Surveillance de Google Cloud SQL
L'intégration Google Cloud d'Instana utilise des comptes de service pour créer une connexion API entre Google Cloud et Instana.
Pour plus d'informations sur les autres plateformes et services pris en charge par l' Google Cloud, consultez la documentation d' GCP.
Configuration
L'intégration Google Cloud d'Instana utilise des comptes de service pour créer une connexion API entre Google Cloud et Instana.
Suivez les instructions ci-dessous pour créer le compte de service et fournir à Instana les identifiants de ce compte afin qu'il puisse commencer à effectuer des appels vers API en votre nom.
Accédez à la page des identifiants de Google Cloud pour le projet Google Cloud sur lequel vous souhaitez configurer l'intégration Instana.
Cliquez sur CREATE CREDENTIALS > Compte de service.
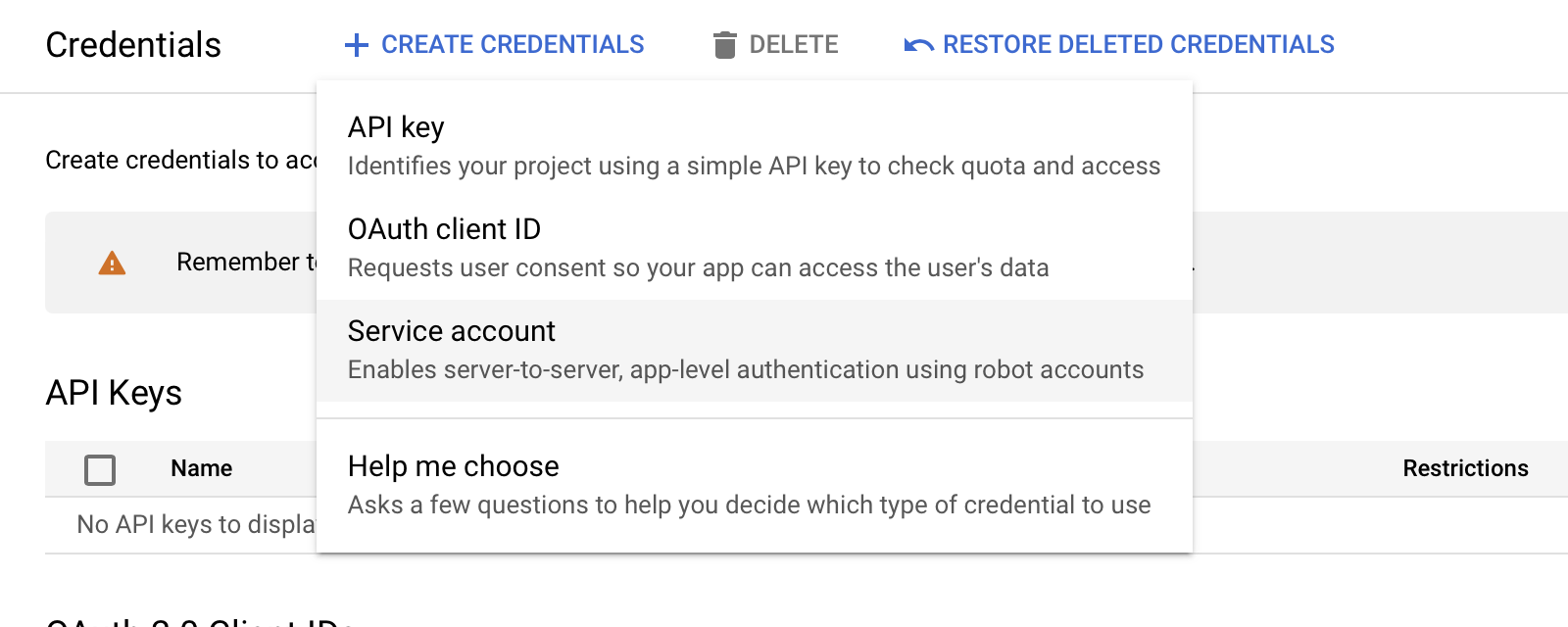
Sur la page Créer un compte de service , entrez un nom unique pour le compte de service et cliquez sur Créer et continuer.
Sélectionnez un rôle ou créez-en un personnalisé contenant au moins les droits suivants:
monitoring.timeSeries.listcloudsql.instances.list
Pour créer un rôle personnalisé, procédez comme suit :
- Dans le menu de navigation, cliquez sur Rôles > Créer un rôle.
- Entrez le titre du rôle et cliquez sur ADD PERMISSIONS.
- Ajoutez les droits de base mentionnés précédemment, qui sont requis pour le rôle, puis cliquez sur Créer.
Sélectionnez le compte que vous avez créé dans la liste des comptes de service.
Sélectionnez l'onglet KEYS et cliquez sur Ajouter une clé.
