High availability
The IBM® MQ Appliance might experience outages both planned and unplanned. The high availability (HA) features of the appliance enable queue managers to have maximum availability. The HA features of the IBM MQ Appliance give the appliance an ability to withstand software or hardware outages. Therefore, it is available as much of the time as possible. These outages might be planned events, such as maintenance and backups, or unplanned events, such as hardware failures or power failures.
To configure HA for the IBM MQ Appliance, you can connect a pair of appliances either directly, or by using switches (a separate switch for each link). You must then create an HA group for this pair of appliances. To work most effectively as a high availability solution, the two appliances need to be in close physical proximity to one another. For this reason the HA solution is not intended to provide disaster recovery, although you can configure a disaster recovery solution for queue managers that run on your HA pair.
For details of combining HA and disaster recovery on the appliance, see Disaster recovery for a high availability configuration. A queue manager can belong to an HA group and be part of a disaster recovery configuration.
The HA group controls the availability of any HA queue managers that are created on the appliances. By default, the HA queue managers are run on the appliance on which they are created, when that appliance is available. This appliance is known as the preferred appliance of the HA queue manager. You can use commands to specify the other appliance as the preferred appliance, if required, or to specify that the queue manager has no preferred appliance (see Managing queue manager locations in a high availability group).
If an appliance in the pair is stopped for any reason, the HA queue managers that are running on that appliance automatically start to run on the other appliance. That is, the queue managers are failed over to the other appliance. When the stopped appliance is restarted, and the required data is replicated back to that appliance, it resumes running the HA queue managers for which it is the preferred appliance. Persistent messages are preserved.
To ensure that the HA queue manager is ready to run on either appliance, queue manager data is replicated synchronously between the appliances. In some situations, such as when one appliance is unavailable, the queue manager data cannot be replicated synchronously. When the appliance becomes available, the queue managers in the HA group enter a catch-up phase, in which the queue manager data is replicated. By default, the appliances use a dedicated 10 Gb Ethernet connection for replication. You can select a 40 Gb Ethernet connection if required (see sethalink).
This HA solution enables all the HA queue managers in the HA group to continue running when one appliance in the group is stopped. If both appliances in the HA group fail at the same time, the HA queue managers cannot run until at least one of the appliances is restarted.
Appliances in an HA group can run other queue managers that are outside of the HA group, but if the appliance fails or is stopped, then that queue manager stops. Appliances can belong only to one HA group.
Applications can connect to HA queue managers in one of two ways. They can have an IP address configured for the data interface on each of the appliances in the HA group, and the application itself determines which one to use for connecting to the active queue manager. Alternatively, applications can use a single floating IP address to access a particular queue manager, and that IP address will work for that queue manager whichever appliance it is running on (note that the appliances still both require an interface configured with a static IP for the floating IP address to map to). Using a floating IP address in this way makes queue manager failover almost invisible to the connecting application.
For more information about configuring HA on the IBM MQ Appliance, see Configuring high availability. For information about planning the physical location, see Planning a high availability system.
Example HA group
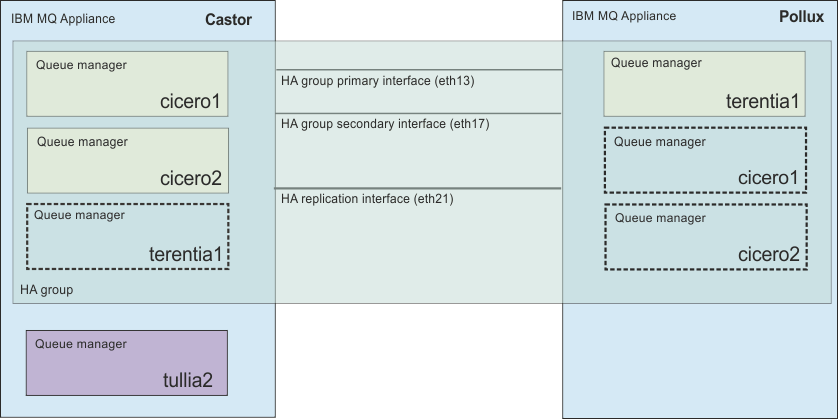
In the example configuration, two IBM MQ Appliances, named castor and pollux, are located in the same data center, in adjacent racks. The three cables that connect the two appliances are less than a meter long, and so communication between the two has the minimum of delay.
The appliance that is named pollux runs one queue manager, terentia1, which is inside the HA group. The appliance that is named castor has two queue managers that are running within the HA group, cicero1 and cicero2. It also has another queue manager, tullia2, that runs outside the HA group. Both castor and pollux have shadow versions of the HA queue managers on the other appliance. These queue managers are kept up to date by replication across the replication interface. Two more interfaces, a primary and a secondary, track the heartbeat of the other appliance.
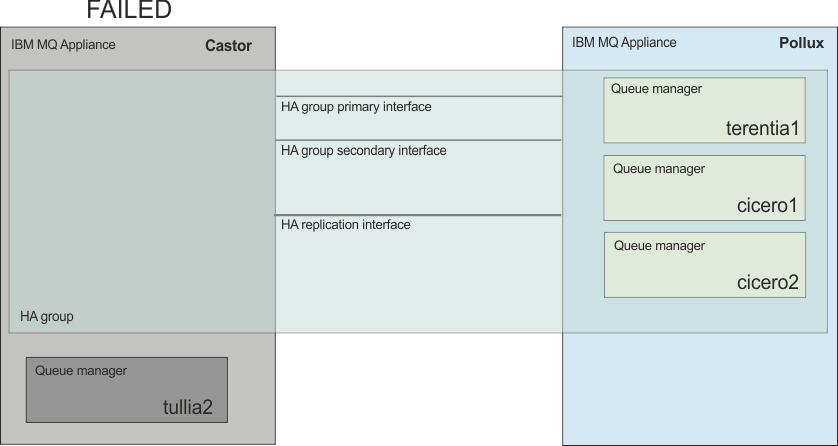
The rack that castor is in suffers a power failure. The appliance that is named pollux detects that castor has failed, and starts to run the queue managers cicero1 and cicero2. The queue manager tullia2 is outside the HA group, so does not fail over to pollux.
When power is restored, the queue managers cicero1 and cicero2 run on the appliance that is named castor again.