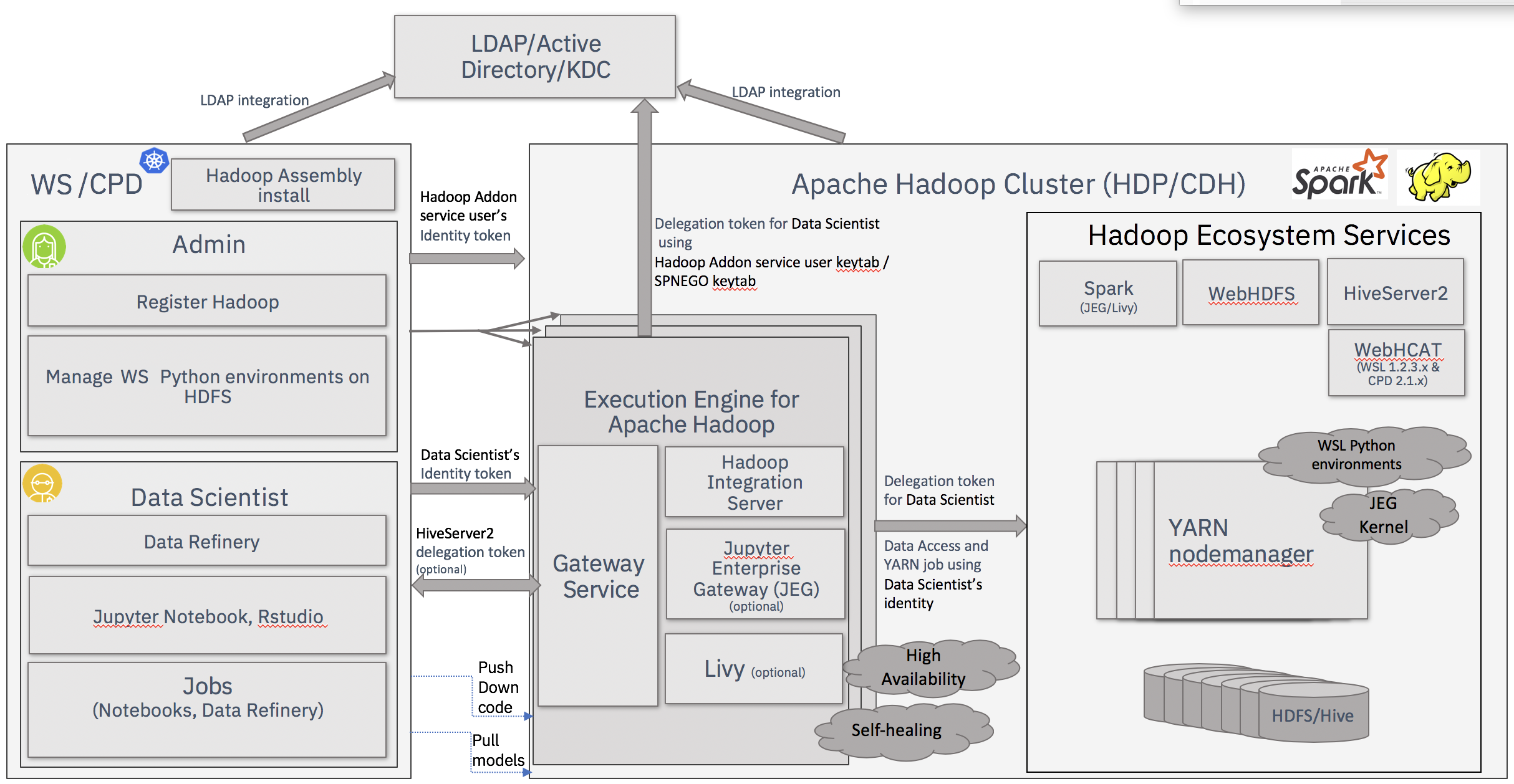
Administering Execution Engine for Apache Hadoop
Administering the service involves tasks for both the Cloud Pak for Data clusters and Hadoop clusters. For example, after the Execution Engine for Apache Hadoop service is installed, you’ll need to register the Hadoop cluster on the Cloud Pak for Data cluster. Administering the Hadoop clusters includes tasks, such as managing the status of the service and access to the service.
Administering tasks also include backing up the Execution Engine for Apache Hadoop service. Backing up the service means creating snapshots of persistent volumes that are used by the service to preserve configurations, running jobs, and build artifacts. See Backup and restore for more information.