根本原因分析
Instana インシデントを管理し、考えられる根本原因の特定を迅速化します。 Instana インシデント、問題、および変更を自動的に検出し、アプリケーションのサービス品質に関する問題を特定、把握、調査するのに役立ちます。
現在、DevOps 技術者は、数百個あるいは数千個のコンポーネントから構成される動的アプリケーション環境において、重大な問題に直面しています。 何か問題が発生した場合、ユーザーがサービスの影響を感じ始める前に、できるだけ早く問題を検出して理解できる必要があります。 後にDevOpsサービスをできるだけ早く復旧するには、正確な根本原因を修正し、問題が再発しないようにする必要があります。 DevOps では、問題の根本原因を特定するのに数時間から数日かかることがあり、多くの場合、原因は特定されないままとなります。
前提条件
「 SaaS 」および「Self-hosted Instana 」の両環境において、推定根本原因分析はデフォルトで有効になっています。 ただし、イベントの根本原因分析を表示するには、お使いの環境が以下の前提条件を満たしている必要があります:
- 「Smart Alert」のインシデントが登録されている必要があります。 推定根本原因の分析は、アプリケーションのスマートアラートから生成されたイベントに対してのみサポートされています。 また、これらのアラートに含まれるすべての事象について、根本原因の特定に至るとは限りません。
- カスタムイベントをご利用の場合は、 Instana のスマートアラートへ移行する必要があります。
- 権限 :根本原因分析を表示するために必要な権限はありません。 ただし、インシデントの作成を設定するには、 「イベントおよびアラートの管理 」へのアクセス権を持ち、「イベントおよびアラートの構成」 権限が与えられているアカウントが必要です。
権限の設定に関する詳細については、 「ユーザーアクセスの管理」 を参照してください。
自動判定された推定根本原因
DevOps の運用担当者の平均修復時間(MTTR)を短縮するため、 Instana は、インシデントの推定根本原因を特定するプロセスを自動化します。 Instana の推定根本原因エンジンは、固定されたルールに依存するのではなく、統計的かつ非決定論的な分析モデルを採用しています。 Instana モデルの因果関係AIアルゴリズムを用いて、トレースの統計情報とトポロジーを動的かつ継続的に分析し、検出されたパターン、依存関係、異常の相関関係、およびテレメトリの信頼度スコアを評価することで、インシデントの原因となっている可能性が最も高いコンポーネントを特定します。 このアルゴリズムは10分ごとに推論を実行し、エラーの伝播源となり得るエンティティを特定します。
Causal AIアルゴリズムが問題の原因となりそうなエンティティ(または複数のエンティティ)を特定すると、「 推定根本原因 」セクションには、最も可能性の高い根本原因として特定された最大3つのエンティティが表示されます。 これらの要因は、問題を引き起こす可能性の高い順に並べられているため、最も可能性の高い根本原因が最初に表示されます。 エンティティとは、 Instana によって監視され、表示される物理的または論理的なエンティティを指します。 表示されているエンティティはすべて、そのエンティティの詳細ページへのリンクとなっており、そこではインシデント発生時点でのエンティティの状態が説明されています。 この推定される根本原因を特定することで、 Instana は、 DevOps の運用担当者がアプリケーションの障害の実際の原因と解決策をより迅速に特定できるようにします。
- アプリケーションのパースペクティブ
- サービス
- エンドポイント
- アプリケーションの観点から見たサービスレベル目標

- 最も可能性の高い根本原因となる要素、および特定されたその他の根本原因、ならびに関連するインフラストラクチャやアプリケーションの情報。 表示されている階層から、そのエンティティの詳細ページへのリンクも含まれています。
- DevOps の担当者が、特定のエンティティが最も可能性の高い根本原因として特定された理由を理解できるよう支援するために、そのエンティティを特定する際に用いられる根拠。
- 特定された推定根本原因に対する推奨措置の一覧。
- 高度なLLM(大規模言語モデル)ベースの調査機能を活用し、さらなる洞察を提供するインテリジェントなインシデント調査を実行するためのオプション(UIボタン)。 詳細はこちらをご覧ください。
- 推定される根本原因エンティティに関連付けられた関連イベントを表示するオプション(UIボタン)と、故障の可能性を示す確率レベル。 関連するイベントはすべて、推定される根本原因となるエンティティで発生した最近のイベントです。 詳細な関連イベントとともに、DevOps実務者は、問題の原因となった問題、インシデント、または変更イベントを迅速に特定できます。
- 原因の特定につながるトレースエラーメッセージやログを表示するオプション(UIボタン)により、問題の詳細を一目で把握することができます。
- トレースエラーメッセージは、推定される原因を経由するトレースから抽出されます(システムでトレースエラーが記録されている場合)。 この表には、エラーメッセージそのものと、指定された期間中に記録されたそのメッセージの発生回数が表示されます。
- トレースログは、システムのコールフローにおけるイベントをより詳細に記録したものです。 トレースログはカウント順に並べられ、「
ERROR」や「WARNようなログレベルが含まれる。
インシデント
インシデントは最も深刻なレベルに分類されます。 これらは、ユーザーがアクセスするエッジ サービスが影響を受ける場合、または差し迫った影響のリスクがある場合に作成されます。 ダイナミック・グラフを使用して、各インシデントのすべての関連するイベントが相関付けられて、コンテキストおよび根本原因分析の仮説が提供されます。
あるサービスの応答が突然、普段より遅くなった場合、この事象を「 平均レイテンシの急激な増加 」と呼びます。 このインシデントは自動的に警告として黄色でマークされます。このインシデントがアクティブになるまで色が表示されます。 解決されると、色が灰色に変わり、ドリルダウン メニューで引き続き使用できるようになります。 次のインシデントの例を参照してください。

インシデント詳細ビューは次の 3 つの部分で構成されています。
ヘッダーには、インシデントの主な事実に関する基本情報が表示されます。
- 開始時刻;
- 終了時刻 (継続している場合は「現行」)
- まだアクティブであるイベントの数
- 関連する変更の数
- 影響を受けるエンティティーの数
インシデントの開始日、終了日(解決済みの場合)、現在アクティブなイベントの数、このインシデントに関連する変更の数、および影響を受けたエンティティの数を確認できます:
図 3. インシデントKPI 
2 番目のセクションには、経時的なインシデントの進行状況が視覚的に表示されます。 このグラフには、開始から終了までの全期間と、開始時刻順に並べられたすべてのイベントが表示されています。 このビューが省略されている場合は 7 つのイベントに制限されます。 インシデントに一度に 7 つを超えるイベントが含まれている場合は、展開ボタンを押してフル・ビューを表示します。 いずれかのバーをクリックすると、その問題の詳細ビューが開きます。
図 4. 対象集団 
第3セクションには、第2セクションのグラフ表示に関する詳細が記載されています。 開始時間順に並べられたすべてのイベントのリストにより、ユーザーは各イベントに関する利用可能なすべての情報を確認できます。 イベントをクリックすると詳細が表示され、そのイベントに関するすべての情報を確認できます:
図 5. 詳細なインシデント情報 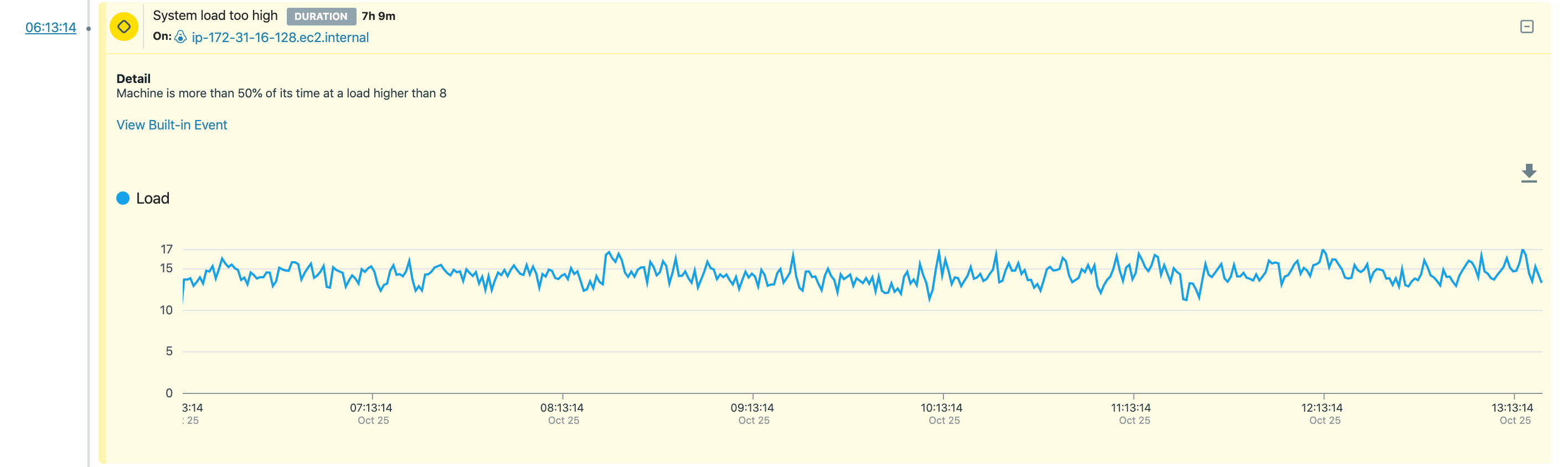
詳細情報はイベントを理解する際に役立ちます。詳細情報の後には、視覚化のために対応するメトリックがプロットされている複数のグラフが続きます。 イベントがまだアクティブな場合、グラフは新しい着信メトリック値のレンダリングを続行します。 2 つのフラグが使用可能です。 1 つのフラグは、イベントがサービスに影響を与えることを強調するためのものであり、もう 1 つのフラグは、イベントがインシデントをトリガーしたことを強調するためのものです。 設定されている場合、フラグはリスト内の各イベントの上に表示されます。
イベントにフォーカスすると、詳細セクションには、ポイント 3 のインシデント イベント リストに記載されているものと同じ情報が表示されます。
問題
「 インシデント 」とは、アプリケーション、サービス、またはその一部に障害が発生した場合に作成される事象のことです。 Instana サービス品質の低下から複雑なインフラの問題、ディスクの容量不足に至るまで、さまざまな問題を検知する、厳選された数百種類のヘルスシグネチャが搭載されています。 メトリクス、イベント、またはメタデータが想定値に戻ると、問題は自動的に解決されます。
組み込みの問題に加えて、ご使用のシステムに固有の問題を検出するために カスタム・イベント を定義することができます。
Instana によって検出されたすべての課題(組み込みの課題とカスタム課題の両方)を確認するには、 「イベント」 ビューに移動し、「 課題 」タブを選択してください。 「ダイナミックフォーカス」 を使用して、課題を絞り込むことができます。
各 Instana の号には、以下の情報が含まれています:
