Fonctionnement de SVM
SVM fonctionne par mappage des données à un espace d'attributs haute dimension pour que les points de données puissent être classés, même lorsque les données ne sont pas séparables sur un plan linéaire. Un séparateur entre les catégories est identifié. Ensuite, les données sont transformées de sorte que le séparateur puisse être défini comme un hyperplan. Ensuite, les caractéristiques des nouvelles données peuvent être utilisées pour prédire le groupe auquel un nouvel enregistrement doit appartenir.
Par exemple, prenez la figure suivante, dans laquelle les points de données rentrent dans deux catégories différentes.
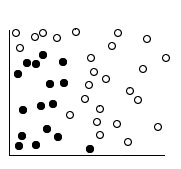
Les deux catégories peuvent être séparées par une courbe, comme illustré dans la figure suivante.
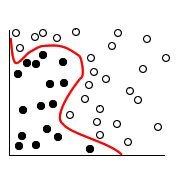
Une fois la transformation effectuée, la limite entre les deux catégories peut être définie par un hyperplan, comme illustré dans la figure suivante.
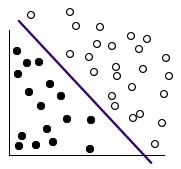
La fonction mathématique utilisée pour la transformation est appelée fonction noyau. SVM dans IBM® SPSS Modeler prend en charge les types de noyaux suivants :
- Linéaire
- Polynomial
- Fonction radiale de base (RBF)
- Sigmoïde
Une fonction noyau linéaire est recommandée lorsque la séparation linéaire des données est simple. Dans les autres cas, l'une des autres fonctions doit être utilisée. Vous devrez tester les différentes fonctions pour obtenir le meilleur modèle dans chaque cas, comme ils utilisent des algorithmes et des paramètres différents.