A partitioned index is made up of a set of index
partitions, each of which contains the index entries for a
single data partition. Each index partition contains references only
to data in its corresponding data partition. Both system- and user-generated
indexes can be partitioned.
A partitioned index becomes beneficial if:
You are rolling data in or out of partitioned tables by using
the ATTACH PARTITION or DETACH PARTITION clauses of the ALTER TABLE
statement. With a nonpartitioned index, the SET INTEGRITY statement
that you must run before the data in the newly attached partition
is available can be time consuming and require large amounts of log
space. When you
attach a table partition that uses a partitioned index, you still
must issue a SET INTEGRITY statement to perform tasks such as range
validation and constraint checking.
Tip: If data integrity checking, including range validation
and other constraints checking, can be done through application logic
that is independent of the data server before an attach operation,
newly attached data can be made available for use much sooner. You
can optimize the data roll-in process by using the SET INTEGRITY...ALL
IMMEDIATE UNCHECKED statement to skip range and constraints violation
checking. In this case, the table is brought out of SET INTEGRITY
pending state, and the new data is available for applications to
use immediately, as long as there are no nonpartitioned user indexes
on the target table.
If
the indexes for the source table match the index partitions for
the target table, SET INTEGRITY processing does not incur the performance
and log processing associated with index maintenance; the newly rolled-in
data is accessible more quickly than it would be using nonpartitioned
indexes.
You are performing maintenance on data in a specific
partition that necessitates an index reorganization. For example,
consider a table with 12 partitions, each corresponding to a specific
month of the year. You might want to update or delete many rows that
are specific to one month of the year. This action could result in
a fragmented index, which might require that you perform an index
reorganization. With a partitioned index, you can reorganize just
the index partition that corresponds to the data partition where the
changes were made, which could save a significant amount of time compared
to reorganizing an entire, nonpartitioned index.
There
are some types of indexes that cannot be partitioned:
Indexes over nonpartitioned data
Indexes over spatial data
XML column path indexes (system generated)
You must always create these indexes as nonpartitioned. In addition,
the index key for partitioned unique indexes must include all columns
from the table-partitioning key, whether they are user- or system-generated.
The latter would be the case for indexes created by the system for
enforcing unique or primary constraints on data.
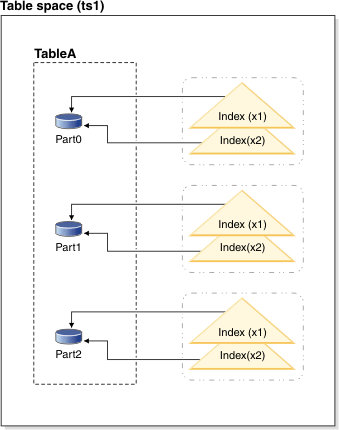
Figure 1. Partitioned
indexes that share a table space with data partitions of a table
In this example, all of the data partitions for table A and all
of the index partitions for table A are in a single table space. The
index partitions reference only the rows in the data partition with
which they are associated. (Contrast a partitioned index with a nonpartitioned
index, where the index references all rows across all data
partitions). Also, index partitions for a data partition are in the
same index object. This particular arrangement of indexes and index
partitions would be established with statements like the following
statements:
CREATE TABLE A (columns) in ts1
PARTITION BY RANGE (column expression)
(PARTITION PART0 STARTING FROM constant ENDING constant,
PARTITION PART1 STARTING FROM constant ENDING constant,
PARTITION PART2 STARTING FROM constant ENDING constant,
CREATE INDEX x1 ON A (...) PARTITIONED;
CREATE INDEX x2 ON A (...) PARTITIONED;
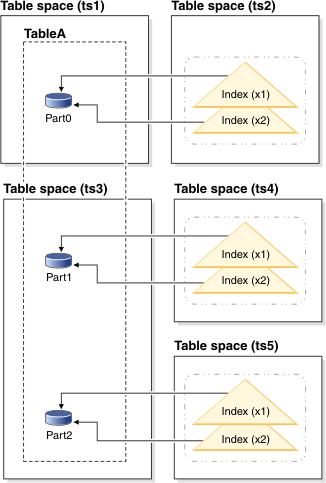
Figure 2 shows another
example of a partitioned index.Figure 2. Partitioned indexes with data partitions
and index partitions in different table spaces.
In this example, the data partitions for table A are distributed
across two table spaces, TS1, and TS3. The index partitions are also
in different table spaces. The index partitions reference only the
rows in the data partition with which they are associated. This particular
arrangement of indexes and index partitions would be established with
statements like the following statements:
CREATE TABLE A (columns)
PARTITION BY RANGE (column expression)
(PARTITION PART0 STARTING FROM constant ENDING constant IN ts1 INDEX IN ts2,
PARTITION PART1 STARTING FROM constant ENDING constant IN ts3 INDEX IN ts4,
PARTITION PART2 STARTING FROM constant ENDING constant IN ts3,INDEX IN ts5)
CREATE INDEX x1 ON A (...);
CREATE INDEX x2 ON A (...);
In this case, the PARTITIONED clause was omitted
from the CREATE INDEX statement; the indexes are still created as
partitioned indexes, as this setting is the default for partitioned
tables.