Sélectionnez « Créer une nouvelle clé », choisissez le type de clé « JSON », puis cliquez sur « CRÉER ».
 Remarque : vous devez noter l'emplacement du fichier d'informations d'identification afin de mener à bien l'intégration.
Remarque : vous devez noter l'emplacement du fichier d'informations d'identification afin de mener à bien l'intégration.Ajoutez une zone
credentials_pathau fichierconfiguration.ymlavec le chemin d'accès au fichier de données d'identification. Par exemple, voir configuration.
Pour surveiller un ou plusieurs projets, les services suivants doivent être activés :
Configuration
Vous pouvez configurer la fréquence d'interrogation des métriques d' Google Cloud SQL, exprimée en secondes, en ajoutant la configuration suivante au fichier de configuration de l'agent GCP :
com.instana.plugin.gcp.sql:
enabled: true
poll_rate: 60 # in seconds
credentials_path: '/opt/instana/credentials/cred-gcp.json' # Path to Service Account credentials
Libellés
L'agent « Instana » récupère automatiquement les étiquettes des instances Google Cloud SQL et les affiche dans la section « Tags » de la barre latérale pour chaque instance Cloud SQL. Vous pouvez utiliser ces étiquettes comme filtres pour trier les ressources sur la carte de l'infrastructure dans l'interface utilisateur d' Instana.
Collecte des métriques
Pour consulter les métriques, sélectionnez « Infrastructure » dans la barre latérale de l'interface utilisateur d' Instana, cliquez sur un hôte surveillé spécifique, puis vous verrez s'afficher un tableau de bord de l'hôte contenant toutes les métriques collectées et les processus surveillés.
Données de configuration
- Version de base de données
- Etat de l'instance
- Région
- Zone
- Niveau
- Type d'instance
- Nom de l'instance maître
- E-S esclave en cours
- SQL esclave en cours
Métriques de performance
| Métrique | Description |
|---|---|
| Disponible pour le basculement | Valeur > 0 si l'opération de basculement est disponible sur l'instance. |
| CPU reserved cores | Nombre de coeurs réservés à la base de données. |
| CPU usage time | Temps d'utilisation de l'UC cumulé en secondes. |
| CPU utilization | Fraction de l'UC réservée actuellement utilisée. |
| Disque utilisé | Utilisation des données en octets. |
| Quota de disque | Taille maximale du disque de données en octets. |
| Disk read operations | Opérations d'E-S de lecture sur le disque. |
| Utilisation du disque | Fraction du quota de disque actuellement utilisée. |
| Disk write ops | Taux d'E-S d'écriture sur le disque. |
| Memory quota | Taille maximale de la mémoire RAM en octets. |
| Utilisation de la mémoire | Utilisation de la mémoire RAM en octets. |
| Memory utilization | Fraction du quota de mémoire actuellement utilisée. |
| MySQL InnoDB buffer pool pages dirty | Nombre de pages non vidées dans le pool de mémoire tampon InnoDB. |
| MySQL InnoDB buffer pool pages free | Nombre de pages inutilisées dans le pool de mémoire tampon InnoDB. |
| MySQL InnoDB buffer pool pages total | Nombre total de pages dans le pool de mémoire tampon InnoDB. |
| MySQL InnoDB data fsyncs | InnoDBfsync() tarif des appels. |
| MySQL InnoDB os log fsyncs | InnoDBfsync() fréquence des appels dans le fichier journal. |
| MySQL InnoDB pages read | Taux de lecture des pages d'InnoDB. |
| MySQL InnoDB pages written | Taux d'écriture des pages d'InnoDB. |
| MySQL queries | Taux d'instructions exécutées par le serveur. |
| MySQL questions | Taux d'instructions exécutées par le serveur envoyé par le client. |
| MySQL replication/seconds behind master | Nombre de secondes de la réplique de lecture derrière son maître (approximation). |
| MySQL sent bytes | Taux d'octets envoyés par le processus MySQL. |
| MySQL received bytes | Taux d'octets reçus par le processus MySQL. |
| PostgreSQL num backends | Nombre de connexions à l'instance Cloud SQL PostgreSQL. |
| PostgreSQL transactions | Nombre de transactions. |
| Network connections | Nombre de connexions à l'instance Cloud SQL MySQL. |
| Network received | Débit d'octets reçus via le réseau. |
| Network sent | Débit d'octets envoyés via le réseau. |
Agrégation
L'option Agrégation permet de combiner des séries temporelles basées sur des statistiques communes. Par conséquent, il y a moins de lignes sur le graphique affichant la métrique, ce qui peut améliorer les performances du graphique. Nous utilisons les options suivantes pour collecter des métriques :
- L'élément d'alignement est
ALIGN_SUM(Aligner les séries temporelles via l'agrégation. Le point de données résultant de la période d'alignement correspond à la somme de tous les points de données de la période). - Réducteur correspond à none (aucun).
- Période d'alignement correspond à une minute.