Storage concepts
Adding persistence to containerized workloads
Containers are a powerful concept to simplify application deployment and operation dramatically. Containers are small, lightweight bundles. They include the subset of the operating system that they need.
- Containers avoid the deployment of a full copy of an operating system on each container.
- Containers package all required dependencies, such as runtime environments or libraries.
As a result, a customer deployment faces significantly fewer integration problems because containers can run about anywhere.
Furthermore, containers assume a simplified lifecycle. This makes orchestrating a containerized workload easy. A container can be restarted, scaled up and down, or moved back and forth between servers at any time.
However, this flexibility and ease comes at a price. The simplified lifecycle assumes that containers run stateless without any persistence after exiting or restarting a container all data in it is lost. It is the responsibility of the application workload to take care of storing data on its own.
When storing a containerized workload’s data, a customer needs to consider how storage can be easily provided, mounted, and scaled. Kubernetes provides some basic capabilities to help here. Among those capabilities, the most notable are persistent volumes and claims, storage classes and a set of operators to deal with storage.
But for larger enterprise scale applications a customer will soon conclude that a more overarching and consistent approach is needed. To address this, various kinds of software-defined storage offerings build powerful infrastructure around the basic Kubernetes capabilities. Products such as IBM Fusion Data Foundation or IBM Storage Scale feature a nice separation of storage hardware from the consuming software layers, which makes development easier. They also facilitate high availability and the scaling of storage hardware for serious production use.
Container-ready and container-native storage
For containerized applications and services, there are two kinds of storage for those that require stateful applications and long-term data persistence.
- Container-ready
- Container-native storage
Container-ready storage includes Storage Area Network (SAN), Software-Defined Storage (SDS), and Network Attached Storage (NAS) devices. These devices support capabilities such as backups, snapshots, clones, and data replication. As container-ready storage they continue to operate in their environments unchanged and independently of the containerized workload itself. The storage environment and the OpenShift Container Platform cluster co-exist next to each other.
A benefit of choosing any of these options is that they often allow clients to use their existing infrastructure investments in networking or storage. Existing processes for management, scaling, and monitoring can be used.
