Overview of WLM classification
You specify goals for the WLM services for Open Data Analytics for z/OS® work in the same manner as for other z/OS workloads, by associating the work with a service class. In the service class, you assign goals to the work, along with the relative importance of each goal. You can also assign limits for CPU and memory capacity to be available to a service class. To associate incoming work with a particular service class, you must also define classification rules.
Example of a WLM classification scenario
Figure 1 shows a logical view of a the WLM configuration for a sample classification scenario.
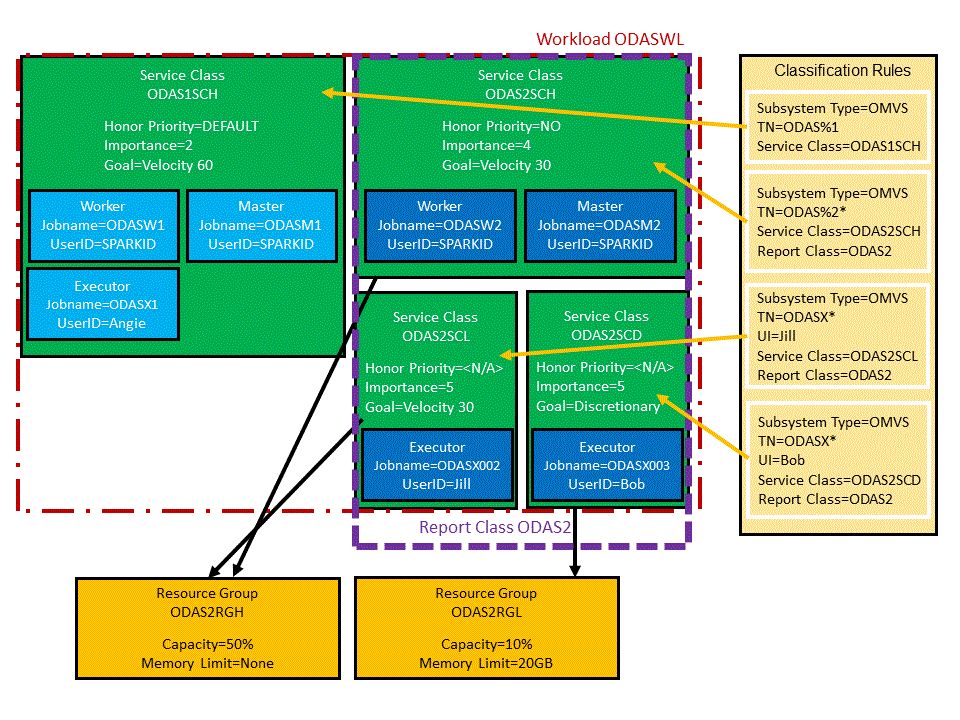
- The ODAS2SCH and ODAS2SCL service classes are associated with the ODAS2RGH resource group, which allows 50 percent GP capacity and has no memory limit.
- The ODAS2SCD service class is associated with the ODAS2RGL resource group, which allows only 10 percent GP capacity and has a memory limit of 20 GB.
- All processes in Spark
cluster 1, whose names match the
ODAS%1*pattern, are classified into the ODAS1SCH service class. User Angie's executor receives its job name by using the _BPX_JOBNAME environment variable. - Master and worker processes in Spark cluster 2, whose names match
the
ODAS%2*pattern, are classified into the ODAS2SCH service class. - The executor for user Jill in Spark cluster 2 has a job name of
ODASX002and is classified into the ODAS2SCL service class. The job name is generated by specifying thespark.zos.executor.jobname.prefixproperty. - The executor for user Bob in Spark cluster 2 has a job name of
ODASX003and is classified into the ODAS2SCD service class. The job name is generated by specifying thespark.zos.executor.jobname.prefixproperty.
All service classes in Spark cluster 2 (ODAS2SCH, ODAS2SCL, and ODAS2SCD) are grouped together into the ODAS2 report class. Further, the ODASWL workload groups both Spark clusters together.
The topics that follow discuss each of these WLM components in more detail.