IBM Storage Scale Architecture Overview
Features
IBM Storage Scale for Linux on IBM Z is available in the Data Management Edition and the Data Access Edition. For more details regarding the differences between Data Management Edition and Data Access Edition refer to https://www.ibm.com/docs/en/storage-scale/5.1.9?topic=overview-storage-scale-product-editions
The Data Management (Advanced) Edition and Data Access (Standard) Edition provide the following features:
- Installation toolkit
- Call home support
- Improved storage efficiency with file compression at rest
- IBM Storage Scale encryption at rest
- IBM Storage Scale GUI running on Linux on IBM Z nodes
- Information lifecycle management (ILM)
- Active file management (AFM) for active/active configurations
- Support extension for IBM Spectrum Protect backup & archive and space management
- Stretched cluster with synchronous mirroring with distances of less than 300 km
- Asynchronous multisite disaster recovery (DR) at the fileset level
- Storage tiering, enabling flash, and traditional storage tiering
- Data tiering, enabling active data on fastest storage devices
- Transparent Cloud Tiering (TCT), enabling Cloud Data Sharing in Cloud services
- Watch Folder and Cluster Watch (Enhanced Folder Watch)
- File Audit Logging
- Remote cluster mount (multi-cluster support)
- Enabled for Containers Storage Interface (CSI)
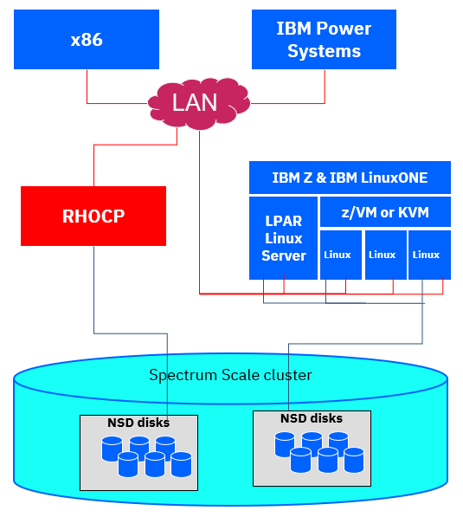
IBM Storage Scale is intended for workloads where performance, reliability, and availability of data are essential to the business. With IBM Spectrum Scale, it is a natural fit to share data across different systems and architectures such as x86, IBM Power Systems, IBM Z, and IBM LinuxONE environments.
The advantages for the data are the following IBM Storage Scale capabilities:
- With data tiering, store data that is based on usability policies and access frequency
- Tiering can span from local storage systems to cloud storage
- Tiering can include automatic backup and archive of data to tape
- Can host file systems for traditional applications and container storage
- The read / write / multiple characteristics ensures integrity for shared container persistent volumes
On IBM Z, you can manage and access files through Linux instances running in logical partitions (LPAR) or virtualized on z/VM® and KVM.

Use cases
IBM Storage Scale represents the most comprehensive software defined storage solution for shared storage and data requirements, including access prioritization and resiliency. It is available for hybrid, multi-architecture environments on prem and hybrid clouds, including container workloads managed by Red Hat Openshift Container Platform on IBM Z. With IBM Storage Scale you can establish a globally shared enterprise data pool across different hardware and software architectures. That leads to a wide range of use cases for shared data in the enterprise.
Storage hub for the enterprise
A storage hub based on IBM Storage Scale is a software-defined storage architecture. It helps enterprises consolidate a controlled sharing solution for data across workloads and environments in different hardware architectures. Converting your storage infrastructure into a data hub will greatly streamline data flow and control across your organization.
For today’s enterprises, the data flow is the highway to the future of data insights and artificial Intelligence (AI). Why is it so hard for storage systems to unify data on a single platform? The problem is that each application has different requirements for its data to be unified, separated, or delivered.
A data hub is designed on first principles to reduce the data silos and enable the same data to be accessed by multiple applications at the same time with full data integrity. Delivering data means each application has the full performance of data access that it requires at the speed of today’s business.
