Surveillance des LLM
Vous pouvez surveiller les métriques et les traces LLM dans l'interface utilisateur d' Instana.
Métriques LLM
Pour consulter les métriques LLM, cliquez sur .
Les indicateurs du LLM, ainsi que leur coût, leur latence et d'autres détails relatifs aux performances, s'affichent dans l'onglet « Indicateurs du LLM ».
| Paramètre | Description |
|---|---|
| Coût des intrants | Le coût lié à l'envoi de jetons d'entrée, c'est-à-dire la requête ou la question adressée aux modèles d'apprentissage profond (LLM). |
| Coût de production | Le coût engendré par les jetons générés par les LLM en réponse à l'entrée. |
| Coût total | Coût total des jetons générés par les LLM en réponse à l'entrée. Le coût est la somme du coût des intrants et du coût des extrants. |
| Modèles | Le nombre de modèles LLM utilisés au cours de la période considérée. Cette valeur reflète la diversité des modèles linguistiques utilisés. |
| Services GenAI | Le nombre de fournisseurs de services d'IA générative ou de points de terminaison utilisés. Chaque modèle peut être hébergé par un service différent, ce qui reflète les variations potentielles en termes de performances et de prix. |
| Appels LLM (total) | Le nombre de fois où les grands modèles de langage (LLM) ont été sollicités, c'est-à-dire le nombre d'interactions de type « invite-réponse » qui ont eu lieu. Cet indicateur montre le niveau d'activité global des modèles. |
| Utilisation des jetons | Utilisation du jeton au fil du temps. Vous pouvez filtrer l'utilisation par modèle LLM ou par service afin de comprendre les habitudes de consommation individuelles ou collectives. |
| Coût | Évolution des coûts au fil du temps pour les modèles LLM. Vous pouvez filtrer les données d'utilisation par modèle LLM ou par service afin d'analyser la rentabilité. |
| Appels LLM | Le nombre d'appels LLM au fil du temps. Vous pouvez consulter la fréquence des invocations de modèles par modèle LLM ou service afin d'identifier les périodes d'utilisation maximale. |
| Latence LLM | La latence des appels LLM au fil du temps. Cet indicateur mesure le temps de réponse de chaque modèle, indiquant ainsi la rapidité avec laquelle les modèles génèrent des résultats. |
| Nom du modèle | Le modèle LLM utilisé. |
| Jetons d'entrée | Le nombre de jetons dans les invites ou les requêtes envoyées au LLM. |
| Jetons de sortie | Le nombre de jetons générés par le LLM en tant que réponses. |
| Nombre total de jetons | La somme des jetons d'entrée et des jetons de sortie, représentant le nombre total de jetons pour chaque interaction. |
| Coût total | Dépenses totales pour les jetons générés par les LLM. |
| Temps de latence (moyenne) | Temps de réponse moyen du LLM pour tous les appels. |
| Nombre d'appels | Le nombre total de fois où le LLM a été appelé ou invoqué. |
Traces LLM
Pour consulter les traces LLM, cliquez sur .
Les traces du modèle LLM, y compris les invites d'entrée et les réponses générées, s'affichent dans l'onglet « Traces ».
| Paramètre | Description |
|---|---|
| ID de la trace | Un identifiant unique attribué à chaque trace ou interaction avec le système d'IA générative. Cela s'avère utile pour suivre et déboguer des requêtes spécifiques. |
| Service d'IA générative | Le service d'IA générative utilisé pour traiter la requête. |
| Invite de saisie | La question ou la commande soumise au modèle d'IA. |
| Réponse de la sortie | La réponse générée par le modèle d'IA en réponse à la requête saisie. |
| Nombre total de jetons | Nombre total de jetons utilisés dans l'interaction, y compris les entrées et les sorties. |
