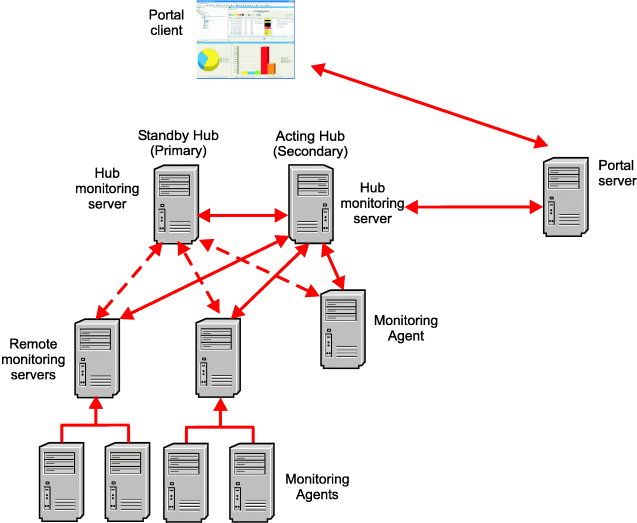
In a Hot Standby environment, there are two hub monitoring servers. The configuration of each hub designates the other hub as the Hot Standby hub. At any given time, one of the two hub monitoring servers is operating as the hub. This server is referred to as the Acting Hub. The other hub monitoring server is in standby mode and is referred to as the Standby Hub. (See Figure 7.)
When the two hub monitoring servers are running, they continuously synchronize their Enterprise Information Base (EIB) data, enabling the Standby Hub to take over the role of the Acting Hub in case the Acting Hub becomes unavailable. The EIB contains definition objects such as situations and policies, information about managed systems, and information about the distribution or assignment of situations and policies to managed systems.
The two hub monitoring servers are symmetrical, but for reasons that will become clear later, one hub monitoring server is designated as the Primary Hub and the other is designated as the Secondary Hub. While it is not necessary, you can designate as the Primary Hub the server that you expect to be the Acting Hub most of the time.
Note that the terms Acting and Standby refer to an operational state, which can change over a period of time. The terms Primary and Secondary refer to configuration, which is relatively permanent.
All remote monitoring servers must be configured to operate in the Hot Standby environment. When you configure each remote monitoring server, you specify the Primary and Secondary hub monitoring servers to which the remote monitoring server reports.
It is important that you specify the same Primary and Secondary hub monitoring servers for each remote monitoring server. In Figure 7, the connections from the remote monitoring servers to the Primary Hub are depicted with solid arrows. The connections to the Standby Hub are depicted with dashed arrows.
Monitoring agents that report directly to the hub monitoring server, as well as the Warehouse Proxy agent and the Summarization and Pruning agent, must be configured to operate in the Hot Standby environment. When you configure each of these agents, you specify the Primary and Secondary hub monitoring servers to which the agents report.
In Figure 7, the connection between these monitoring agents and the Primary Hub is depicted with a solid arrow. The connection to the Standby Hub is depicted with a dashed arrow.
The Tivoli Enterprise Portal Server cannot be configured to fail over to a Standby Hub. When the Standby Hub takes over as the Acting Hub, the portal server needs to be reconfigured to point to the Acting Hub. Portal clients do not need to be reconfigured. They automatically reconnect to the portal server when it restarts after it is reconfigured.
The Hot Standby operation is best illustrated by describing a scenario. In this example, all monitoring components are started in order, a scenario that might take place only when the product is initially installed. After installation, components can be started and stopped independently.
The following list describes the order of startup and what happens as each component is started.
04/17/07 09:38:54 KQM0001 FTO started at 04/17/07 09:38:54.
04/17/07 09:47:04 KQM0001 FTO started at 04/17/07 09:47:04.
04/17/07 09:47:18 KQM0003 FTO connected to IP.PIPE:#9.52.104.155 at 04/17/07 09:47:18. 04/17/07 09:47:33 KQM0009 FTO promoted HUB_PRIMARY as the acting HUB.