The Benefits of a storage hub with IBM Spectrum Scale:
-
Consolidation of silos into a single unified interface for all your data
-
A storage hub even across data lakes or hybrid multi cloud
-
Automatic tiering: Always have the most used data on fastest disks
-
High-speed, high-throughput, and high-performance data pipelines
-
A unified data storage management interface
-
Consistent tooling and resiliency
-
Integrated metro and global HA and replication
Data gravity and global data lake
A key advantage of RHOCP on the IBM Z platform is the co-location of containerized applications with traditional workloads. Traditional workloads can be data lakes, databases, transactional systems, or other traditional workloads running in Linux on IBM Z or z/OS®. In such a scenario the applications can be located close to the data to optimize latency, response time, deployment, security, service, and cost. In combination with Oracle databases, for example, the resulting synergy can dramatically improve the Total Cost of Ownership (TCO).
Hybrid multi cloud storage pool
A hybrid multi cloud environment can be composed of cloud solutions, which require shared storage and shared data across different environments. It can be in a single cloud with multiple RHOCP clusters sharing the same storage and data, with rules for data tiering and backup. It can also fulfill requirements for high isolation of multi-tenant implementations. Similarly, the requirements to share data across architectures like IBM Z, x86, and IBM Power Systems can be fulfilled with a storage solution using IBM Spectrum Scale.
In addition, the IBM Storage Scale implementation enables shared storage between public clouds and on-prem clouds or data lakes, with the security and reliability needed, ensuring high performance and highest scalability.
With IBM Spectrum Scale, an overall software defined storage solution is available that also includes tiering for data placement priorities. It is complemented with functions for a controlled HA topology, which can be a metro distant active-active environment. Or it can span geographical regions for asynchronous replication, disaster recovery (DR) and availability zoning. These concepts are available independent of the local or cloud environments that share the data stored in IBM Storage Scale clusters. In addition, resiliency can also contain the backup and archive process that is based on software defined rules and conditions. Once defined it automatically enhances the resiliency of HA and DR. On IBM Z an exclusive feature is the integration of IBM Storage Scale with the industry leading General Dispersed Parallel Sysplex (GDPS®) feature for IBM Z. In conjunction with the extended disaster recovery feature (xDR) for Linux on IBM Z, it enables a fully automatic recovery of Linux guests and application data in an IBM Z environment. It is complemented with the transparent switch between storage servers in case of a storage pack failure and a failover to a second datacenter in case of a disaster.
IBM Storage Scale on IBM Z components
The IBM Storage Scale cluster components consist of software components and the physical storage attached. The major software components in IBM Storage Scale are:
-
IBM Storage Scale GUI component: For setup, management, and operation
-
IBM Storage Scale Network Shared Disks (NSD) server nodes (NSD servers): Cluster nodes with direct shared disk access. For example, DASD devices or SCSI disks (See paragraph 2.3.1)
-
IBM Storage Scale NSD client nodes (NSD clients): Cluster nodes with storage access via the NSD server nodes
-
IBM Storage Scale Cluster Export Services (CES): Cluster Export Services (CES) provides highly available file and object services to an IBM Storage Scale cluster by using different protocols such as Network File System (NFS).
IBM Storage Scale provides concurrent access to a single file system or a set of file systems from multiple nodes. The nodes can be SAN attached, network attached, a mixture of SAN attached and network attached, or in a shared nothing cluster configuration.
Due to a High Availability (HA) implementation per design, it can be implemented using HA quorum concept, which requires an odd number of IBM Storage Scale nodes. The minimum is three. It can also use an HA implementation using a tie breaker disk for high availability, which can be implemented with an even number of IBM Storage Scale nodes. The minimum is two.
IBM Storage Scale for Linux on IBM Z supports the following components and storage:
- Extended count key data (IBM ECKD™) direct access storage device (DASD) disks and Fixed Block Architecture (FBA) disks
- Fiber Channel Protocol (FCP) attached Small Computer System Interface (SCSI) disks.
- IBM Enterprise Storage Server® (ESS) a preconfigured IBM Storage Scale cluster storage appliance using Ethernet/IP.
IBM Storage Scale nodes on Linux on IBM Z can communicate through internal networks, for example, HiperSockets™ within one physical machine. Thus, providing high-speed IP network communication, it can have better file system performance, especially in Network Shared Node (NSD) client/server model (See paragraph 2.3.2). The HiperSockets devices in two IBM Z and IBM LinuxONE servers respectively can be connected through a HiperSockets Bridge. Each clustered file system has metadata. IBM Storage Scale uses a distributed approach versus other clustered file systems that require a centralized metadata server. This can become a performance bottleneck for metadata-intensive operations and can represent a single point of failure.
