Big data and analytics support
Analytics is defined as the discovery and communication of meaningful patterns in data. Big data analytics is the use of advanced analytic techniques against very large, diverse data sets (structured or unstructured) which can be processed through streaming or batch. Big data is a term applied to data sets whose size or type is beyond the ability of traditional data processing to capture, manage, and process the data.
Analyzing big data allows analysts, researchers, and business users to make better and faster decisions using data that was previously inaccessible or unusable. Using advanced analytics techniques such as text analytics, machine learning, predictive analytics, data mining, statistics, and natural language processing, businesses can analyze previously untapped data sources independent or together with their existing enterprise data to gain new insights resulting in significantly better and faster decisions.
IBM Storage Scale is an enterprise class software-defined storage for high performance, large scale workloads on-premises or in the cloud with flash, disk, tape, local, and remote storage in its storage portfolio. IBM Storage Scale unifies data silos, including those across multiple geographies and around the globe using Active File Management (AFM) to help ensure that data is always available in the right place at the right time with synchronous and asynchronous disaster recovery (AFM DR).
IBM Storage Scale is used for diverse workloads across every industry to deliver performance, reliability, and availability of data which are essential to the business.
This scale-out storage solution provides file, object and integrated data analytics for:
- Compute clusters (technical computing)
- Big data and analytics
- Hadoop Distributed File System (HDFS)
- Private cloud
- Content repositories
- Simplified data management and integrated information lifecycle management (ILM)
IBM Storage Scale enables you to build a data ocean solution to eliminate silos, improve infrastructure utilization, and automate data migration to the best location or tier of storage anywhere in the world to help lower latency, improve performance or cut costs. You can start small with just a few commodity servers fronting commodity storage devices and then grow to a data lake architecture or even an ocean of data. IBM Storage Scale is a proven solution in some of the most demanding environments with massive storage capacity under a single global namespace. Furthermore, your data ocean can store either files or objects and you can run analytics on the data in-place, which means that there is no need to copy the data to run your jobs. This design to provide anytime, anywhere access to data, enables files and objects to be managed together with standardized interfaces such as POSIX, OpenStack Swift, NFS, SMB/CIFS, and extended S3 API interfaces, delivering a true data without borders capability for your environments.
Decision making is a critical function in any enterprise. The decision-making process that is enhanced by analytics can be described as consuming and collecting data, detecting relationships and patterns, applying sophisticated analysis techniques, reporting, and automation of the follow-on action. The IT system that supports decision making is composed of the traditional "systems of record" and “systems of engagement” and IBM Storage Scale brings all the diverse data types of structured and unstructured data seamlessly to create a “systems of insight” for enterprise systems.
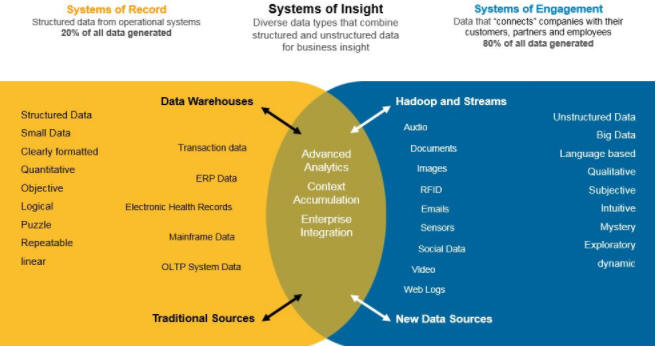
Evolving alongside Big Data Analytics, IBM Storage Scale can improve time to insight by supporting Hadoop and non-Hadoop application data sharing. Avoiding data replication and movement can reduce costs, simplify workflows, and add enterprise features to business-critical data repositories. Big Data Analytics on IBM Storage Scale can help reduce costs and increase security with data tiering, encryption, and support across multiple geographies.