04/17/07 09:45:50 KQM0003 FTO connected to IP.PIPE:#9.52.104.155 at 04/17/07 09:45:50. 04/17/07 09:45:58 KQM0009 FTO promoted HUB_PRIMARY as the acting HUB.
When these components start, they attempt to connect to the Primary Hub in their configuration. In this scenario, the Primary Hub is also the current Acting Hub. Therefore, the connection attempt is successful, and these components start reporting to the Primary Hub.
The portal server is configured to connect to the Primary Hub. One or more portal clients are connected to the portal server for monitoring purposes.
The Acting Hub might become unavailable for a number of reasons. It might need to be shut down for scheduled maintenance, the computer on which it is running might need to be shut down or might have crashed, or it could be experiencing networking problems.
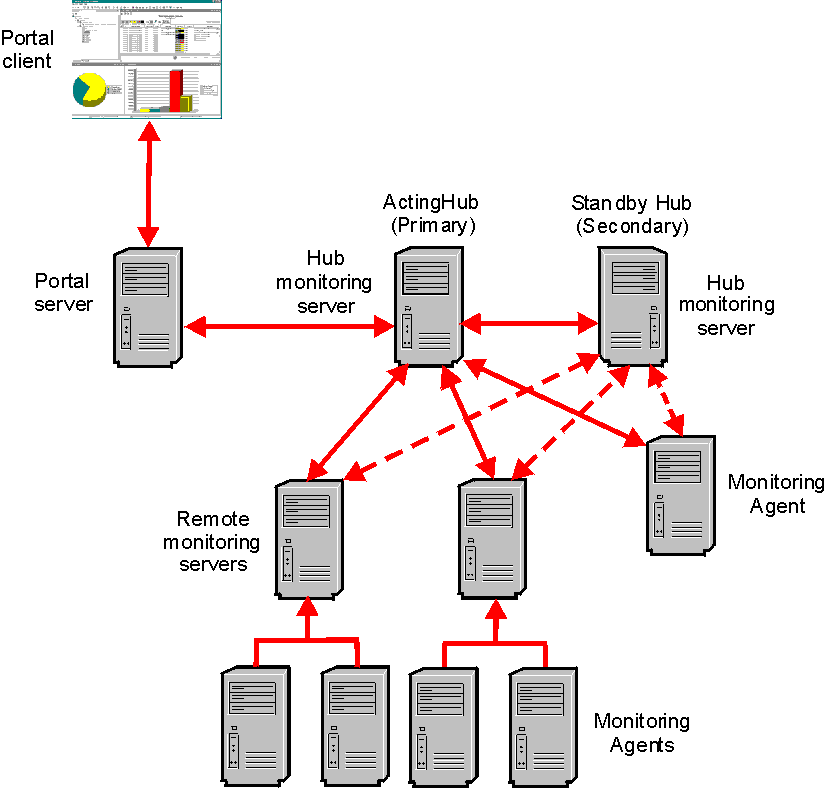
When the Standby Hub discovers that the Acting Hub is unavailable, it takes over the role of the Acting Hub and issues the following messages:
04/17/07 10:46:40 KQM0004 FTO detected lost parent connection at 04/17/07 10:46:40. 04/17/07 10:46:40 KQM0009 FTO promoted HUB_SECONDARY as the acting HUB.
The Primary Hub is now the Standby Hub and the Secondary Hub is the Acting Hub, as depicted in Figure 8:
As the remote monitoring servers and agents connected to the previous Acting Hub discover that this hub is no longer available, they switch and reconnect to the new Acting Hub. Because these components are in various states of processing and communication with the hub monitoring server, the discovery and re-connection with the new hub is not synchronized.
The Tivoli Enterprise Portal Server must be reconfigured to point to the new Acting Hub and then restarted. All portal clients reconnect to the portal server after it is restarted.
The processing that takes place after re-connection is similar to the processing that takes place after re-connection in an environment without a Hot Standby server. The following processing takes place with regard to situations and policies:
The new Acting Hub retains its role even after the other hub monitoring server becomes operational again. The other hub monitoring server now becomes the Standby Hub. When the new Standby Hub starts, it checks the EIB of the new Acting Hub for updates, and replicates the updates to its own EIB if necessary. The two hubs also start monitoring connections with each other to ensure that the other hub is running.
