Using VM snapshots for infrastructure backup and disaster recovery
You can use VM snapshots to backup and restore the infrastructure used by API Connect on VMware, and also for infrastructure disaster recovery.
Backup and restore procedures for the databases used by IBM API Connect on VMware are described in Backing up and restoring on VMware. The procedures back up all of the state required by API Connect but do not include the underlying infrastructure software or other internal state.
In some scenarios, you may want to perform backups and disaster recovery at an infrastructure layer. You can do this by taking snapshots of the virtual machines or underlying storage volumes, providing that you follow the constraints described here.
Note that performing backups at the infrastructure layer differs from the standard approach in that not only is the database state backed up, but also the precise state of the software. This approach can be useful, for example, when testing upgrades of production systems.
VM snapshots should not be used as an alternative to taking normal backups. Ideal times to take VM snapshots are after initial install and configuration, and before and after upgrades. In the event of a disaster, reverting to the last snapshot taken and then restoring the standard daily backup can be faster than redeploying OVAs and restoring the backup.
- Requirements for taking a consistent backup of an API connect system at the infrastructure
level
- An API Connect system can be approximated by the following diagram:
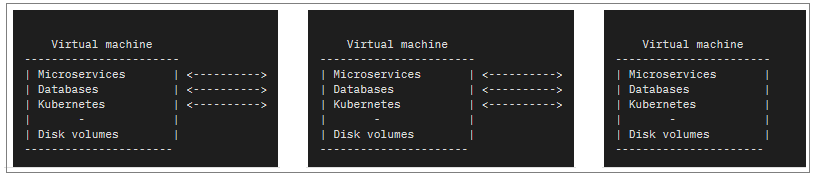
- The system comprises multiple Virtual Machine images which are running Kubernetes, multiple databases, with the API Connect micro services running on top. There is transactional communication between the virtual machines which is occurring at all levels of this stack. This communication occurs all the time, even if the system is seemingly idle.
-
Within the system there are multiple stateful or database layers on the software that maintain a consistency protocol. For example
etcdupon which Kubernetes is based uses the Raft consensus algorithm. These algorithms depend for consistency on the basic assertion that time flows forwards on all systems together. If one or more of the virtual machine’s state where to move backwards relative to the others by even the smallest quantum of time then consistency would be lost and the system might behave badly.Clearly, if Virtual Machine snapshots are taken across multiple virtual machines it is certain that these snapshots will not be taken at precisely the same time. The result will be a backup that contains a system state that contains data from snapshots taken at slightly different times. It is possible that such a backup system may be restored and may appear to work correctly but hidden deep within it there may be undetected inconsistencies that will cause strange unpredictable errors and inconsistencies later. These issues can be extremely difficult to diagnose.
It is also possible that you can test this procedure successfully multiple times and see no apparent problem occurring. Irrespective of the apparent success of tests, corruption can be occurring in the system state. For this reason, taking VM snapshots or clones of a running API Connect system is not supported.
- An API Connect system can be approximated by the following diagram:
- How to take a consistent backup of an API connect system at the infrastructure level
- The only way to take a consistent backup of an API connect system using VM snapshots and clones is to shut down ALL of the virtual machines comprising the system before taking the snapshot or clone.
- Once the virtual machines are stopped at the VM level, time is effectively frozen. Then a snapshot can be taken on all the VMs. A clone can be made from the snapshot taken on each VM. This set of clones represent a valid, consistent state that the API Connect system was in when it was shut down.
- Once all of the snapshots and clones have been taken the original API Connect system can be restarted.
- Restoring an API Connect System from VM clones
- The Cloned VMs represent a valid state of the original API Connect system. They will restart in exactly the same way as the original system restarted.
- If the objective is to stand up another instance of the cloned API connect system for testing or
DR purposes, the following must be true:
- The original system and the cloned system must be isolated from one another. The clone will be using the same hostnames and IP addresses as the original and so must be stood up in a separate virtual machine hosting environment with Network Address Translation between itself and any network to which the original system is stood up.
- The cloned system must be stood up in an identical environment in terms of its hardware, software and network.
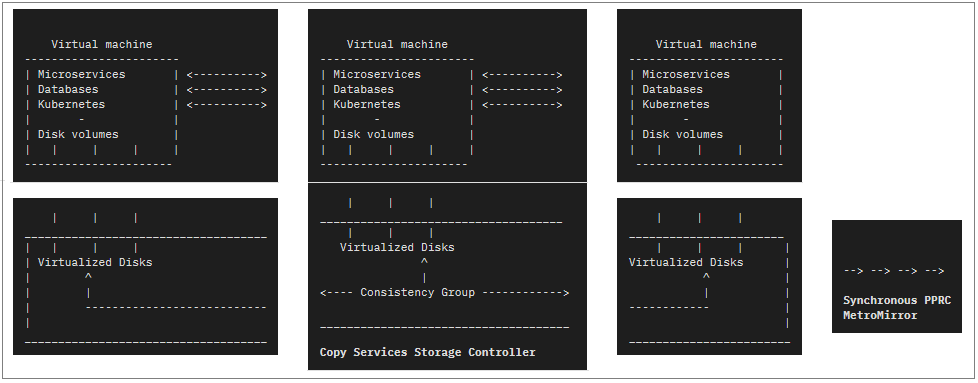
- Disaster Recovery approaches using Disk Replication:
- A common DR approach used by enterprises is to use disk based replication. In this case, a storage controller such as IBM’s San Volume Controller provides Copy Services. You can use Copy Services to create a completely consistent copy of a set of disks. IBM calls this feature Synchronous Remote Copy or MetroMirror. Other storage vendors have similar features.
- If you use Remote Copy to synchronize disk images to a DR site then IBM will support API connect
used with these systems so long as the copy at the DR site is completely consistent. Ensuring this
consistency is the responsibility of the storage controller and its configuration. It is
critically important to ensure that ALL of the disk volumes for all of the VMs or nodes in
the entire API Connect system are in the same remote copy consistency group as shown in the following image.
This ensures that DR scenarios do not create inconsistent volumes. If the disks are not in the same
consistency group then the copy will not be managed consistently and the system will not be
supported.
- Infrastructure based backup of API Connect using vSphere
-
The following procedure outlines steps to clone a VMware instance of API Connect v10, using the following topology:
- 3 Management Nodes
- 3 Portal Nodes
- 3 Analytics Nodes
- 3 Gateways
- Each of these components has a load balancer with its own IP address. The load balancers all sit on a single VM. The cluster is installed and configured on 13 VMs in VMware. In this example, the system was populated with data and APIs. These should first be tested to ensure that all published APIs respond as expected. Once this is done, use vSphere UI to complete the following steps:
- Power off VMs
To power off the VMs in sync, schedule a “shutdown guest OS” such that all the VMs shutdown at the same time. Although the shutdown does not occur at exactly the same instant, this does allow the shutdown for every machine to be as close in time as possible.
- Take snapshots
Take snapshots of each VM after shutdown. Using the scheduling feature in the UI, schedule a snapshot of all the VMs at the same instant. If cloning should adversely affect the system in any way then the original VMs can be reverted back to these snapshots.
- Clone VMs
Use the clone feature of the UI to create a clone of each VM. This VM should sit in the same resource pool as the original cluster. This is simply an exact copy of the disks of the original machine. The clones and originals are in no way coupled.
- Power on clones
Schedule the power-on for each clone VM such that all the clone VMs power on simultaneously. Once this is done, test the cluster to ensure that the APIs respond as expected. For the example cluster topology shown earlier on this page, it can take a couple of hours after power-on for all the APIs to respond as expected.
-