大規模言語モデルの監視
Instana UI で LLM のメトリクスとトレースを監視できます。
LLMメトリック
LLMメトリクスを表示するには、 ] をクリックします。
LLMのメトリクス(コスト、レイテンシ、その他のパフォーマンス詳細)は、「LLMメトリクス 」タブに表示されます。
| パラメーター | 説明 |
|---|---|
| 入力コスト | LLM(大規模言語モデル)への入力トークン(プロンプトまたはクエリ)送信にかかるコスト。 |
| 出力コスト | 入力に対してLLMが生成したトークンにかかるコスト。 |
| 合計コスト | 入力に対するLLMが生成したトークンの総コスト。 コストは、投入コストと産出コストの合計である。 |
| モデル | 観察期間中に使用されたLLMモデルの数。 この値は、採用されている言語モデルの多様性を示しています。 |
| GenAIサービス | 利用された生成AIサービスプロバイダーまたはエンドポイントの数。 各モデルは異なるサービスによって提供される可能性があり、パフォーマンスや価格設定に潜在的な差異が生じることを反映しています。 |
| LLM呼び出し(合計) | LLMが呼び出された回数、すなわち、プロンプトと応答のやり取りが何回行われたか。 この指標はモデルの全体的な活動レベルを示します。 |
| トークン使用状況 | トークンの経時的な使用状況。 LLMモデルまたはサービスごとに使用状況をフィルタリングすることで、個別の消費パターンや集合的な消費パターンを把握できます。 |
| コスト | LLMモデルの経時的なコスト動向。 LLMモデルやサービスごとに利用状況をフィルタリングして、費用対効果を分析することができます。 |
| LLM呼び出し | 時間の経過に伴うLLM呼び出しの回数。 LLMモデルまたはサービスごとのモデル呼び出し頻度を確認し、使用量のピーク時間帯を特定できます。 |
| LLM待ち時間 | LLM呼び出しの経時的な遅延。 この指標は各モデルの応答時間を測定するもので、モデルが出力を生成する速さを示しています。 |
| モデル名 | 使用されたLLMモデル。 |
| 入力トークン | LLMに送信されるプロンプトまたはクエリ内のトークン数。 |
| 出力トークン | LLMが生成した応答トークンの数。 |
| 合計トークン数 | 入力トークンと出力トークンの合計。各インタラクションにおけるトークン総数を表す。 |
| 合計コスト | LLMによって生成されたトークンの総支出額。 |
| 待ち時間(平均) | 全呼び出しにおけるLLMの平均応答時間。 |
| 呼び出し回数 | LLMが呼び出された、または実行された総回数。 |
LLMトレース
LLMのトレースを表示するには、 をクリックします。
LLMのトレース(入力プロンプトと出力応答を含む)は、 「トレース 」タブに表示されます。
| パラメーター | 説明 |
|---|---|
| トレース ID | 生成AIシステムとの各トレースまたはインタラクションに割り当てられる一意の識別子。 特定のリクエストを追跡したり、デバッグしたりするのに役立ちます。 |
| 生成AIサービス | プロンプトの処理に使用された生成AIサービス。 |
| 入力プロンプト | AIモデルに提出される質問または命令。 |
| 出力応答 | 入力プロンプトに対してAIモデルが生成した回答。 |
| 合計トークン数 | インタラクションで使用されたトークンの総数(入力と出力の両方を含む)。 |
