Measurement Levels
Measurement level (formerly known as "data type" or "usage type") describes the usage of the data fields in IBM® SPSS® Modeler. The measurement level can be specified on the Types tab of a source or Type node. For example, you may want to set the measurement level for an integer field with values of 1 and 0 to Flag. This usually indicates that 1 = True and 0 = False.
Storage versus measurement. Note that the measurement level of a field is different from its storage type, which indicates whether data are stored as a string, integer, real number, date, time, or timestamp. While data types can be modified at any point in a stream using a Type node, storage must be determined at the source when reading data into IBM SPSS Modeler (although it can subsequently be changed using a conversion function). See the topic Setting Field Storage and Formatting for more information.
Some modeling nodes indicate the permitted measurement level types for their input and target fields by means of icons on their Fields tab.
Measurement level icons
| Icon | Measurement level |
|---|---|
 |
Default |
 |
Continuous |
 |
Categorical |
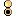 |
Flag |
 |
Nominal |
 |
Ordinal |
 |
Typeless |
 |
Collection |
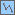 |
Geospatial |
The following measurement levels are available:
- Default Data whose storage type and values are unknown (for example, because they have not yet been read) are displayed as <Default>.
- Continuous Used to describe numeric values, such as a range of 0–100 or 0.75–1.25. A continuous value can be an integer, real number, or date/time.
- Categorical Used for string values when an exact number of distinct values is unknown. This is an uninstantiated data type, meaning that all possible information about the storage and usage of the data is not yet known. Once data have been read, the measurement level will be Flag, Nominal, or Typeless, depending on the maximum number of members for nominal fields specified in the Stream Properties dialog box.
- Flag Used for data with two distinct values that indicate the presence or absence of a trait, such as true and false, Yes and No or 0 and 1. The values used may vary, but one must always be designated as the "true" value, and the other as the "false" value. Data may be represented as text, integer, real number, date, time, or timestamp.
- Nominal Used to describe data with multiple distinct values, each treated as a member of a set, such as small/medium/large. Nominal data can have any storage—numeric, string, or date/time. Note that setting the measurement level to Nominal does not automatically change the values to string storage.
- Ordinal Used to describe data with multiple distinct values that have an inherent order. For example, salary categories or satisfaction rankings can be typed as ordinal data. The order is defined by the natural sort order of the data elements. For example, 1, 3, 5 is the default sort order for a set of integers, while HIGH, LOW, NORMAL (ascending alphabetically) is the order for a set of strings. The ordinal measurement level enables you to define a set of categorical data as ordinal data for the purposes of visualization, model building, and export to other applications (such as IBM SPSS Statistics) that recognize ordinal data as a distinct type. You can use an ordinal field anywhere that a nominal field can be used. Additionally, fields of any storage type (real, integer, string, date, time, and so on) can be defined as ordinal.
- Typeless Used for data that does not conform to any of the above types, for fields with a single value, or for nominal data where the set has more members than the defined maximum. It is also useful for cases in which the measurement level would otherwise be a set with many members (such as an account number). When you select Typeless for a field, the role is automatically set to None, with Record ID as the only alternative. The default maximum size for sets is 250 unique values. This number can be adjusted or disabled on the Options tab of the Stream Properties dialog box, which can be accessed from the Tools menu.
- Collection Used to identify non-geospatial data that is recorded in a
list. A collection is effectively a list field of zero depth, where the elements in that list have
one of the other measurement levels.
For more information about lists, see List storage and associated measurement levels.
- Geospatial Used with the List storage type to identify geospatial data.
Lists can be either List of Integer or List of Real fields with a list depth that is between zero
and two, inclusive.
For more information, see Geospatial measurement sublevels.
You can manually specify measurement levels, or you can allow the software to read the data and determine the measurement level based on the values that it reads.
Alternatively, where you have several continuous data fields that should be treated as categorical data, you can choose an option to convert them. See the topic Converting Continuous Data for more information.
To Use Auto-Typing
- In either a Type node or the Types tab of a source node, set the Values column to <Read> for the desired fields. This will make metadata available to all nodes downstream. You can quickly set all fields to <Read> or <Pass> using the sunglasses buttons on the dialog box.
- Click Read Values to read values from the data source immediately.
To Manually Set the Measurement Level for a Field
- Select a field in the table.
- From the drop-down list in the Measurement column, select a measurement level for the field.
- Alternatively, you can use Ctrl-A or Ctrl-click to select multiple fields before using the drop-down list to select a measurement level.