Big SQL integration with YARN
YARN is the resource management and scheduling framework for Hadoop. Big SQL is better integrated with YARN through Apache Slider, which allows services that are not "job-oriented" (and therefore not natively written for YARN) and "long running" services (for example, HBase) to be deployed on YARN.
Before you begin
- If Big SQL High Availability (HA) is required, then this must be enabled before enabling YARN and Slider for Big SQL.
- YARN integration cannot be enabled while the Big SQL service is being installed.
- Make sure that there is a one-to-one mapping between YARN NodeManager agents and worker nodes:
- Every Big SQL worker node has NodeManager.
- There is no NodeManager without a Big SQL worker node.
- Make sure that there is no NodeManager on the head node or the secondary head node.
- Make sure that the cluster is in a healthy state. Service checks should be fine with no dead nodes and no abnormal conditions within the cluster.
- Make sure that a YARN Service Check returns successfully.
- Make sure that the maximum container size for YARN is greater than or equal to the desired container size for Big SQL.
- Make sure that under the Big SQL service is populated properly. See Big SQL YARN configuration options below.
- If all workers are required to be up and running from configuration time, set the YARN Resources Requested (bigsql_capacity) to 100.
- If you are configuring Big SQL high availability with YARN and Slider, make sure you disable YARN, configure the secondary head node, then finally enable YARN. Otherwise the operation log will report an error stating that you can't enable HA unless you disable YARN.
- Note that there is no extra step required for a Kerberized versus a non-Kerberized environment.
- It is recommended to have a container size of minimum 28GB. Therefore the memory capacity should be such that the YARN memory allocated for all containers on a node (yarn.nodemanager.resource.memory-mb) is at least sufficient to provide for a 28GB Big SQL container and any other containers for other applications (including Big SQL Load and Spark Gateway, if required). For a memory constrained system, the Single Container Per Worker property can be set at , which will enforce a single container only per worker host.
For a set of common questions and answers about YARN integration, see YARN Slider integration FAQ.
For YARN integration troubleshooting information, see Troubleshooting YARN Slider integration.
Enabling YARN
To enable YARN to manage the resources that are assigned to Big SQL, open the Big SQL service in the Ambari dashboard and click . Check the YARN enabled box and restart the Big SQL service. When this option is enabled, the Big SQL Resource Allocation (bigsql_resource_percent) property is ignored and the Big SQL worker nodes are governed by YARN resource and scheduling algorithms. The management nodes are not affected.
Big SQL automatically configures and deploys logical Big SQL workers across the cluster. Each worker host is configured with enough logical Big SQL workers to ensure that all of the hosts’ YARN resources are available to Big SQL. Then each logical Big SQL worker can be assigned the resources of one Big SQL YARN container depending on the percentage of YARN resources allocated for Big SQL and the YARN scheduler. When YARN is enabled, it is important that the systems in a Big SQL cluster have the same memory and CPU capacity.
Big SQL YARN configuration options
Several configuration options are available under .
The number of Big SQL YARN containers that is configured on each Big SQL worker host depends on the amount of memory and CPU that is allocated for YARN, the minimum and maximum YARN container size, and several Big SQL configuration options that you can set under Advanced bigsql-slider-env. The number of Big SQL YARN containers cannot exceed 7 per Big SQL worker host, and the total number of Big SQL YARN containers in the entire cluster cannot exceed 999.
Big SQL container memory specifies the size of each container (the default is 28672 MB), and Big SQL container vcore specifies the number of virtual cores for each container (default is 4). After changing any of these Advanced bigsql-slider-env configuration settings, you are prompted to restart the Big SQL service and to restart YARN.
Because it needs to share resources with other services, Big SQL uses 50% of the YARN resources by default. If no other services are running on the system, or Big SQL intentionally should be given more resources, you can increase the YARN Resources Requested setting under Advanced bigsql-slider-flex. If fewer resources are needed for Big SQL, you can decrease the setting accordingly. To adjust the percentage of YARN resources used by Big SQL, navigate to in Ambari. Adjusting this parameter does not require a Big SQL service restart.
- When YARN is enabled for Big SQL, each node is allotted n containers based on available memory, CPUs, and the percentage of node manager resources that will be requested as containers.
- There is a one-to-one correspondence between a container and a logical worker. For example, if YARN allots five containers, there will be five logical workers running.
- If the Single Container Per Worker checkbox is selected, YARN will allot only one container per Big SQL worker host, so there will effectively be just one logical worker per Big SQL worker host.
Notes
- Because YARN (not Big SQL) is controlling the resources on the cluster, YARN might not always be able to evenly distribute containers across the Big SQL worker nodes. This can lead to container activation skew which, in turn, can impact performance.
- In the event that a node with a Big SQL worker and YARN NodeManager is rebooted for any reason, the Big SQL worker should be started before NodeManager. Other services can be started in any order.
- The percentage entered in the YARN Resources Requested configuration property is not guaranteed to be assigned to Db2 Big SQL. YARN will assign as many containers as it can create for Big SQL, up to the requested percentage of the NodeManager memory and CPU limits. YARN may not fully satisfy the request when the percentage value is extremely high, or when very few resources on the system are free.
Monitoring and verifying configuration
- To check Big SQL status, run the command:
In the output from the$BIGSQL_HOME/bin/bigsql statusbigsql statuscommand, the status column will indicate whether each worker is running or not. The percentage of workers that are running should reflect the value of the YARN Resources Requested (bigsql_capacity) property.Note: When the Slider Resources Requested is adjusted by applying the Apply Slider Flex service action, it can take a brief period for the workers to start, depending on the size of the cluster. - Check the Slider status for the application "bigsql":
slider status bigsql- The output should show the
following:
"liveness" : { "allRequestsSatisfied" : true, "requestOutstanding" : 0, "activeRequests" : 0, "lastAllocationTime : 1502293663915, "availableResource" : { "memory" : 29696, "virtualCores" : 23 } } - The output should also show a list of containers with text
__BIGSQL_WORKERin the names. - The output should contain a list of hosts and host URLs.
- Through the YARN Resource Manager UI, click Running Apps. You should see
the org-apache-slider application running.
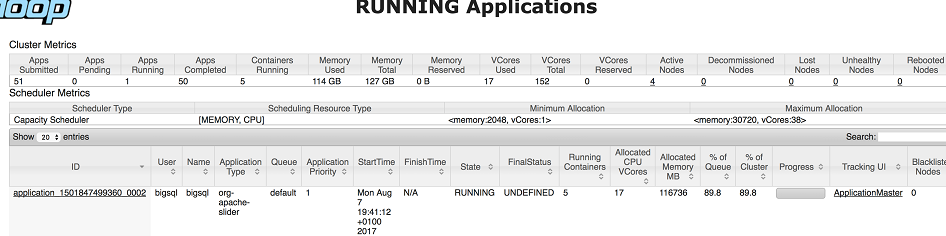
- Click on the application ID to drill down into the application details.
You should see a status dialog as shown below:
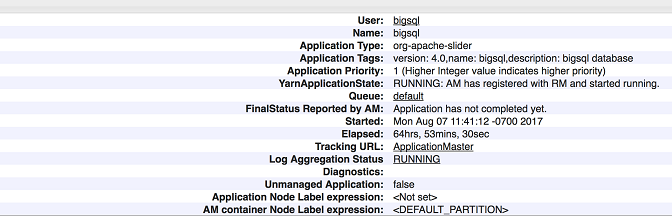
- Click on the Tracking URL ("ApplicationMaster") and
you should see two components listed: BIGSQL_WORKER and
slider-appmaster.

- The output should show the
following: