Configuring memory and CPU options
Complete this task to configure the memory and CPU options for Apache Spark.
About this task
Apache Spark is designed to consume a large amount of CPU and memory resources in order to achieve high performance. Therefore, it is essential to carefully configure the Spark resource settings, especially those for CPU and memory consumption, so that Spark applications can achieve maximum performance without adversely impacting other workloads.
Setting the memory and CPU options for your Spark workload can be an ongoing task. It is good practice to regularly monitor the actual resource consumption and identify potential bottlenecks by using the variety of monitoring tools described in Resource monitoring for Apache Spark. After obtaining performance measurements, you can fine tune your Spark workload.
For a quick reference to various Spark and z/OS® system configuration options that you might wish to consider when tuning your environment for Open Data Analytics for z/OS, see Memory and CPU configuration options.
Procedure
-
Determine the system resources that Spark needs.
Before you modify the memory and CPU settings for your Spark cluster, determine an amount of resources to give to your Spark workload. For a detailed discussion about sizing Spark workloads, see Resource Tuning Recommendations for IBM z/OS Platform for Apache Spark.
-
Determine the amount of memory and processor that your Spark cluster is allowed to
use.
When assessing the amount of memory to allot for Apache Spark, consider the following parameters:
- The amount of physical memory available on the system. Workloads perform best with minimal paging.
- The amount of memory required by other (possibly more important) subsystems, such as Db2.
- The amount of memory required by supporting software that interacts with Apache Spark, such as z/OS IzODA Mainframe Data Service (MDS).
- Other work that might run at the same time as Apache Spark.
Guidelines:- IBM suggests that you start with at least
6 GB of memory for the Spark cluster, not including MDS. If you have installed
WLM APAR OA52611 and you use WLM to manage your Spark workload, you can also cap the
amount of physical memory that the Spark cluster can use to avoid
impacting other workloads. Table 1 lists
the suggested initial memory sizes for the components in a Spark cluster.
Table 1. Suggested initial memory sizing for a Spark cluster Component Default size Suggested initial size Spark master 1 GB 1 GB Spark worker 1 GB 1 GB Spark driver 1 GB 2 GB Spark executor 1 GB 2 GB Total 4 GB 6 GB - Spark workloads are zIIP-eligible. If you have installed WLM APAR OA52611 and you use WLM to manage your Spark workload, you can use the honor priority attribute to minimize the amount of Spark work that is processed by the general processors (GPs). IBM suggests that you start with at least two zIIPs and one GP.
For more information about using the metering and capping functions provided by WLM APAR OA52611 for your Spark workload, see Configuring z/OS workload management for Apache Spark.
-
Determine how many concurrent Spark applications your Spark cluster must support.
This depends on your business requirements, the amount of resources available on your system, and the application requirements.Alternatively, you can run multiple Spark clusters instead of configuring a single Spark cluster for multiple applications. This can be beneficial in the following cases:
- You have applications with different workload priorities (for instance, production vs. development). Although you can configure a single cluster that supports multiple applications, separate clusters might simplify the configuration and administration of each cluster as priority requirements change.
- You need to isolate workloads for security reasons or because of the nature of the data being analyzed.
If you do run multiple Spark clusters on the same z/OS system, be sure that the amount of CPU and memory resources assigned to each cluster is a percentage of the total system resources. Over-committing system resources can adversely impact performance on the Spark workloads and other workloads on the system.
-
For each Spark
application, determine the amount of executor heap that it requires.
An executor heap is roughly divided into two areas: data caching area (also called storage memory) and shuffle work area. In Spark 1.5.2 with default settings, 54 percent of the heap is reserved for data caching and 16 percent for shuffle (the rest is for other use). In Spark 2.0.2 and higher, instead of partitioning a fixed percentage, it uses the heap for each area, as needed. To properly estimate the size of the executor heap, consider both the data caching and shuffle areas.
To achieve optimal results, it is best to cache all of the data that Spark needs in memory to avoid costly disk I/O. When raw data is encapsulated in a Java object, the object is often larger than the size of the data that it holds. This expansion factor is a key element to consider when projecting how large the data cache should be. Ideally, the expansion factor is measured by persisting sample data to an RDD or DataFrame and using the Storage tab on the application web UI to find the in-memory size. When it is not possible to measure the actual expansion factor for a set of data, choosing a value from 2x to 5x of the raw data size for RDDs, and 1x to 2x of the raw data size for DataFrames should provide a reasonable estimate. Without considering the shuffle work area, you can determine the preliminary heap size using the equations:
in-memory data size = raw data size × estimated or measured expansion factor
executor heap = in-memory data size ÷ fraction of heap reserved for cache
The amount of memory needed for the shuffle work area depends entirely on the application. Shuffling happens when the application issues operations like groupByKey that requires data to be transferred. When the amount of shuffle memory is not adequate for the required shuffle operations, Spark spills the excess data to disk, which has a negative impact on performance. You can find occurrences and amounts of shuffle spills executor stderr log file, such as in the following example:INFO ExternalSorter: Thread 106 spilling in-memory map of 824.3 MB to disk (1 time so far) INFO ExternalSorter: Thread 102 spilling in-memory map of 824.3 MB to disk (1 time so far) INFO ExternalSorter: Thread 116 spilling in-memory map of 824.3 MB to disk (1 time so far)For more information about Spark memory management settings, see "Memory Management" in http://spark.apache.org/docs/2.4.8/configuration.html.
-
Determine the number of executors for each application.
To do this, consider the following points:
- There is some startup cost associated with initializing a new Java virtual machine. Each executor runs within its own JVM, so the total overhead associated with JVM startup increases with each additional executor.
- Garbage collection (GC) costs are generally higher for large heaps. IBM Java can typically run with up to 100 GB heap with little GC overhead. If your application requires larger heap space, consider using multiple executors with smaller heaps. You can use the Spark application web UI to monitor the time spent in garbage collection.
- Efficient Spark applications are written to allow a high degree of parallelism. The use of multiple executors can help avoid the contention that can occur when too many threads execute in parallel within the same JVM.
- There is increased overhead when multiple executors need to transfer data to each other.
-
For each Spark
application, determine the size of the driver JVM heap. This only applies if your driver runs on a
z/OS system.
The driver heap should be large enough to hold the application results returned from the executors. Applications that use actions like
collectortaketo get back a sizable amount of data may require large driver heaps. If the returned data exceeds the size of the driver heap, the driver JVM fails with an out-of-memory error. You can use thespark.driver.memoryandspark.driver.maxResultSizeSpark properties to tune the driver heap size and the maximum size of the result set returned to the driver.The driver process can either run on behalf of the user invoking the Spark application, inheriting the user's z/OS resource limits (client deploy mode), or it can use the backend cluster resources (cluster deploy mode). Generally, application developers tend to use client deploy mode while building their applications (for instance, using Jupyter notebooks or interactive spark-shell). Then, production-ready applications are submitted in cluster deploy mode.
If the Spark driver runs in cluster deploy mode, the driver is considered part of the cluster; therefore, the resources it uses (such as
spark.driver.memory) are taken from the total amount allotted for the Spark cluster.
-
Determine the amount of memory and processor that your Spark cluster is allowed to
use.
-
Update the Spark
resource settings.
After you determine the resource requirements for your Spark workload, you can change the Spark settings and system settings to accommodate them.
Note: Applications can override almost all of the settings in the spark-defaults.conf file. However, it is good practice to set them in the configuration file or in the command line options, and not within the applications. Setting them in applications could cause applications to fail because of conflicts with system-level limits or because of system resource changes.Figure 1 shows a sample Spark cluster with various settings that are described later in this topic. The figure shows the Spark resource settings, their defaults (in parentheses) and their scopes (within the dashed lines). z/OS constraints, such as address space size (ASSIZEMAX) and amount of storage above the 2-gigabyte bar (MEMLIMIT) apply to these processes, as usual.
Figure 1. Sample Spark cluster in client deploy mode 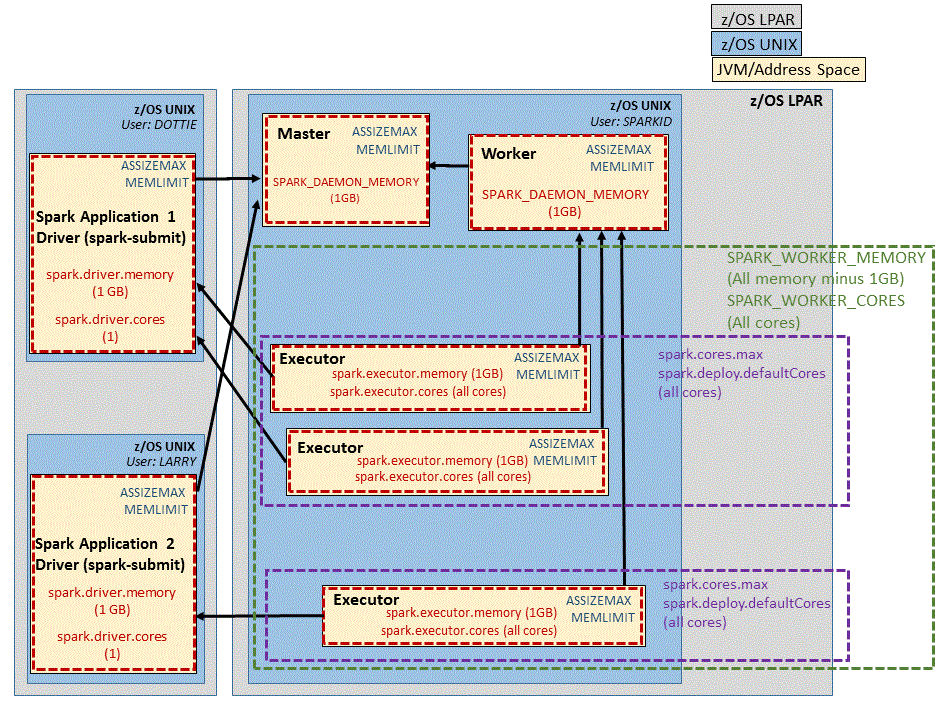
-
Set the number of processors and amount of memory that a Spark cluster can use by setting the
following environment variables in the spark-env.sh file:
- SPARK_WORKER_CORES
- Sets the number of CPU cores that the Spark applications can use. The default is all cores on the host z/OS system. Note that Spark sees each zIIP that is enabled for simultaneous multithreading (SMT) as having two cores.
- SPARK_WORKER_MEMORY
- Sets the amount of virtual memory that Spark applications can use. The default is the total system memory, minus 1 GB.
Both settings apply to the amount of resources that the executors and cluster-deploy-mode drivers can use. They do not include the resources used by the master and worker daemons because the daemons do not process data for the applications.
-
Set the number of cores that a Spark application (including its
executors and cluster-deploy-mode drivers) can use by setting the following properties in the
spark-defaults.conf file:
- spark.deploy.defaultCores
- Sets the default number of cores to give to an application if
spark.cores.maxis not set. The default is all the cores on the system. - spark.cores.max
- Sets the maximum number of cores to give to an application. The default is to use the
spark.deploy.defaultCoresvalue.
-
Set the number of concurrent applications that a Spark cluster can support.
This number is controlled by the amount of resources allotted to the Spark cluster and how much can be used by each application.
Assuming there is enough memory, the number of concurrent applications that a Spark cluster can support is expressed by the following equation:
SPARK_WORKER_CORES ÷
spark.cores.max(orspark.deploy.defaultCores)Example: If you setSPARK_WORKER_CORES=15andspark.cores.max=5, the Spark cluster can allow up to 15 ÷ 5 = 3 applications to run concurrently, assuming there is enough memory for all of them.There is no Spark setting that controls the amount of memory that each application can use. To ensure that the Spark cluster can support the desired number of concurrent applications, set SPARK_WORKER_MEMORY to an appropriate value. See step 2.g for more information.
-
Set the amount of resources that each executor can use by setting the following properties in
the spark-defaults.conf file:
- spark.executor.cores
- Sets the number of cores that each executor can use. The default is all CPU cores on the system.
- spark.executor.memory
- Sets the amount of memory that each executor can use. The default is 1 GB.
-
Set the amount of resources that each driver can use by setting the following properties in the
spark-defaults.conf file:
- spark.driver.cores
- Sets the number of cores that each driver can use. The default is
1. - spark.driver.memory
- Sets the amount of memory that each driver can use. The default is 1 GB.
- spark.driver.maxResultSize
- Sets a limit on the total size of serialized results of all partitions for each Spark action (such as
collect). Jobs will fail if the size of the results exceeds this limit; however, a high limit can cause out-of-memory errors in the driver. the default is 1 GB.
-
Set the number of executors for each Spark application.
This number depends on the amount of resources allotted to the application, and the resource requirements of the executor and driver (if running in cluster deploy mode).
As discussed earlier, you can use
spark.cores.max(orspark.deploy.defaultCores) to set the number of cores that an application can use. Assuming there is enough memory, the number of executors that Spark will spawn for each application is expressed by the following equation:(
spark.cores.max(orspark.deploy.defaultCores) −spark.driver.cores(if in cluster deploy mode)) ÷spark.executor.coresExample: If you setspark.cores.max=5,spark.driver.cores=1, andspark.executor.cores=2and run in cluster deploy mode, the Spark worker spawns (5 − 1) ÷ 2 = 2 executors. -
Use the following set of equations to determine a proper setting for
SPARK_WORKER_MEMORY to ensure that there is enough memory for all of the
executors and drivers:
executor_per_app = (
spark.cores.max(orspark.deploy.defaultCores) −spark.driver.cores(if in cluster deploy mode)) ÷spark.executor.coresapp_per_cluster = SPARK_WORKER_CORES ÷
spark.cores.max(orspark.deploy.defaultCores)SPARK_WORKER_MEMORY ≥ (
spark.executor.memory× executor_per_app × app_per_cluster) +spark.driver.memory(if in cluster deploy mode) -
Set the amount of memory to allocate to each daemon-like process—specifically, the master,
worker, and the optional history server— by setting the SPARK_DAEMON_MEMORY
environment variable in the spark-env.sh file.
The default is 1 GB and is satisfactory for most workloads.
There is no corresponding processor setting for the Spark daemon processes.
-
Set the number of processors and amount of memory that a Spark cluster can use by setting the
following environment variables in the spark-env.sh file:
-
Update system resource settings.
In addition to the Spark settings, there are system-level settings that are required or recommended for your Spark workload to function properly and efficiently.
Continue by determining and setting values for the system-level settings shown in Figure 1.
-
Set
_BPX_SHAREAS=NO.The worker process spawns the executor processes. If the _BPX_SHAREAS environment variable is set to YES, the new executor process runs in the same address space as its parent. If _BPX_SHAREAS is set to NO, the executor runs in its own address space. Because executor processes typically consume a large amount of system resources, IBM suggests that you set
_BPX_SHAREAS=NOfor easier resource management and isolation, and to increase available resources for the executor. -
Set the MEMLIMIT value.
z/OS uses the MEMLIMIT setting to control the amount of 64-bit virtual memory that an address space can use. For the user ID that starts the Spark cluster, the MEMLIMIT value must be set to the largest JVM heap size (typically,
spark.executor.memory) plus the amount of native memory needed. For the user ID that submits the application to the cluster, the MEMLIMIT must be set tospark.driver.memoryplus the amount of native memory needed. The required amount of native memory varies by application. 1 GB is typically needed if the JVM heap size is less than 16 GB and 2 GB is typically needed if the JVM heap size is greater than 16 GB.Spark has the ability to use off-heap memory, which is configured through the
spark.memory.offHeap.enabledSpark property and is disabled by default. If you enable off-heap memory, the MEMLIMIT value must also account for the amount of off-heap memory that you set through thespark.memory.offHeap.sizeproperty in the spark-defaults.conf file.If you run Spark in local mode, the MEMLIMIT needs to be higher as all the components run in the same JVM; 6 GB should be a sufficient minimum value for local mode.
You can set the MEMLIMIT value in any of the following ways:- Recommended: Set the MEMLIMIT value in the OMVS segment of the security profile for the user ID that you use to start Spark. For instance, you can use the RACF® ALTUSER command to set the MEMLIMIT for a user ID. For more information about the ALTUSER command, see "ALTUSER (Alter user profile)" in z/OS Security Server RACF Command Language Reference.
