![[V9.1.0 Jul 2018]](ng910.gif)
![[IBM MQ Advanced]](ngadv.gif)
![[Linux]](nglinux.gif)
RDQM disaster recovery
RDQM (replicated data queue manager) is available on a subset of Linux® platforms and can provide a disaster recovery solution.
See Software Product Compatibility Reports for full details.
You can create a primary instance of a disaster recovery queue manager running on one server, and a secondary instance of the queue manager on another server that acts as the recovery node. Data is replicated between the queue manager instances. If you lose your primary queue manager, you can manually make the secondary instance into the primary instance and start the queue manager, then resume work from the same place. You cannot start a queue manager while it is in the secondary role. The replication of the data between the two nodes is handled by DRBD.
You can choose between synchronous and asynchronous replication of data between primary and secondary queue managers. If you select the asynchronous option, operations such as IBM® MQ PUT or GET complete and return to the application before the event is replicated to the secondary queue manager. Asynchronous replication means that, following a recovery situation, some messaging data might be lost. But the secondary queue manager will be in a consistent state, and able to start running immediately, even if it is started at a slightly earlier part of the message stream.
You cannot add disaster recovery to an existing queue manager, although you can migrate an existing queue manager to become a RDQM queue manager (see Migrating a queue manager to become a DR RDQM queue manager). A queue manager cannot be configured with both RDQM disaster recovery and RDQM high availability.
You can have several pairs of RDQM queue managers running on a number of different servers. For example, you could have primary disaster recovery queue managers running on different nodes, while all their secondary disaster recovery queue managers run on the same node. Some example configurations are illustrated in the following diagrams.