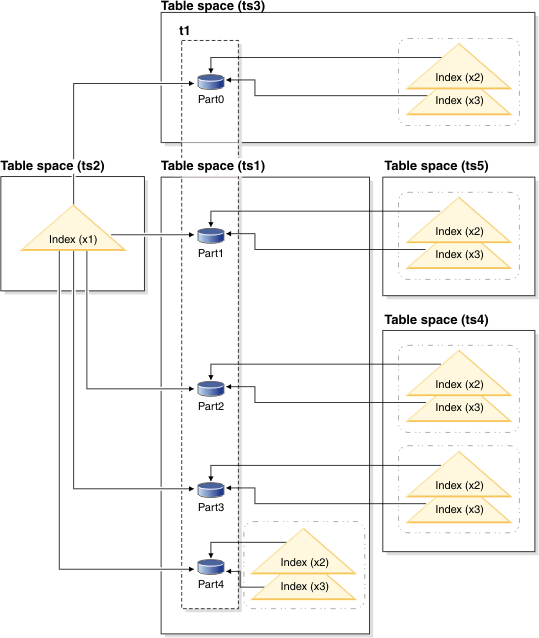
The Figure 3 diagram shows an
example of a partitioned table with both nonpartitioned and partitioned
indexes.Figure 3. Combination of
nonpartitioned and partitioned indexes for a partitioned table
In this diagram, index X1 is a nonpartitioned index that references
all of the partitions of table T1. Indexes X2 and X3 are partitioned
indexes that reside in various table spaces. This particular arrangement
of indexes and index partitions would be established with statements
like the following statements:
CREATE TABLE t1 (columns) in ts1 INDEX IN ts2 1
PARTITION BY RANGE (column expression)
(PARTITION PART0 STARTING FROM constant ENDING constant IN ts3, 2
PARTITION PART1 STARTING FROM constant ENDING constant INDEX IN ts5,
PARTITION PART2 STARTING FROM constant ENDING constant INDEX IN ts4,
PARTITION PART3 STARTING FROM constant ENDING constant INDEX IN ts4,
PARTITION PART4 STARTING FROM constant ENDING constant)
CREATE INDEX x1 ON t1 (...) NOT PARTITIONED;
CREATE INDEX x2 ON t1 (...) PARTITIONED;
CREATE INDEX x3 ON t1 (...) PARTITIONED;
Note
that:
The nonpartitioned index X1 is stored in table space TS2, because
this location is the default specified (see 1 )
for nonpartitioned indexes for table T1.
The index partition for data partition 0 (Part0) is stored in
table space TS3, because the default location for an index partition
is the same as the data partition it references (see 2 ).
Part4 is stored in TS1, which is the default table space for data
partitions in table T1 (see 1 ); the index
partitions for this data partition also reside in TS1, again because
the default location for an index partition is the same as the data
partition it references.
Important: Unlike nonpartitioned indexes, with partitioned
indexes you cannot use the INDEX IN clause of the CREATE INDEX statement
to specify the table space in which to store index partitions. The
only way to override the default storage location for index partitions
is to specify the location at the time you create the table by using
the partition-level INDEX IN clause of the CREATE TABLE statement.
The table-level INDEX IN clause has no effect on index partition placement.
You create partitioned indexes for a partitioned table by including
the PARTITIONED option in a CREATE INDEX statement. For example, for
a table named SALES partitioned with sales_date as
the table-partitioning key, to create a partitioned index, you could
use a statement like this statement:
CREATE INDEX partIDbydate on SALES (sales_date, partID) PARTITIONED
If you are creating a partitioned unique index, then the table
partitioning columns must be included in the index key columns. So,
using the previous example, if you tried to create a partitioned index
with the following statement:
CREATE UNIQUE INDEX uPartID on SALES (partID) PARTITIONED
the
statement would fail because the column sales_date,
which forms the table-partitioning key is not included in the index
key.
If you omit the PARTITIONED keyword when you create an index on
a partitioned table, the database manager creates a partitioned index
by default unless the following conditions apply:
You are creating a unique index, and the index key does not include
all of the table-partitioning keys.
You are creating one of the types of indexes that are described
at the beginning of this topic as not able to be created as partitioned
indexes.
In either of these cases, the index is created as a nonpartitioned
index.
Although creating a nonpartitioned index with a definition that
matches that of an existing nonpartitioned index returns SQL0605W,
a partitioned index can coexist with a nonpartitioned index with a
similar definition. This coexistence is intended to allow for easier
adoption of partitioned indexes.