Clustering of nonpartitioned indexes on partitioned tables
Clustering indexes offer the same benefits for partitioned
tables as they do for regular tables. However, care must be taken
with the table partitioning key definitions when choosing a clustering
index.
You can create a clustering index on a partitioned table using
any clustering key. The database server attempts to use the clustering
index to cluster data locally within each data partition. During a
clustered insert operation, an index lookup is performed to find a
suitable record identifier (RID). This RID is used as a starting point
in the table when looking for space in which to insert the record.
To achieve optimal clustering with good performance, there should
be a correlation between the index columns and the table partitioning
key columns. One way to ensure such correlation is to prefix the index
columns with the table partitioning key columns, as shown in the following
example:
partition by range (month, region)
create index...(month, region, department) cluster
Although the database server does not enforce this correlation,
there is an expectation that all keys in the index will be grouped
together by partition IDs to achieve good clustering. For example,
suppose that a table is partitioned on QUARTER and a clustering index
is defined on DATE. There is a relationship between QUARTER and DATE,
and optimal clustering of the data with good performance can be achieved
because all keys of any data partition are grouped together within
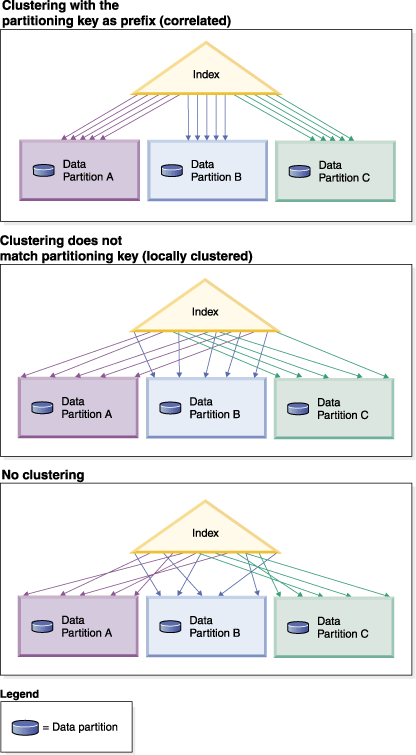
the index. Figure 1 shows that
optimal scan performance is achieved only when clustering correlates
with the table partitioning key.Figure 1. The possible effects of a clustered index on a partitioned
table.
Benefits of clustering include:
Rows are in key order within each data partition.
Clustering indexes improve the performance of scans that traverse
the table in key order, because the scanner fetches the first row
of the first page, then each row in that same page before moving on
to the next page. This means that only one page of the table needs
to be in the buffer pool at any given time. In contrast, if the table
is not clustered, rows are likely fetched from different pages. Unless
the buffer pool can hold the entire table, most pages will likely
be fetched more than once, greatly slowing down the scan.
If the clustering key is not correlated with the table partitioning
key, but the data is locally clustered, you can still achieve the
full benefit of the clustered index if there is enough space in the
buffer pool to hold one page of each data partition. This is because
each fetched row from a particular data partition is near the row
that was previously fetched from that same partition (see the second
example in Figure 1).