All remote monitoring servers and agents now report to the new Acting Hub. There is no mechanism available to switch them back to the Standby Hub while the Acting Hub is still running. The only way to switch them to the Standby Hub is to shut down the Acting Hub.
If a remote monitoring server or agent experiences a transient communication problem with the Acting Hub, and switches over to the Standby Hub, the Standby Hub instructs it to retry the connection with the Acting Hub, because the Standby Hub knows that the Acting Hub is still available.
The environment continues to operate with the configuration shown in Using Hot Standby until there is a need to shut down the Acting Hub, or if the computer on which the Acting Hub is running becomes unavailable. Each time the Acting Hub becomes unavailable, the failover scenario described in this section is repeated.
This section provides an overview of Tivoli Monitoring high availability when using clustering technologies. It explains clustering concepts, describes the supported Tivoli Monitoring cluster configurations, provides an overview of the setup steps, and describes the expected behavior of the components running in a clustered environment.
For more information about using IBM Tivoli Monitoring in a clustered environment, search for "Clustering IBM Tivoli Monitoring" at the IBM Tivoli Open Process Automation Library (OPAL) Web site: http://catalog.lotus.com/wps/portal/topal/. Detailed instructions on how to set up Tivoli Monitoring components on different cluster managers are provided in separate papers, initially including: Microsoft® Cluster Server, Tivoli System Automation Multiplatform and HACMP (High-Availability Cluster Multi-Processing).
Review the following concepts to enhance your understanding of clustering technology:
Although clusters can be used in configurations other than basic failover (for example, load sharing and balancing), the current Tivoli Monitoring design does not support multiple, concurrent instances of the monitoring components.
Consider the following three clustering configurations:
IBM DB2 was the database used in all of the configuration tests. Other Tivoli Monitoring-supported databases can also be clustered by following the specific database cluster setup procedures. All the clustering configurations include at least one agent directly reporting to the hub. For simplicity, this is not shown in the configuration diagrams that follow.
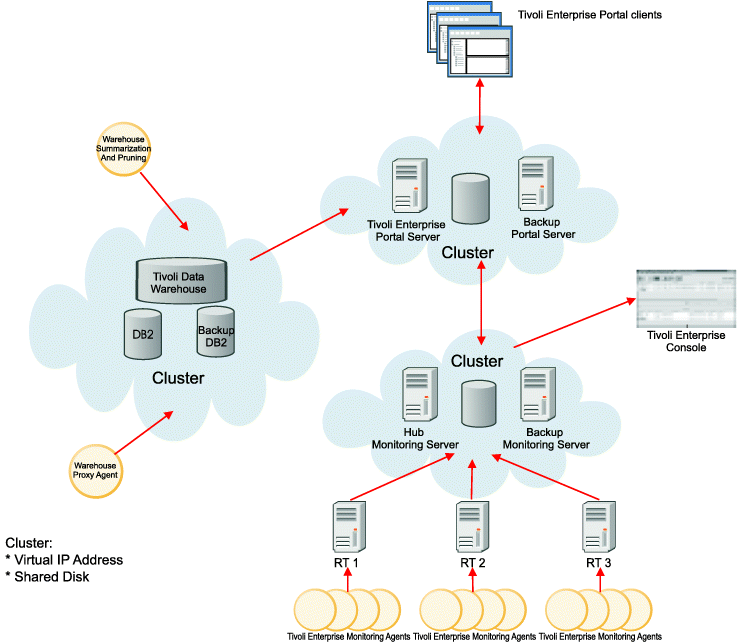
Configuration A
This configuration has a hub cluster, portal server cluster, and data warehouse cluster (including the Summarization and Pruning agent and the Warehouse Proxy), with multiple remote monitoring servers (RT1, RT2, RT3) and agents, and Tivoli Enterprise Console integration.