IBM Storage Scale manages metadata at the node that uses the file or, in the case of concurrent access to the file, at a dynamically selected node that uses the file.
IBM Storage Scale cluster configurations
IBM Storage Scale for Linux on Z supports the following cluster configuration models:
-
The direct shared-disk model, where the cluster nodes can access a set of disks directly.
-
The Network Shared Disk (NSD) client/server model, where the shared-disk model is extended by mixing direct SAN access with network-attached cluster nodes. Network-attached cluster nodes access storage over a network connection.
Depending on the cluster configuration, you must plan for the underlying infrastructure (storage and network) and the appropriate configuration to ensure the required performance and reliability.
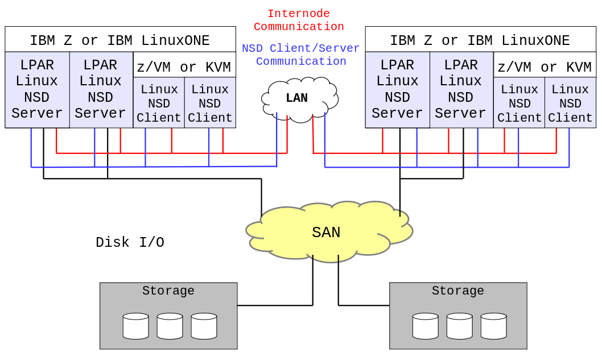
Direct shared-disk model
The characteristics of the direct shared-disk model are:
- Every cluster node has direct access to the storage disks in the SAN.
- Internode communication is through normal network connections.
The main advantage of using a disk configuration that directly attaches and accesses the data is that IBM Storage Scale does not need to use the network to send disk data from one cluster node to another. Hence this architectural model achieves a better performance than the NSD client/server model.

Network shared disk (NSD) client/server model
The characteristics of the network shared disk client/server model are:
- Some of the cluster nodes have direct access to the storage disks in the SAN and act as an NSD server to serve disk I/O operations for NSD clients.
- Other cluster nodes are defined as NSD clients and access data over a network connection through an NSD server node. In this case, besides the disk I/O through the SAN, the cluster nodes use network access to the NSD servers via NSD network protocol.
- Internode communication is still through normal network connections.
Compared to the shared-disk model, only a couple of cluster nodes have direct access to the data disks. When an NSD client node needs to read or write to a disk, IBM Storage Scale transfers the I/O request to an NSD server node. The node will then, for example, write it directly to the disk. The network in an NSD client/server configuration is heavily used for each read and write request of NSD client nodes. Thus, a very high-speed network with low latency should be used for the best performance.
If an NSD client cannot access an NSD server due to a server failure, and thereby cannot access a disk, IBM Storage Scale suspends using the disk. You must implement disk connectivity on multiple NSD server nodes and specify multiple NSD servers for each disk to guard against loss of NSD server availability. In this case IBM Storage Scale dynamically switches to the next available NSD server and continues to provide data. You can also set up an NSD client node with both direct access to the data disks through the SAN and access to the disks through an NSD server node. If direct access is lost, for example due to a SAN problem, the data access is assured through the available NSD server.
Heterogeneous clusters are limited to the following: You can set up a heterogeneous cluster with x86 servers and POWER® servers running Red Hat Enterprise Linux or SUSE Linux Enterprise Server. These cluster nodes must be configured as NSD clients to access storage on Linux on Z cluster nodes. Do not share storage among different platforms, for example, by using local storage access.
You can set up a heterogeneous cluster with x86, POWER, and IBM Z running Windows, AIX®, Red Hat Enterprise Linux, and SUSE Linux Enterprise Server. The cluster nodes can serve as NSD servers to access their local platform-dependent storage. However, for Linux on Z, SAN-attached disks can only be accessed from Linux on Z cluster nodes. Mainframe ECKD storage cannot be shared among different platforms.
Topology options - cross cluster mount and integrated topology
The most common implementation topologies of an IBM Storage Scale cluster are:
-
integrated topology – with the IBM Storage Scale cluster integrated into the application environment and part of the application server nodes
-
remote mount or cross cluster mount topology - taking advantage of the capability to use an established IBM Storage Scale cluster. The file system is mounted to different IBM Storage Scale clusters with different architectures and applications using different available APIs.