- 重大度: この情報は CRITICAL または WARNING のいずれかになります。 CRITICAL は、データ損失またはサービスが利用できない直接的または間接的なリスクがあることを意味します。 「警告」とは、ユーザー体験に影響を及ぼす可能性のある、あるいは長期的に問題を引き起こす可能性のあるその他のパフォーマンス上の問題を指します。
- 問題の開始時刻、終了時刻、および継続時間。
- 影響を受けるエンティティ:1つ以上のエンティティがこの問題の影響を受けています。
- 詳細:問題の背景や解決策についてさらに詳しく説明した内容。
- メトリクス:問題が発生した前後における、その問題に関連するメトリクス値を示すメトリクスチャート。
- 該当する場合は、 Unbounded Analytics にアクセスし、この問題の影響を受けているトレース、呼び出し、またはページ読み込みを調査してください。
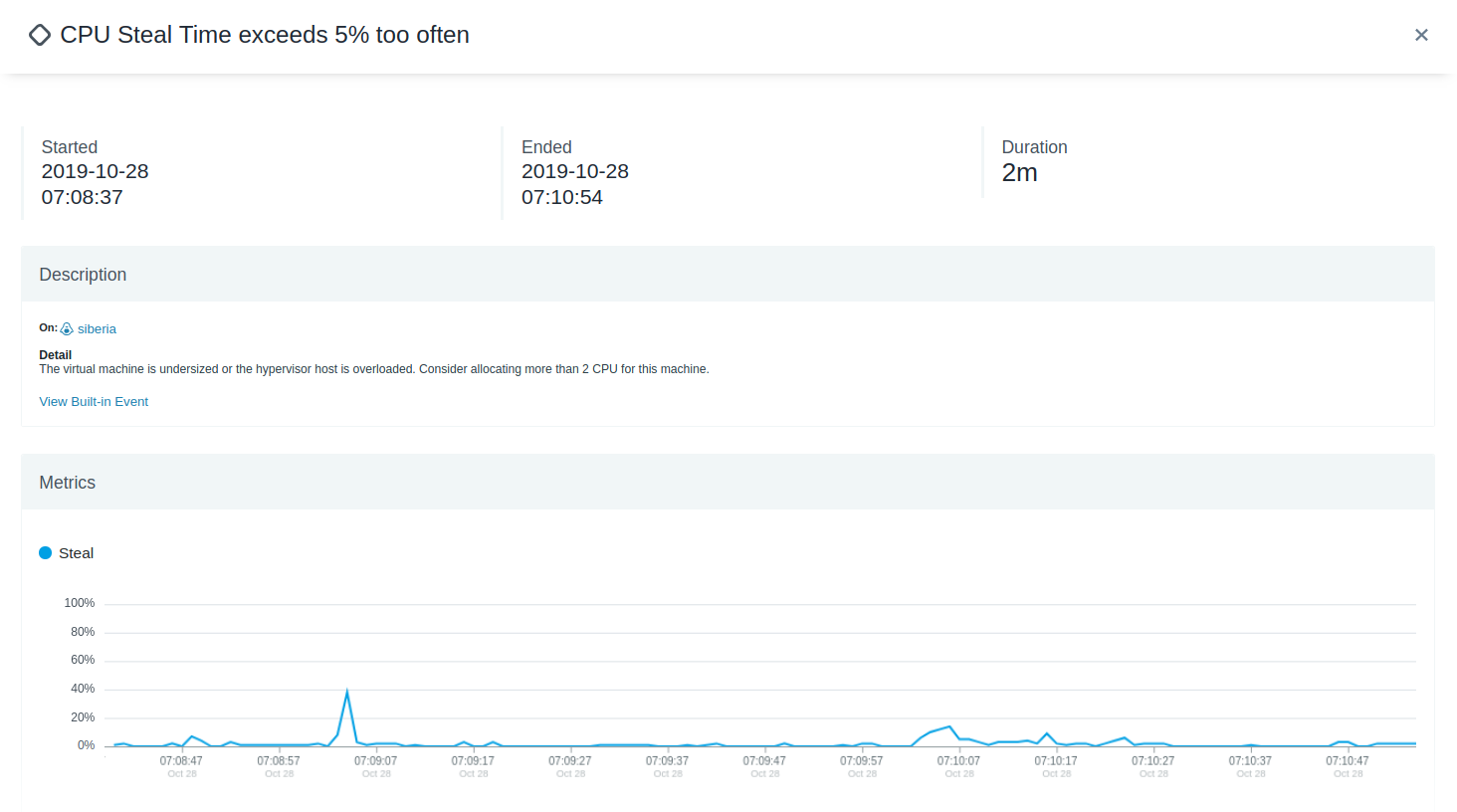
この例では、1 つの Linux マシン上の CPU スチール時間が疑わしいため、問題としてマークされています。 問題が発生しただけではアラートは発動しませんが、 Instana はその事象を記録します。 このシステムが接続されているサービスに不具合が生じた場合、この問題は当該インシデントの一部となります。 この手法は、 Instana の大きな利点の一つです。なぜなら、イベントとパフォーマンスの問題を手動で関連付ける必要がないからです。 ある処理が一時的にCPUを過剰に使用しているからといって、必ずしも問題があるとは限りません。 この情報は、サービスに影響を及ぼす場合にのみ重要となります。
組み込みイベントおよびカスタムイベントの管理に関する詳細については、 「組み込みイベントの管理」 を参照してください
Instana は監視対象のサービス間のすべての依存関係を把握しているため、インシデントがユーザーに影響を及ぼしている場合、サービス品質に関するあらゆる問題に対してインシデントを自動発生させます。 また、ディスクの容量不足や Elasticsearch クラスタのスプリットブレインといった重要インフラの問題についてもインシデントを発生させます。これらはデータ損失を引き起こす可能性が高いからです。
変更
「 変更 」とは、サーバーの起動・停止、デプロイ、システム上の設定変更など、変更を表すイベントのことです。 さらに、次のように分類されます。
- 変更 - バージョン、環境変数の値、その他のコンポーネントなど、コンポーネントの構成が変更されました
- オフライン/オンライン - 管理下にあるコンポーネントの存在を追跡
変更イベントは、構成の変更とインシデントの関係を自動的に検出するために動的グラフと一緒に使用される重要な情報です。
「イベント」ビュー
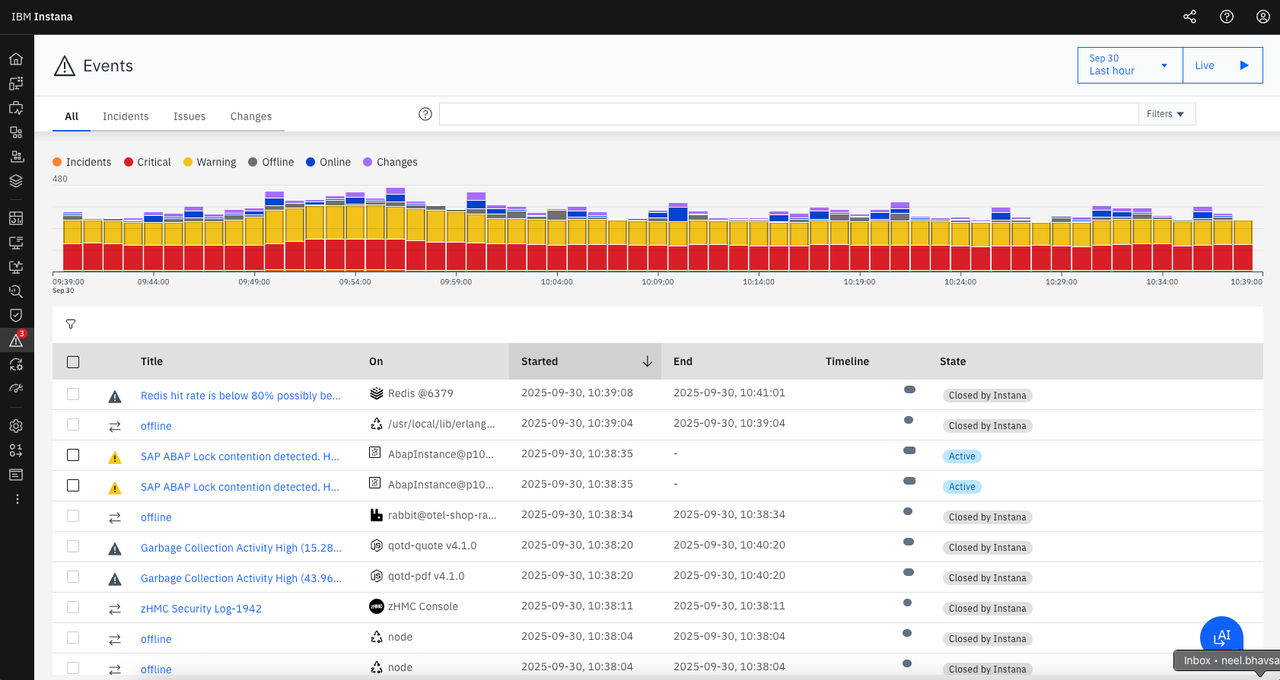
Instana によって検出されたすべてのイベントを確認するには、 [イベント] ダッシュボードに移動し、 [インシデント ]、 [課題 ]、[ 変更 ]、または [ すべて ] タブを選択して、それぞれのイベントタイプを表示してください。
すべてのイベントに対するフィルタリング機能
ダイナミック・フォーカス・クエリー