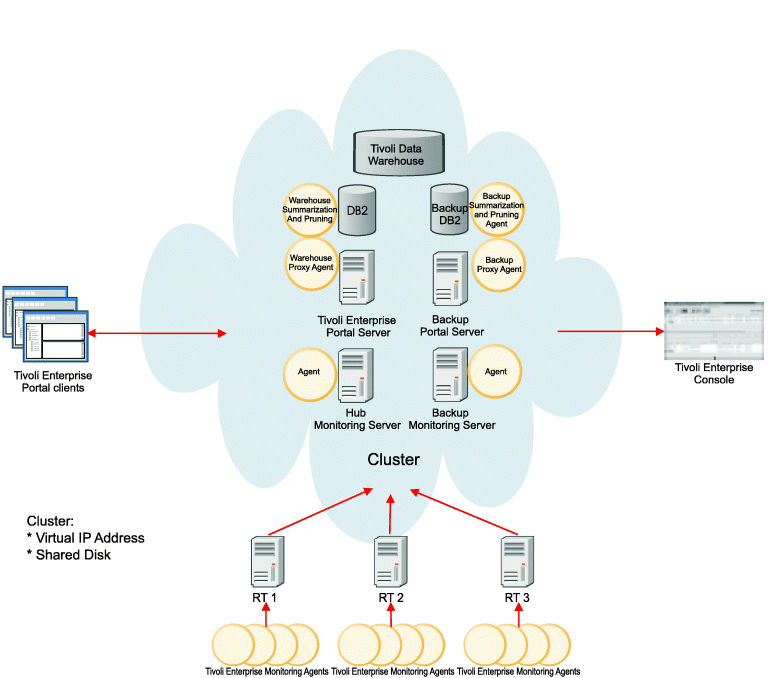
Configuration B
In this configuration, the Warehouse Proxy and Summarization and Pruning agents are running outside of the data warehouse cluster.
Configuration C
In this configuration, all main components are clustered in just one cluster. Also included is one agent running on the clustered environment and directly reporting to the hub, which is not included in the picture for simplification.
This configuration represents a degenerated case of Configuration A. It is important to guarantee that the computers used for such an environment have enough power to handle all the components. The behavior of the clustered components is the same in this case, but the setup of Tivoli Monitoring on such an environment has some differences.
This section describes the overall procedure for setting up Tivoli Monitoring components on clustered environments.
A basic cluster setup includes:
The Tivoli Monitoring requirements for the cluster server are:
Table 10 shows the high-level steps required to set up the main Tivoli Monitoring components running in a cluster.
| Step | Hub monitoring server | Portal Server | Data warehouse |
|---|---|---|---|
| 1 |
Install the database software. Configure the database software for cluster. |
Install the database software. Configure the database software for cluster. |
|
| 2 |
Create the cluster. Define virtual IP and shared persistent storage for the resource group. |
Create the cluster. Define virtual IP, shared persistent storage, and database for the resource group. |
Create the cluster. Define virtual IP, shared persistent storage, and database for the resource group. |
| 3 |
Install and set up the monitoring server on the first node of the cluster. Set up the monitoring server on the second node of cluster. |
Install and set up the portal server on the first node of the cluster. Set up the monitoring server on the second node of cluster. |
Optional: Install and set up the Summarization and Pruning agent and Warehouse Proxy on the first node of the cluster. Set up the Summarization and Pruning agent and Warehouse Proxy on the second node of the cluster. |
| 4 |
Add the monitoring server as a resource to the resource group. |
Add the portal server as a resource to the resource group. |
Optional: Add the Summarization and Pruning agent and Warehouse Proxy as a resource to the resource group. |
Some important characteristics of the Tivoli Monitoring setup on a cluster include:
The monitoring server cluster resources include:
The generic setup of the hub monitoring server on a cluster includes the following task:
Note that the specific setup of the monitoring server varies on different platforms and cluster managers.
