Define a cube view data source
The Planning Analytics Workspace process editor lets you define a cube view as a data source from which you can extract data and create or update objects and/or data.
Define a cube view data source in Planning Analytics Workspace
TurboIntegrator processes in Planning Analytics Workspace can use native or MDX views as data sources. You can differentiate a native view from an MDX view by the icon next to the view name in the data tree.
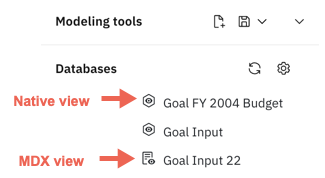
To define a view as a data source:
-
Open the process in the process editor.
-
Click the Data Source tab on the process editor.
-
Click the Data source menu, then click Cube.
-
Click the Cube type menu, then click the type of cube you want to use as a data source: Cube or Control cube.
-
Click the Cube menu (or Control cube menu if that's the type of cube you picked in the previous step), then click the cube you want to use as a data source.
Alternatively, you can begin typing a cube name directly in the Cube box and the editor filters the list of available cubes that match the characters you enter.
-
Click the View menu, then click the specific view that you want to use as a data source.
If there are no views available for the book, or if you want to create a new view or modify an existing view as a data source, click Open view to define view. After the view is saved, it is available in the View menu.Important: If you use a native view as a data source, when you modify the view with Open view and save it back to the server, it saves as an MDX view. Native views transform into MDX views when you open them in Planning Analytics Workspace. This important to note as variable runtime order in MDX views are based on the view and not on the order of dimensions as described in step 7. -
Click Preview to view the variables in your data source.
When you run a process that uses a native view as a data source, the view previews and reads variables in the order that the dimensions are listed on the cube. Any change to the dimensions in the view does not impact the order in which the variables are read.
Alternatively, when you use an MDX view as a data source, the preview and variable runtime order depend on the view and not on the order of dimensions. This enables hierarchy support as the number of hierarchies in an MDX view can be different than the number of dimensions in the cube.
- Click Set variables to initially set variable names and data types based
on a review of the data source.
Assigned variable names generally coincide with the dimension names in the data source. If the variable names that are assigned are not meaningful or familiar to you, you can click a variable name and type a new name. Variable names can contain only letters, numbers, and underscore and must start with a letter.Note: The variable order in an MDX view is Rows, Columns, and then Slicer (all left to right).
It's good practice to give the variables a meaningful name. Having meaningful names makes the process scripts easier to read and troubleshoot.
Similarly, if the data type for any variable is misidentified, you can click the data type and pick a different type (Numeric, String, or Ignore). Choose the Ignore data type if you want the variable to be ignored and just kept as a placeholder.
-
Click Save to save the process.
Define a cube view data source in Planning Analytics Workspace Classic
- Click the Data Source tab on the process editor.
- Click Cube.
- Click the cube that contains the view you want to use as a data source, then click Next.
- Select the view that you want to use as the data source.
If the view you want to use does not exist, click Create view to define a new view.
- Type the New view name.
- Set the skip options:
- Skip zeros
- Turn this option on to ignore zeros or blank values when you extract the view. Turn this option off to include zeros or blank values when you extract the view. The default is on.
- Skip consolidations
- Turn this option on to ignore values derived through consolidation when you extract the view. Turn this option off to include values derived through consolidation when you extract the view. The default is on.
- Skip rule values
- Turn this option on to ignore values derived through rules when you extract the view. Turn this option off to include values derived through rules when you extract the view. The default is on.
- For each dimension in the source cube, pick the hierarchy and the set you want to use in the view.
- Click Create.
- Select the new view that you created.
- Click Load preview.
- Click Load Preview.
The process editor loads several records from the cube view to help you identify the structure of the source data. Each column in the source is assigned a variable name. The data type for each column is identified as either string or numeric.
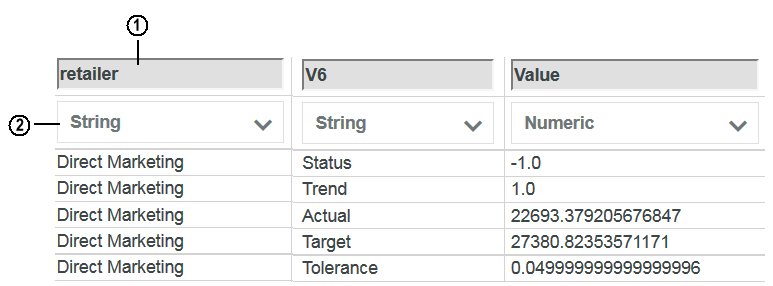
- 1
- variable name
- 2
- data type
Assigned variable names generally coincide with the dimension names in the data source, but can also be a combination of the letter V and a number, such as V1 or V6. If the variable names that are assigned are not meaningful or familiar to you, you can click a variable name and type a new name. Variable names can contain only letters, numbers, and underscore and must start with a letter.
It's good practice to give the variables a meaningful name. Having meaningful names makes the process scripts easier to read and troubleshoot.
Similarly, if the data type for any column is misidentified, you can click the data type and pick a different type.