| 期間 | AIモデルが応答を生成するのに要した時間(ミリ秒単位で測定)。 この値は、パフォーマンスとレイテンシを評価するのに役立ちます。 |
| 状況 | 操作が成功したかどうかを示す。 緑色のチェックマークは、応答がエラーなく正常に生成されたことを示します。 |
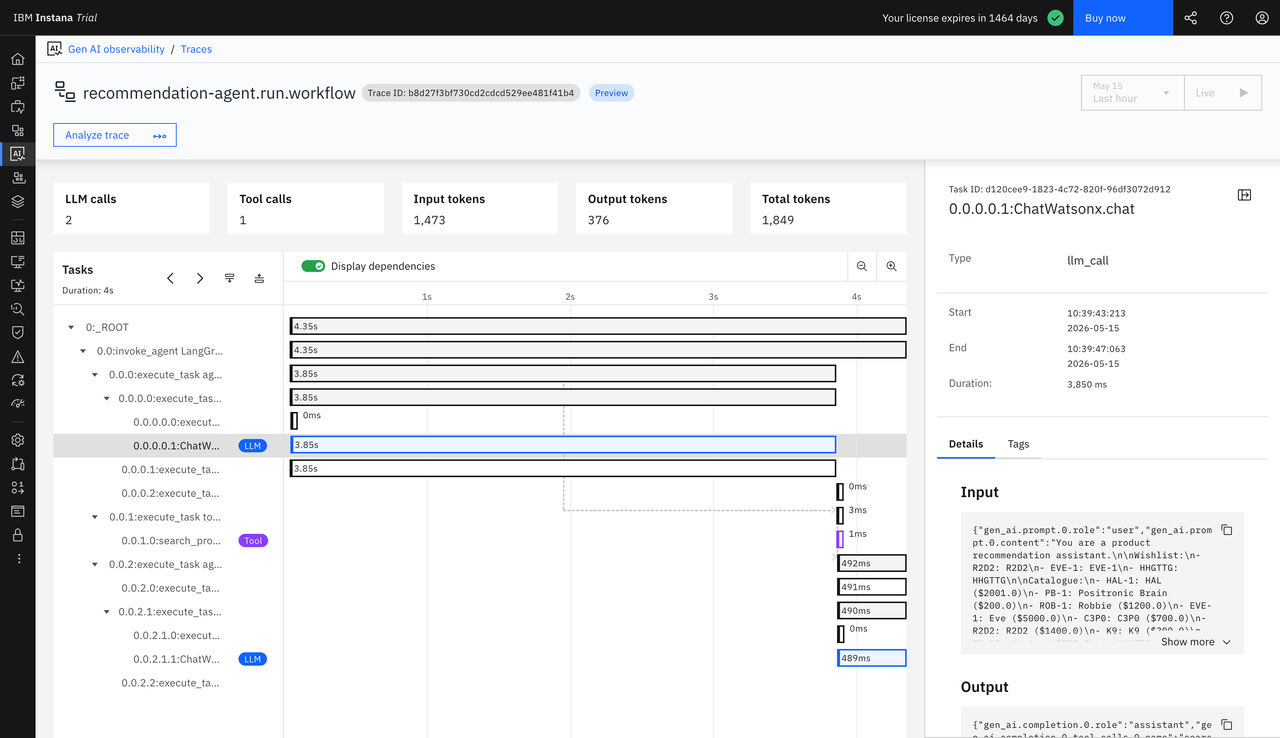
トレース詳細のLLMタスクビュー
LLM呼び出しを含むトレースを表示する際、LLMタスクビューを通じてLLMとのやり取りに関する詳細情報にアクセスできます。 このビューでは、アプリケーションのトレース内における生成AIの処理について、包括的な洞察を得ることができます。
LLMタスクビューへのアクセス
LLMタスクビューを表示するには:
- に移動します。
- LLM呼び出しが含まれるトレースをクリックしてください。
- トレース詳細ビューで、LLMコールスパンを探してクリックします。 LLMタスクビューには、選択したLLMのやり取りに関する詳細情報が表示されます。注: 新しく取り込まれたトレースは 「トレース 」ページに表示されますが、LLMタスクビューにデータが生成・反映されるまで、その後最大1分ほどかかる場合があります。
LLMタスクのビュー情報
LLMタスクビューには、以下の情報が表示されます:
| パラメーター | 説明 |
|---|---|
| モデル名 | この対話に使用された具体的なLLMモデルは、例えば、 gpt-4 または claude-3-opusなどです。 |
| 入力プロンプト | LLMに送信されたプロンプトまたはクエリの全文(システムメッセージやコンテキストを含む)。 |
| 出力応答 | LLMによって生成された回答全文。 |
| 入力トークン | 入力プロンプト内のトークンの数。 |
| 出力トークン | 生成されたレスポンスに含まれるトークンの数。 |
| 合計トークン数 | 入力トークンと出力トークンの合計。 |
| 入力コスト | 入力トークンの処理にかかるコスト。 |
| 出力コスト | 出力トークンの生成に要したコスト。 |
| 合計コスト | LLMとのやり取りにかかる総コスト。これは入力コストと出力コストの合計である。 |
| 期間 | LLMがリクエストを処理し、応答を生成するのに要した時間。 |
| 温度 | LLMの呼び出しに使用されるサンプリング温度。これは出力のランダム性を制御します。 |
| 最大トークン数 | レスポンスで許可されるトークンの最大数。 |
| 上位P | 出力のダイバーシティを制御するために使用される核サンプリングパラメータ。 |
| 周波数ペナルティ | 出力におけるトークンの重複を減らすために適用されるペナルティ。 |
| プレゼンス・ペナルティ | このペナルティは、モデルに新しいトピックについて話させるよう促すために適用されました。 |
LLMタスクビューのメリット
「LLMタスク」ビューでは、以下のことが可能です:
- 正確なプロンプトと応答を確認してLLMとのやり取りをデバッグし、問題や予期せぬ動作を特定します。
- 個々のLLM呼び出しにおけるトークンの使用状況とコストを分析し、コスト削減の機会を特定することで、コストを最適化します。
- アプリケーションのトレース内でLLM操作のレイテンシと応答時間を追跡し、パフォーマンスを監視します。
- 各LLM呼び出しで使用されるパラメータを確認し、それらが出力にどのような影響を与えるかを把握することで、モデルの挙動を理解します。
- アップストリームおよびダウンストリームの呼び出しを含め、アプリケーションのトレース全体の中でLLMとのやり取りを確認してください。