By default, the location broker registers all available interfaces for a server. Thus, an internal IP address is configured on each node to be used for cluster internal communication between nodes. However, these internal (private) IP addresses should not be included on a list to be used by other servers or agents. If the Tivoli Enterprise Monitoring Server is installed on an AIX server with a public and a private interface, the Tivoli Enterprise Portal Server cannot connect to the Tivoli Enterprise Monitoring Server. There are two environment variables you can set to control which interfaces to publish. For IPV4 use KDEB_INTERFACELIST, for IPV6 use KDEB_INTERFACELIST_IPV6. In either address family, you can set those variables to set, restrict, or add to the interfaces in use. To avoid communication errors, remove the internal IP address registration, as explained in the following table.
| Interface control | Environment variable |
|---|---|
| To set specific interfaces for consideration: |
KDEB_INTERFACELIST=ip4addr-1 ... ip4addr-n KDEB_INTERFACELIST_IPV6=ip6addr-1 ... ip6addr-n |
| To remove interfaces from consideration: |
KDEB_INTERFACELIST...=-ip4addr-1 ... -ip4addr-n KDEB_INTERFACELIST_IPV6=ip6addr-1 ... ip6addr-n |
| To add interfaces for consideration: |
KDEB_INTERFACELIST=+ ip4addr-1 ... ip4addr-n KDEB_INTERFACELIST_IPV6=+ ip6addr-1 ...ip6addr-n |
where:
Note:
The plus sign must stand alone. |
|
The portal server cluster resources include the following:
The generic setup of the portal server on a cluster includes the following tasks, performed in order:
Note that the setup of the portal server varies on different platforms and cluster managers.
The data warehouse cluster resources include the following:
The generic setup of the data warehouse on a cluster involves the following tasks, performed in order:
The following steps are optional and only necessary if the Summarization and Pruning agent and the Warehouse Proxy are included in the cluster:
The specific setup of the data warehouse on different platforms and cluster managers varies and is described on the specific cluster managers on this series.
In general, the failover or failback of a clustered component is treated by the other Tivoli Monitoring components as a restart of the clustered element.
When the hub is clustered, its failover/failback is perceived by all the other Tivoli Monitoring components as a hub restart. This means that the other components automatically reconnect to the hub and some synchronization takes place.
As part of the remote monitoring server to hub synchronization after re-connection, all situations that are the responsibility of the remote monitoring server (distributed to the monitoring server itself or to one of its connected agents) are restarted. This restarting of situations represents the current behavior for all re-connection cases between remote monitoring servers and the hub, independent of clustered environments. See Situations for more information.
For agents directly connected to the hub, there might be a periods in which situation thresholding activity on the connected agents is not occurring because the situations are stopped when a connection failure to the reporting hub is detected. As soon as the connection is reestablished, the synchronization process takes place and situations are restarted. (Note that historical metric collection is not stopped.)
The portal server, the Summarization and Pruning agent, and the Warehouse Proxy reconnect to the hub and perform any synchronization steps necessary.
The portal user's perception of the apparent hub restart depends on the size of the environment (including the number of agents and situations). Initially you are notified that the portal server has lost contact with the monitoring server, and views might be unavailable. When the portal server reconnects to the hub, the Enterprise default workspace displays, allowing access to the Navigator Physical view. However, some agents may have delays in returning online (due to the reconnection timers) and triggering polled situations again (as the situations are restarted by the agents).
While the hub failover or failback (including the startup of the new hub) may be quick (on the order of 1-3 minutes), the resynchronization of all elements to their normal state may be delayed in large-scale environments with thousands of agents. This behavior is not specific to a cluster environment, but valid any time the hub is restarted or when connections from the other Tivoli Monitoring components to the hub are lost and later re-established.
When the portal server is clustered, its failover or failback is perceived by its connected Tivoli Monitoring components as a portal server restart. The components that connect to the portal server include the portal consoles and the Summarization and Pruning agent (at the start of its summarization and pruning interval).
When a portal client loses connection to the portal server the user is notified and some views become unavailable. When the portal client re-establishes connection with the portal server, the home workspace displays and the Navigator refreshes.
If the Summarization and Pruning agent is connected to the portal server at the time of portal server failover, it loses the connection and attempts to reestablish contact on the next Summarization and Pruning agent interval.