Instana によって検出されたイベントを検索するには、「ダイナミックフォーカス 」機能を利用します。 イベント棒グラフで1つまたは複数の棒を選択すると、イベントテーブルには、選択した棒に含まれるイベントのみが表示されます。 イベント棒グラフの棒を選択することで、現在の時間間隔を変更することなく、イベントの詳細を確認することができます。 また、検索ボックスを使用して、概要テーブルの「タイトル」または「発生先」(インシデントが発生したサービス)の列にあるデータから、特定の項目を検索することもできます。 この例での検索クエリーは event.text:"Error rate" です。 結果は、タイトルに「エラー率」というフレーズが含まれるすべてのイベントのリストになります。
テーブルのフィルタリング
「イベント」ビューでは、専用のUIフィルターを通じて強力なフィルタリング機能を利用できます。 イベント一覧は、以下の3つの主要なフィルタオプションを使用して絞り込むことができます:
- 一時的なイベント :イベントが一時的なものか、非一時的なものか、あるいはその両方か。
- イベントの種類 :イベントが「組み込み」か「カスタム」か。
- スマートアラート :アプリケーション、Webサイト、Synthetics、インフラストラクチャ、モバイル、ログ、またはSLOからのスマートアラートによってイベントがトリガーされた場合。
これらのフィルターは、単独でも組み合わせてでも使用でき、関連するイベントを素早く見つけ出し、最も重要な問題にトラブルシューティングの焦点を絞ることができます。

Impacted Users for application issues (private preview)
This feature is under private preview. You can contact the technical Instana support to get included in this program.
By using this feature, you can see the impacted users of a specific event, and get valuable insights into how events are affecting your users by quickly identifying and addressing issues that impact user experience.
Availability
What is an impacted user?
Event data correlation and impact analysis
When an event is triggered, the system correlates data from your front-end and back-end monitoring to identify which end users are impacted. Then, you can detailed information about the affected users and understand the scope and impact of the issue.