- Specify the MEMLIMIT parameter on the JCL JOB or EXEC statement, which overrides the MEMLIMIT value in the user's security profile, if you start your Spark cluster from z/OS batch. For more information, see "MEMLIMIT parameter" in z/OS MVS JCL Reference.
- Use the IEFUSI exit, which overrides all of the other MEMLIMIT settings. Therefore, if you use the IEFUSI exit, be sure to make exceptions for Spark jobs. For more information, see "IEFUSI - Step Initiation Exit" in z/OS MVS Installation Exits.
- Set the system default in the SMFPRMxx member of parmlib. The system default is used if no MEMLIMIT value has been set elsewhere. The default value is 2 GB. You can use the DISPLAY SMF,O operator command to display the current settings. For more information, see "SMFPRMxx (system management facilities (SMF) parameters)" in z/OS MVS Initialization and Tuning Reference.
To check the MEMLIMIT setting for a specific user ID, you can issue the ulimit command in the z/OS UNIX shell while logged in with that user ID. The following example shows the command response:/bin/ulimit -a core file 8192b cpu time unlimited data size unlimited file size unlimited stack size unlimited file descriptors 1500 address space unlimited memory above bar 16384m -
Ensure that the settings in your BPXPRMxx parmlib, especially the MAXASSIZE
parameter, meet the suggested minimums for Java.
For the suggested minimum values, see Working with BPXPRM settings in IBM SDK, Java Technology Edition z/OS User Guide. For more information about the BPXPRMxx member, see "BPXPRMxx (z/OS UNIX System Services parameters)" in z/OS MVS Initialization and Tuning Reference.
You can set some of these parameters at the user ID level, such as the maximum address space size (the ASSIZEMAX value in the OMVS segment of the security profile for the user ID), by using the RACF ALTUSER command. For more information about the ALTUSER command, see "ALTUSER (Alter user profile)" in z/OS Security Server RACF Command Language Reference.
-
Ensure that you have enough extended common service area (ECSA) and extended system queue area
(ESQA) memory configured on your system to account for Spark usage.
For instance, Spark memory-maps large files to improve performance. However, the use of memory map services can consume a large amount of ESQA memory. For more information, see "Evaluating virtual memory needs" in z/OS UNIX System Services Planning.
You can use the RMF reports to monitor the ECSA and ESQA usage by your Spark cluster. For more information, see Resource monitoring for Apache Spark.
- Consider using z/OS workload management (WLM) to manage Spark workload. With WLM, you define performance goals and assign a business importance to each goal. The system then decides how much resource, such as CPU or memory, to give to a workload to meet the goal. WLM constantly monitors the system and adapts processing to meet the goals. You can also use WLM to cap the maximum amount of CPU time and physical memory used by Spark. For more information, see Configuring z/OS workload management for Apache Spark.
- Consider using simultaneous multithreading (SMT) to improve throughput. Beginning with IBM z13®, you can enable SMT on zIIPs. Open Data Analytics for z/OS is zIIP-eligible and might benefit from SMT. When executing on a system configured with sufficient zIIP capacity, the benchmarks demonstrated in Resource Tuning Recommendations for IBM z/OS Platform for Apache Spark showed throughput improvements of 15 to 20 percent when SMT was enabled.
-
Ensure that the system has enough large pages to accommodate all requests.
When available, 1M pageable large pages are the default size for the object heap and code cache for Java on z/OS. Large pages provide performance improvements to applications such as Spark that allocate a large amount of memory. The use of 1M pageable large pages requires IBM zEnterprise EC12, or later, with the Flash Express feature (#0402).
When the system's supply of pageable 1M pages is depleted, available 1M pages from the LFAREA are used to back pageable 1M pages. Adjust your LFAREA to account for the Spark JVMs. You can set the size of the LFAREA in the IEASYSxx member of parmlib.
For more information about configuring large pages for Java, see Configuring large page memory allocation. For more information about the IEASYSxx parmlib member, see "IEASYSxx (system parameter list)" in z/OS MVS Initialization and Tuning Reference.
-
Set
What to do next
When you have completed configuring memory and CPU options, continue with Configuring z/OS workload management for Apache Spark.