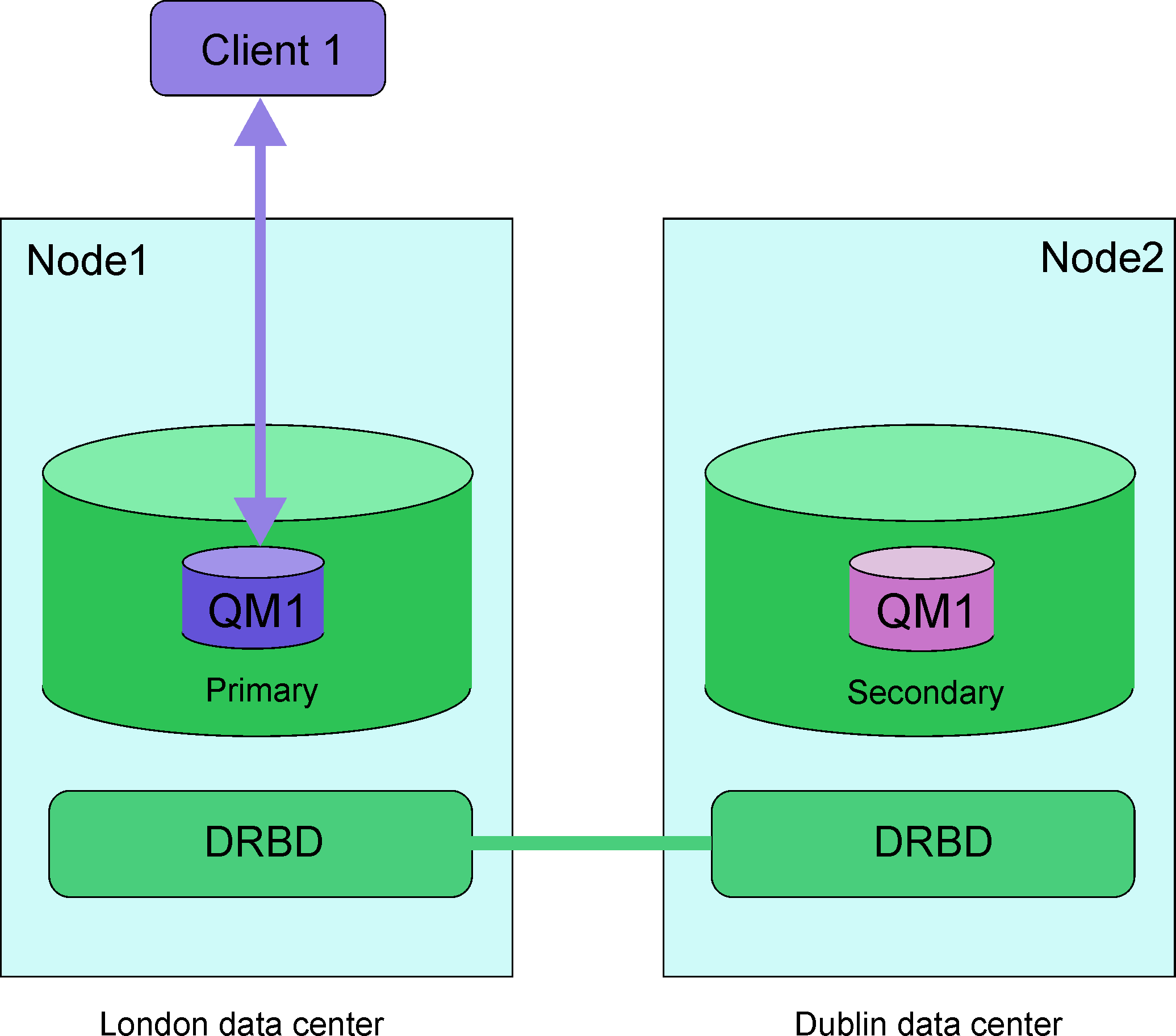
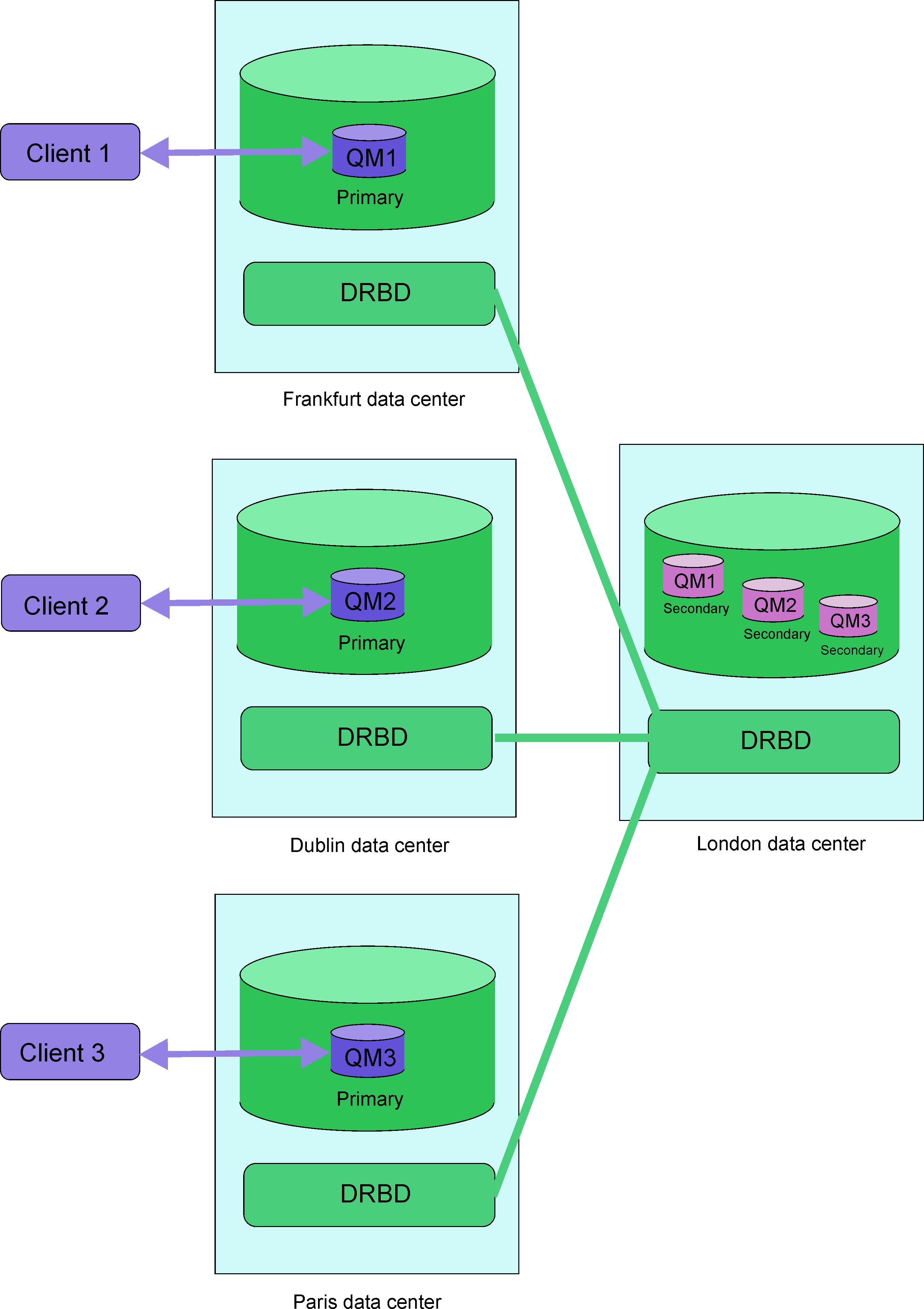
Replication, synchronization, and snapshots
While the two nodes in a disaster recovery configuration are connected, any updates to the persistent data for a disaster recovery queue manager are transferred from the primary instance of the queue manager to the secondary instance. This is known as replication.
If the network connection between the two nodes is lost, the changes to the persistent data for the primary instance of a queue manager are tracked. When the network connection is restored, a different process is used to get the secondary instance up to speed as quickly as possible. This is known as synchronization.
While synchronization is in progress, the data on the secondary instance is in an inconsistent state. A snapshot of the state of the secondary queue manager data is taken. If a failure of the main node or the network connection occurs during synchronization, the secondary instance reverts to this snapshot and the queue manager can be started. Any of the updates that happened since the original network failure are lost, however.
Partitioned data (split brain)
DR RDQM configurations require user action after loss of the primary instance of a queue manager to promote and run the secondary instance on the recovery node. It is the responsibility of whoever (or whatever) promotes the secondary instance to ensure that the former primary queue manager is stopped. If the original primary keeps running, it might process messages and, when normal operation is restored, the two instances of the queue manager have different views of the data. This is known as a partitioned or split-brain state.
- The node on which the primary queue manager is running fails completely. You promote the secondary instance to become the primary; you cannot take action to stop the original primary because it is not running. When the original node is repaired or replaced, the queue manager on that node will be initially made the secondary and be synchronized with the primary queue manager on the recovery node. The roles of the two queue managers are then reversed, and normal operation recommences. The only potential data loss in this situation is any data that the primary had not completed replicating to the secondary before the node failed.
