Iterative scaling
Once the first level of scaling is achieved successfully, you can
then attempt to scale to the next level and then continue iteratively
until you reach your scaling goals. To continue to use the sample
application as an example, the next appropriate deployment might be
to again scale up the event processing flow instances by adding a
second execution group:
Figure 1. Multiple instance deployment example
After scaling up, revaluate performance and use instrumentation and trace tools to capture and evaluate
work breakdown costs. In this deployment topology it is likely that the performance has not scaled as much as
before because we now have a significant bias towards the event processing threads such that the physical
transmission flows cannot keep pace. This might be apparent when the system has not scaled as expected and you
have allocated more thread instances to one part of the process than original calculations suggested and you
can see no other evidence of process degradation. If this occurs, consider the system resource utilization and
either reduce the thread instances of suspected over allocated resources or increase those of suspected under
allocated resources. It is worth experimenting with deployments that go beyond the originally calculated value
because that value should only be used to seed the search for the optimal configuration. In the context of the
sample application it is more likely that a deployment ratio of 9 event threads to 1 transmission thread is
closer to optimal. The following figure shows an x2 scaled deployment example with three event processing
execution groups (18 threads total) and one additional instance on the transmission wrapper flows.
Figure 2. x2 scaled deployment example
As mentioned earlier, scaling is an iterative process. The following figure illustrates the key points
in this process. Figure 3. Scaling process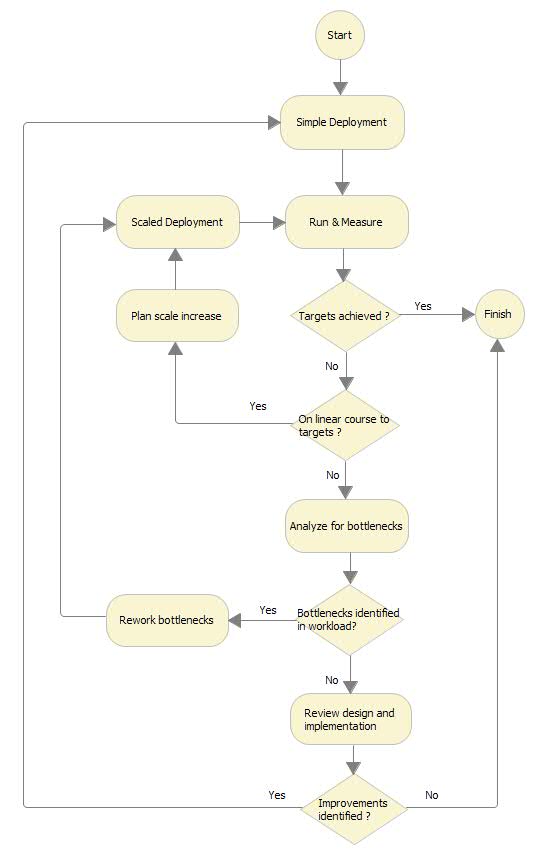
One key thing that this process diagram does not try to cover is what to do if you fail to meet your
targets but can't identify further improvements (this is the 'No' path back to 'Finish'). This path implies
that the solution is in your opinion optimally designed and implemented and that the system resources are
being fully utilized but the required performance is missed. In this case you have a number of options: - Accept the performance (especially if it is close to target)
- Simplify the business case to remove some process cost if possible
- Source more system resources (that is scale vertically or horizontally beyond original expectations)
- Seek further expertise to analyze the application performance