Application server clustering
An application server runs your Java™ Platform, Enterprise Edition (Java EE) applications and can be stand-alone or managed. If you use IBM® WebSphere® Application Server Network Deployment, you can cluster your application servers to run the same set of Java EE applications and participate in workload management.
Clusters enable enterprise applications to scale beyond the amount of throughput capable of being achieved with a single application server. Clusters also enable enterprise applications to be highly available because requests are automatically routed to the running servers in the event of a failure. The servers that are members of a cluster can be on different host computers. In contrast, servers that are part of the same node must be located on the same host computer. Clustering is done in a cell that contains a deployment manager and one or more nodes that are managed by the deployment manager. A cell can include one or more clusters.
In a WebSphere Application Server Network Deployment clustered topology, IBM InfoSphere® Information Server deploys the services tier applications in each application server. When a member of the cluster fails, other cluster members continue to provide services. Components in other tiers communicate with the cluster, not directly with a specific application server in the cluster. As long as at least one member of the cluster is operational, there is no interruption in service.
Implementing an IBM WebSphere Application Server Network Deployment cluster improves concurrency. Concurrency is the number of clients that can use the system simultaneously with a reasonable level of system responsiveness. You can scale a clustered configuration in order to meet increased concurrency requirements.
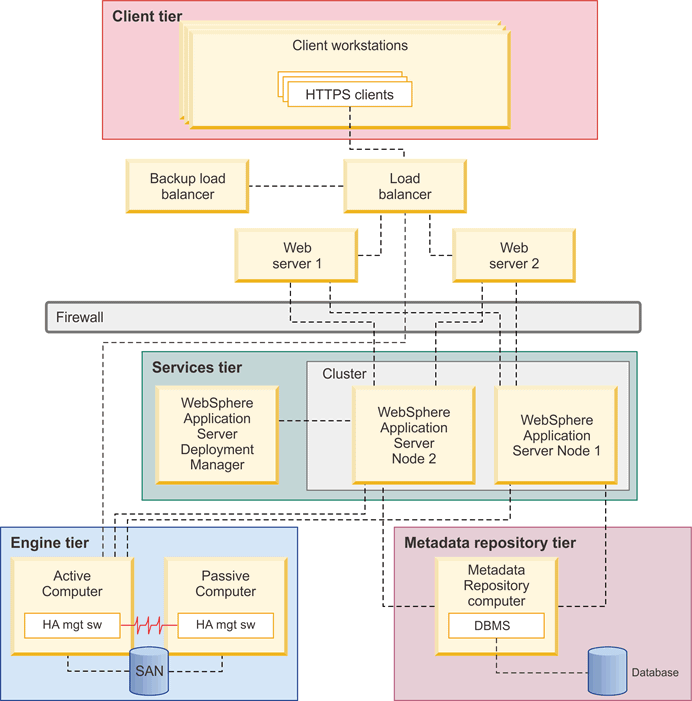
The following diagram shows a topology with a services tier where application server clustering is implemented across two computers. A third computer hosts the WebSphere Application Server Deployment Manager. In the diagram, the engine tier is still set up in an active-passive configuration. The metadata repository tier is located on a separate computer.
This topology includes a sophisticated front-end configuration that includes dual web servers and a load balancer. These systems are set up outside the firewall. HTTP clients such as the WebSphere Application Server web console access the server-side components through the load balancer. A backup load balancer ensures that the load balancer computer is not a single point of failure.