copyright: years: 2017, 2023 lastupdated: "2023-01-07"
Setting up high availability
You can configure IBM® Voice Gateway to run in a highly available environment by deploying a cluster of voice gateway instances behind a SIP load balancer. By scaling these instances across many nodes (e.g. VMs or servers), the voice gateway can handle enormous call loads.
High availability architecture
Each voice gateway instance is composed of two separate containers, the SIP Orchestrator and the Media Relay. The Voice Gateway can scale itself to fully use as much of the node's available processing capacity as needed, so adding more voice gateway instances on the node, or vertically scaling, does not further increase capacity. Instead, scale your environment horizontally by deploying on multiple nodes or virtual machines (VMs), each containing a single voice gateway instance. In other words, increasing scale is achieved by adding VMs, as opposed to adding more instances per node.
The following diagram shows a typical three-node highly available deployment.
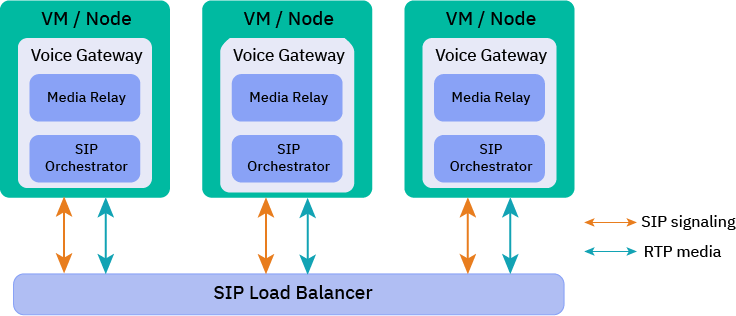
Because of this architecture, the voice gateway does not support session replication or session failover. Each voice gateway instance runs independently from the other voice gateway instances in the cluster. If a failure occurs or an instance of the voice gateway is taken down, any active calls running on the instance are lost. Therefore, it's critical to plan and manage updates to the voice gateway as described in Updating the voice gateway in high availability environments.
If any one node goes down, the active calls on that node fail, but the overall service remains operational. When you plan for capacity, keep in mind that when a node fails, the remaining nodes experience an increased load. Size the number of nodes in your cluster so that it can handle the peak load even if a node is missing.
SIP load balancers
The SIP load balancer is a key component for deploying the IBM Voice Gateway in a highly available environment, with the following key responsibilities:
- Distributing new calls evenly across the cluster
- Maintaining call session affinity, which requires the load balancer to introspect SIP headers in the messages that flow through it and maintain state information about each active call
- Checking the health of the voice gateway instances that it routes calls to
To check the health of voice gateway instances, the load balancer sends SIP OPTIONS messages to each instance. By default, the voice gateway responds to these OPTIONS messages with a 200 OK code if it's healthy. On the CMR_HEALTH_CHECK_FAIL_ERR_CODE environment variable, you can configure the voice gateway to respond to OPTIONS messages with a specific error response. For situations when the voice gateway is temporarily unable to handle new calls but can continue handling existing calls,
such as if it ran out of ports, you can also configure it to stop sending OPTIONS messages. This configuration depends on the capabilities of your SIP load balancer.
Because of its critical role, the SIP load balancer is also a potential single point of failure. Typically, SIP load balancers provide deployment models for handling failure conditions. For information about configuring high availability for your particular SIP load balancer, see its documentation.
Updating the voice gateway in high availability environments
When the time comes to update IBM Voice Gateway, you'll want to transition to the new version in a way that does not disrupt ongoing calls. Most SIP load balancers support the concept of a routing table, which contains all the routable back-end SIP nodes. SIP load balancers also typically support the ability to manually add and remove nodes from this routing table.
When a node is removed from the routing table for new calls, the SIP load balancer continues to route messages associated with existing active calls to the removed node as long as it continues to respond to health check messages. Using this capability, you can fully quiesce a voice gateway instance that you want to update of all its active calls before the SIP Orchestrator and Media Relay containers are removed. You can then restart them with the new images.
When the container goes down, the Kubernetes preStop lifecycle hook is activated. The preStop lifecycle hook sends a request to put the pod in quiesce mode. While in quiesce, the server stops responding or rejects
OPTIONS requests. The preStop lifecycle hook checks periodically to determine if there are any active calls on the server.
The CMR_HEALTH_CHECK_FAIL_ERR_CODE environment variable defines how the server responds to SIP OPTIONS requests. When the server does not respond, or rejects the OPTIONS request, a load balancer in front of the Voice Gateway
server does not forward new calls to the server. Existing calls are not impacted and continue until the server shuts down.
The preStop hook exists either when there are no active calls or when the timeout expires, and periodically checks to determine if there are any active calls on the server. The timeout determines the length of time to wait for
the server to shut down gracefully and is set to 10 minutes by default. You can customize the grace period setting, terminationGracePeriodSeconds, at the PodSpec level. When the timeout expires, the server goes
down and all active calls end.
After restarting a Voice Gateway instance, you can configure the SIP load balancer to test the new node by routing to it only INVITE requests from a specific device, such as a specific phone number that you control. After you test the new node, it can be added to the production routing table, at which point it starts to receive new inbound INVITE requests. Each node in the cluster must be tested individually.
Container orchestration frameworks
When you move from a single test instance of Voice Gateway to a highly available cluster, consider working with a container orchestration framework such as Kubernetes/OpenShift which simplifies managing containers across multiple nodes.
IBM Voice Gateway has been extensively tested with Kubernetes and IBM Cloud Pak for Data. You can configure these frameworks to provide the capabilities that support a highly available deployment of the voice gateway.
Real-time communication applications such as IBM Voice Gateway have unique functional requirements that must be considered when you choose a Docker orchestration framework.
- Large port ranges are needed for media
- Media ports must accessible by other network devices, such as a session border controller (SBC) outside the overlay network
- SIP session affinity must be over UDP
- SIP calls from a container must be quiesced when the container is shut down
Important: Because of limitations in the Docker Swarm ingress load balancer, Docker Swarm does not work with IBM Voice Gateway.
Kubernetes deployments
In Kubernetes terminology, a single voice gateway instance equates to a single pod, which contains both a SIP Orchestrator container and a Media Relay container. The voice gateway pods are installed into a Kubernetes cluster that is fronted by an external SIP load balancer. Through Kubernetes, a voice gateway pod can be scheduled to run on a cluster of VMs. The framework also monitors pods and can be configured to automatically restart a voice gateway pod if a failure is detected.
Note: Because auto-scaling and auto-discovery of new pods by a SIP load balancer in Kubernetes are not currently supported, an external SIP load balancer's routing tables must be manually updated when a new pod is added to a Kubernetes cluster, as discussed in the following section.
Configuring high availability
This section focuses on deploying the IBM Voice Gateway into a Kubernetes environment for high availability. Although you're not required to use Kubernetes and can simply deploy a cluster of voice gateway instances on a set of independent Docker-enabled nodes, you lose the ability to manage the entire cluster from a central location. See Deploying Voice Gateway on Kubernetes.