- There is a network failure affecting the replication link between the nodes running the primary and secondary instances of the queue manager. In this situation you must ensure that you stop the original primary before you promote the secondary. If the original primary still has other network connectivity you effectively have two primary instances running at the same time, and partitioned data can accrue. (If the replication link is working, you cannot promote a secondary queue manager if the primary instance is still running, the command fails.)
- There is a complete network failure on the node running the primary instance of the queue manager. Again you must ensure that you stop the primary instance before you promote the secondary. If the previous primary is still running when the network is restored, there will be two primary instances, and again partitioned data will accrue.
When you do a managed failover, you should not see a DR status of partitioned
for the queue manager instances. A managed failover ends the queue manager on the primary node, then
starts the queue manager on the recovery node after data has been fully replicated. A partitioned
state is not expected because the queue manager is ended and data is synchronized between the nodes
before it is started on the recovery node. If the queue manager is started on the recovery node
while there is a loss of connectivity between the nodes then data divergence is likely if the queue
manager was active on the main node when connectivity was lost. In this scenario, a partitioned
state is expected to be reported once connectivity is restored because the queue manager data was
not synchronized. If a partitioned state occurs you might have to examine the two data sets and make
an informed decision about what set to keep. See Resolving a partitioned (split brain) problem in DR RDQM.