The alternative is container-native storage. Container-native storage types are already deployed within containers and are presented to containerized applications as ready-to-go storage. Processes for deployment, management, and scaling are similar for storage and applications as both are containerized.
Productized versions of container-native storage include IBM Fusion Data Foundation based on Red Hat OpenShift Container Platform.
What benefits do container-native storage provide? Container-native storage simplifies management by offering a single control plane within your entire Kubernetes containerized environment and the ability to manage the integrated storage similar to the application workload. At the same time, this architectural paradigm allows storage and compute nodes to scale independently of one another.
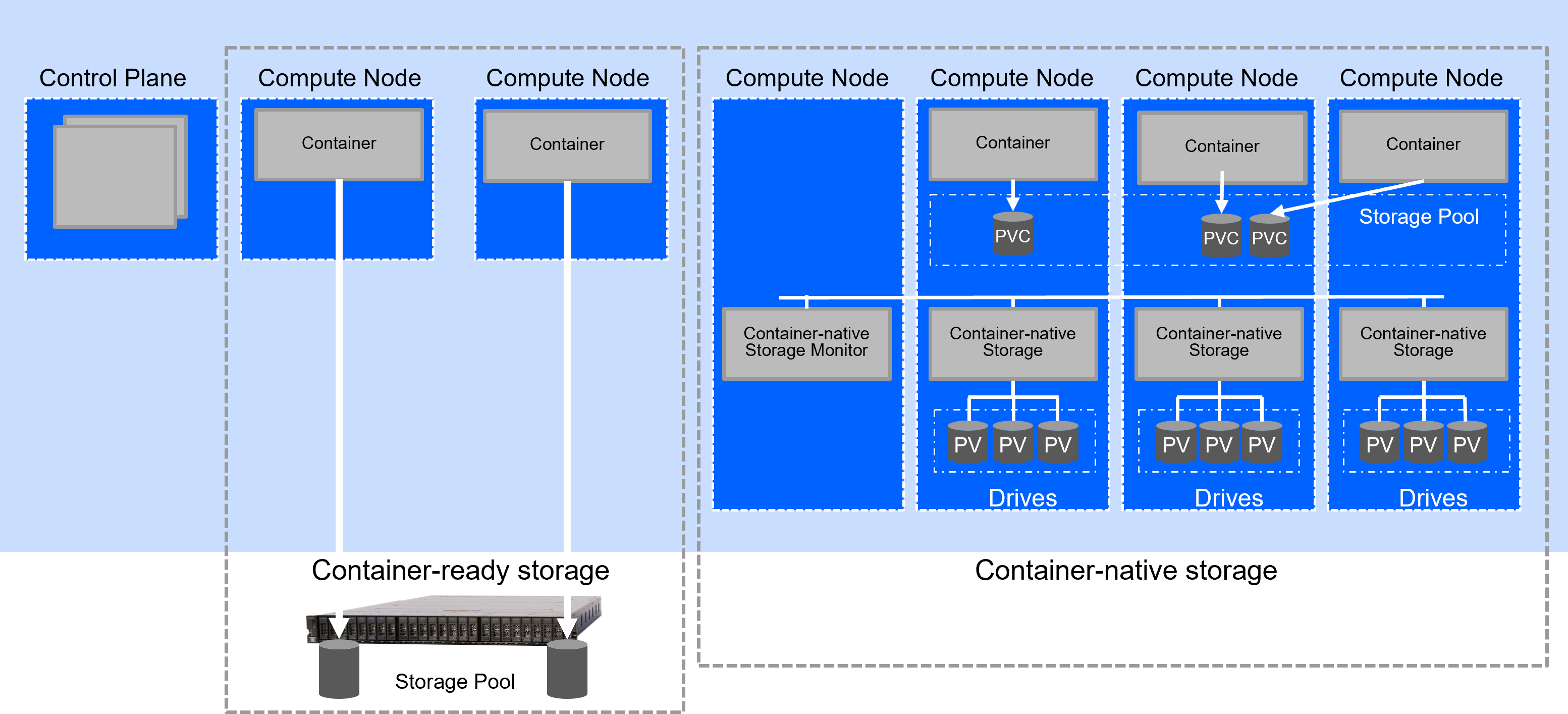
In IBM Fusion, it is possible for container-ready and container-native storage to coexist within the same cluster, giving further flexibility to clients who might have a mixture of persistence options available. This co-existence is shown in Figure 1.
- Container-ready storage connects the Red Hat OpenShift compute nodes directly to the storage devices via a fabric of APIs and provisions volumes directly on the storage device.
- By contrast, container-native storage devices consume storage either as disk drives or external storage. Container-native storage creates a new abstracted storage pool, which is managed and scaled as containers in a Kubernetes or Red Hat OpenShift environment. That storage pool is used to create persistent volumes, which is used by the application containers.
Persistent volume claim and persistent volume
Adding persistence to a containerize application in a Kubernetes-based environment such as Red Hat OpenShift, boils down to a simplistic approach and concept.
- One the one hand, developers use Persistent Volume Claims (PVCs) to request that the storageresources they need for their applications. This PVC is an abstraction of the storage, which is available to applications, and declares how much and what kind of storage the consumer needs. PVC is a common Kubernetes concept, and IBM Fusion Data Foundation takes advantage of this concept.
- On the other hand, the storage administrator provisions storage for the cluster as persistent volumes (PV). PV resources on their own are not scoped to any single project. They can be shared across the entire OpenShift Container Platform cluster and claimed from any project.
- Under the hood, a software-defined storage infrastructure dynamically binds the claims to the actual available storage. It maps the physical storage to the needs of the developer. If you bind a PV to a PVC, that PV cannot be bound to additional PVCs. Each PV represents a piece of existing storage in the cluster that was either statically provisioned by the cluster administrator or dynamically provisioned.
This simple fundamental concept makes storage easy to deploy, use, and administer.