| Durée | Le temps nécessaire au modèle d'IA pour générer la réponse, mesuré en millisecondes. Cette valeur permet d'évaluer les performances et la latence. |
| Statut | Indique si l'interaction a été réussie. Une coche verte indique que la réponse a été générée avec succès, sans erreur. |
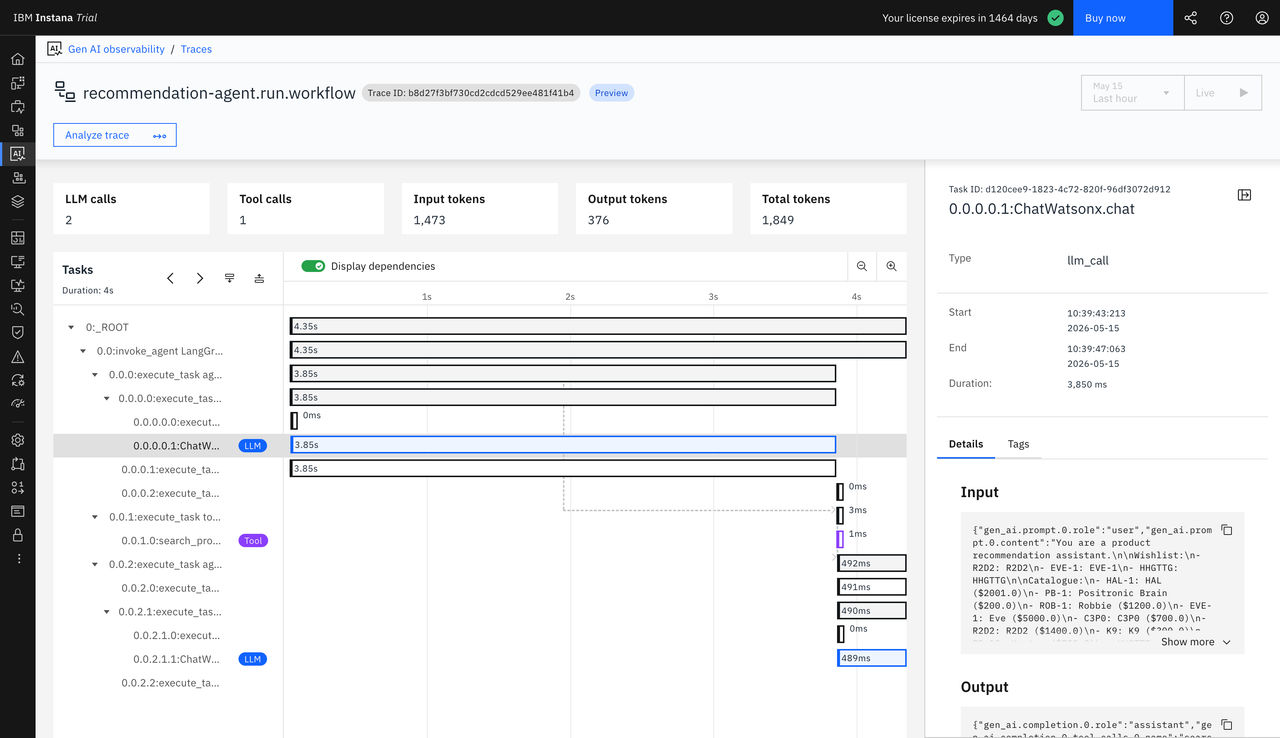
Vue des tâches LLM dans les détails de la trace
Lorsque vous consultez une trace contenant des appels LLM, vous pouvez accéder à des informations détaillées sur les interactions LLM via la vue « Tâches LLM ». Cette vue offre un aperçu complet des opérations d'IA générative au sein des traces de votre application.
Accéder à la vue « Tâches LLM »
Pour accéder à la vue « Tâches LLM » :
- Accédez à .
- Cliquez sur une trace contenant des appels LLM.
- Dans la vue des détails de la trace, repérez un intervalle d'appel LLM et cliquez dessus. La vue des tâches du LLM affiche des informations détaillées sur l'interaction LLM sélectionnée.Remarque : une trace nouvellement importée apparaît sur la page « Traces », mais la génération et le remplissage des données dans la vue des tâches du LLM peuvent prendre jusqu'à une minute.
Informations sur la vue des tâches LLM
La vue « Tâches LLM » fournit les informations suivantes :
| Paramètre | Description |
|---|---|
| Nom du modèle | Le modèle LLM spécifique utilisé pour l'interaction, par exemple, gpt-4 ou claude-3-opus. |
| Invite de saisie | La requête complète envoyée au modèle de langage de grande capacité (LLM), y compris les messages système et le contexte. |
| Réponse de la sortie | La réponse complète générée par le modèle de langage (LLM). |
| Jetons d'entrée | Le nombre de caractères dans la ligne de commande. |
| Jetons de sortie | Le nombre de jetons dans la réponse générée. |
| Nombre total de jetons | La somme des jetons d'entrée et de sortie. |
| Coût des intrants | Le coût lié au traitement des jetons d'entrée. |
| Coût de production | Le coût lié à la génération des jetons de sortie. |
| Coût total | Le coût total de l'interaction avec le LLM, qui correspond à la somme des coûts d'entrée et de sortie. |
| Durée | Le temps nécessaire au LLM pour traiter la requête et générer la réponse. |
| Température | La température d'échantillonnage utilisée pour l'appel du LLM, qui contrôle le caractère aléatoire de la sortie. |
| Nombre maximal de jetons | Le nombre maximal de jetons autorisés dans la réponse. |
| Top P | Le paramètre d'échantillonnage du noyau utilisé pour contrôler la diversité de sortie. |
| Pénalité de fréquence | La pénalité appliquée pour réduire la répétition des jetons dans la sortie. |
| Pénalité de présence | La pénalité a été appliquée pour inciter le modèle à aborder de nouveaux sujets. |
Avantages de la vue « Tâches » de LLM
La vue « Tâches » de LLM vous aide à :
- Déboguez les interactions avec les modèles de langage (LLM) en examinant les invites et les réponses exactes afin d'identifier les problèmes ou les comportements inattendus.
- Optimisez les coûts en analysant l'utilisation des jetons et les coûts associés à chaque appel au modèle de langage (LLM) afin d'identifier les possibilités d'optimisation.
- Surveillez les performances en suivant la latence et les temps de réponse des opérations LLM au sein des traces de votre application.
- Comprenez le comportement du modèle en examinant les paramètres utilisés pour chaque appel au LLM afin de comprendre comment ils influencent le résultat.
- Consultez les interactions LLM dans le contexte de la trace complète de l'application, y compris les appels en amont et en aval.