How a HISAM record is stored
HISAM database records are stored in two data sets: a primary data set and an overflow data set.
The primary data set contains an index and all segments in a database record that can fit in one logical record. The index provides direct access to the root segment (and therefore to database records). The overflow data set, contains all segments in the database record that cannot fit in the primary data set. A key-sequenced data set (KSDS) is the primary data set and an entry-sequenced data set (ESDS) is the overflow data set.
There are several things you need to know about storage of HISAM database records:
- You define the logical record length of both the primary and overflow
data set (subject to the rules listed in this topic). The logical
record length can be different for each data set. This allows you
to define the logical record length in the primary data set as large
enough to hold an
average
database record or the most frequently accessed segments in the database record. Logical record length in the overflow data set can then be defined (subject to some restrictions) as whatever is most efficient given the characteristics of your database records. - Logical records are grouped into control intervals (CIs). A control interval is the unit of data transferred between an I/O device and storage. You define the size of CIs.
- Each database record starts at the beginning of a logical record in the primary data set. A database record can only occupy one logical record in the primary data set, but overflow segments of the database record can occupy more than one logical record in the overflow data set.
- Segments in a database record cannot be split and stored across two logical records. Because of this and because each database record starts a new logical record, unused space exists at the end of many logical records. When the database is initially loaded, IMS™ inserts a root segment with a key of all X'FF's as the last root segment in the database.
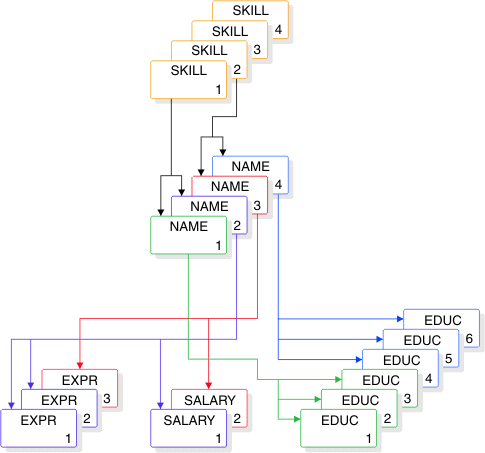
The following figure shows four HISAM database records.
The following figure shows the four records from the preceding figure as they are initially stored on the primary and overflow data sets. In storage, a HISAM segment consists of a 2-byte prefix followed by user data. The first byte of the prefix is the segment code, which identifies the segment type to IMS. This number can be from 1 to 255. The segment code is assigned to the segment by IMS in ascending sequence, starting with the root segment and continuing through all dependents in hierarchical sequence. The second byte of the prefix is the delete byte.
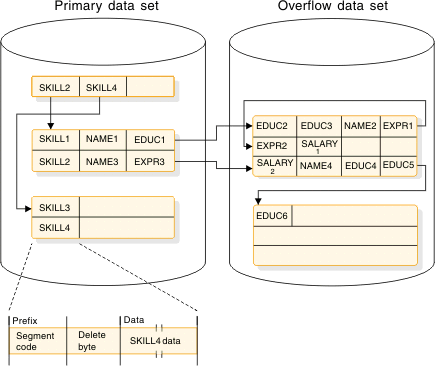
Each logical record in the primary
data set contains the root plus all dependents of the root (in hierarchical
sequence) for which there is enough space. The remaining segments
of the database record are put in the overflow data set (again in
hierarchical sequence). The two parts
of the database record
are chained together with a direct-address pointer. When
overflow segments in a database record use more than one logical record
in the overflow data set, as is the case for the first and second
database records in the preceding figure, the logical records are
also chained together with a direct-address pointer. Note in the figure
that HISAM indexes do not contain a pointer to each root segment in
the database. Rather, they point to the highest root key in each block
or CI.
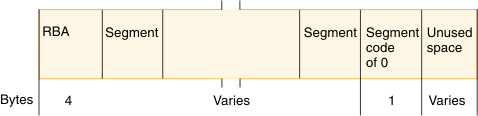
The following figure illustrates the following points regarding the structure of a logical record in a HISAM database:
- In a logical record, the first 4 bytes are a direct-address pointer to the next logical record in the database record. This pointer maintains all logical records in a database record in correct sequence. The last logical record in a database record contains zeros in this field.
- Following the pointer are one or more segments of the database record in hierarchical sequence.
- Following the segments is a 1-byte segment code of 0. It says that the last segment in the logical record has been reached.