Typical Kafka deployment topology
A typical Kafka cluster is configured to have multiple server nodes to handle scalability, backup, and failover. In the batch stream scenario, your deployment will also require a database connector and stream processors.
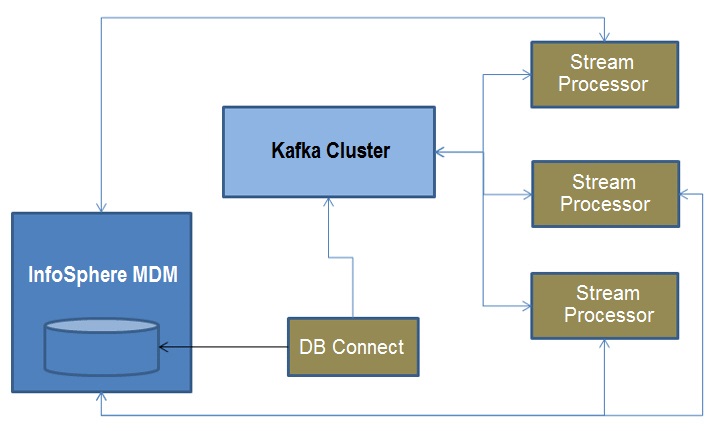
As a best practice, you should have only one database connector and multiple batch or runtime stream processors running on either the same Java virtual machine (JVM) or multiple JVMs.
Threads in each stream processor can be configured to scale up to match the number of partitions in the Kafka cluster. When you have reached the upper thread limit for an individual stream processor, then you can choose to add another stream processor and another JVM to scale up to match the number of partitions in the Kafka cluster.