When the data warehouse is clustered, its failover/failback is perceived by its connected Tivoli Monitoring components as a database restart. The components that connect to the data warehouse database include the Summarization and Pruning agent, the Warehouse Proxy and portal server (when retrieving long-term data collection for the portal workspace views).
When the Summarization and Pruning agent loses contact with the data warehouse database, it attempts to reestablish contact on the next Summarization and Pruning agent interval and then restart its work.
When the Warehouse Proxy loses contact with the data warehouse database, it attempts to reestablish the connection and restart its work.
When the portal server loses contact with the data warehouse, it reconnects on the next query request from a portal client.
When the data warehouse cluster resource group includes the clustered Summarization and Pruning agent, the agent fails together with the data warehouse database and must be restarted after the data warehouse. As the Summarization and Pruning agent uses transactions for its operations to the data warehouse database, it resumes its summarization and pruning work where it left off prior to failure.
When the Warehouse Proxy is part of the data warehouse cluster resource group, the proxy fails together with the data warehouse database and must be restarted after the data warehouse. The proxy then resumes the work of uploading the short-term data collection to the data warehouse.
Situations are potentially affected by failures on the hub, the remote monitoring server, and at the agent. During a hub cluster failover, situations are affected in the same way as a restart of the hub or when the hub gets disconnected from the other components.
When a remote monitoring server loses connection with the hub and then reestablishes contact, the server synchronizes after re-connection. This process involves restarting all the situations under that remote monitoring server's responsibility. Polled situations are triggered on the next polling interval, but pure events that were opened before the failure are lost. Use an event management product, such as OMNIbus or Tivoli Enterprise Console, as the focal point for storing and manipulating historical events from all event sources.
If you have agents directly connected to the hub, the situations distributed to them are stopped when connection is lost and the situations are restarted when the agent reconnects to the hub. This behavior also applies for agents that are connected to a remote monitoring server and lose connection to it.
Workflow policies can be set to run at the hub. If the hub fails over while a workflow policy is running, the processing stops and then restarts at the beginning of the workflow policy (upon restart of the hub and triggering).
When a hub failover or failback occurs, any remote monitoring servers and agents reconnect to it, causing all situations to be restarted. Short-term data collection is performed at the agents through special internal situations called UADVISOR. These situations are also restarted and collect data only after the next full interval has passed, resulting in the loss of one collection interval of data.
The Warehouse Proxy and Summarization and Pruning agents connect to the hub. After a hub failover/failback occurrs, the proxy and agent reconnect to it without impacting their work on the data warehouse.
When Tivoli Monitoring is configured to forward events to the Tivoli Enterprise Console event server or a Netcool/OMNIbus Objectserver, its behavior is to send a “MASTER_RESET" event to the event server every time the hub is restarted. This behavior also occurs after failover/failback for a clustered hub. The purpose of this event is to signal to the event server that the monitoring server restarted all its situations and that the event server will receive a new set of currently triggered situations. The default event synchronization rule for Tivoli Monitoring integration addresses that event by closing all the events that came from this hub monitoring server. Although this behavior guarantees that both Tivoli Monitoring and Tivoli Enterprise Console or Netcool/OMNIbus Objectserver have consistent triggered situations and events, the behavior may not be desirable in some environments. For example, this behavior closes pure events that are not reopened until the next pure event occurs. In such cases, you can filter out the MASTER_RESET either at the hub (EIF configuration file) or at the event server by using correlation rules. In this case, the rules must handle duplicate events caused by the restarted situations.
The maintenance requirements of Tivoli Monitoring (patches, fix packs or release upgrades) when running in a cluster resembles those of running an unclustered Tivoli Monitoring environment. The cluster controls the starting and stopping of Tivoli Monitoring services. In order to return this control to the install procedure, you must stop the cluster while the maintenance is being performed. Also, due to current restrictions of the Tivoli Monitoring installation procedures, some settings that are completed during Tivoli Monitoring cluster setup might need to be repeated after the maintenance is completed and before the cluster is restarted.
[ Top of Page | Previous Page | Next Page | Contents | Index ]