Introducing IBM Fusion and IBM Fusion Data Foundation
Usually, adding persistence to a containerized application is a necessary task. You can achieve this yourself by building directly on Kubernetes concepts. But this typically leads to variations in capability, functionality, and performance from storage to storage. For enterprise-ready applications, you generally need a more powerful and consistent infrastructure layer. This is where the combination of IBM Fusion, Red Hat OpenShift Container Platform, and IBM Fusion Data Foundation help you.
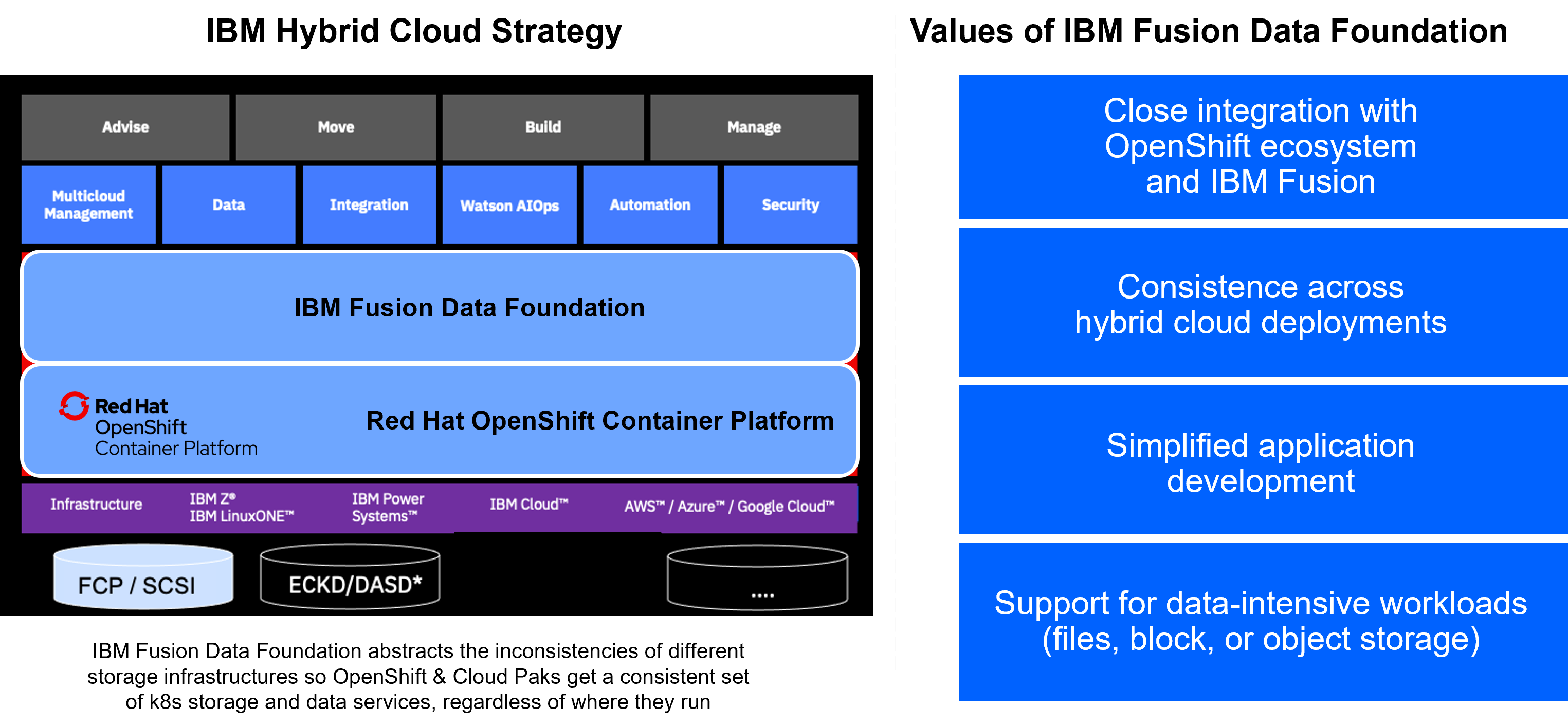
IBM Fusion is a powerful infrastructure to add persistence to containerized workloads. It is IBM’s strategic offering for container native software-defined storage. IBM Fusion is based on Red Hat® OpenShift® and includes two options for storage infrastructure, which can be combined as needed:
- IBM Storage Scale, which is based on GPFS file Storage. IBM Storage Scale excels when dealing with large amount of unstructured data, which is globally distributed. The perfect scenarios for AI, Big Data Analytics, or any other high-performance workload. IBM Storage Scale just scales amazingly well! As a global data platform, IBM Storage Scale makes data available wherever it is needed, without redundant copies, which would be hard to manage. Nice features allow to define multiple tiers of data access. Disaster recovery and high availability are thought-through. Another aspect to highlight is the large number of supported protocols, which can be used by an application when dealing with storage. In short, IBM Storage Scale features high-performance parallel data access with enterprise data services connecting edge to core to public cloud in a single federated cluster.
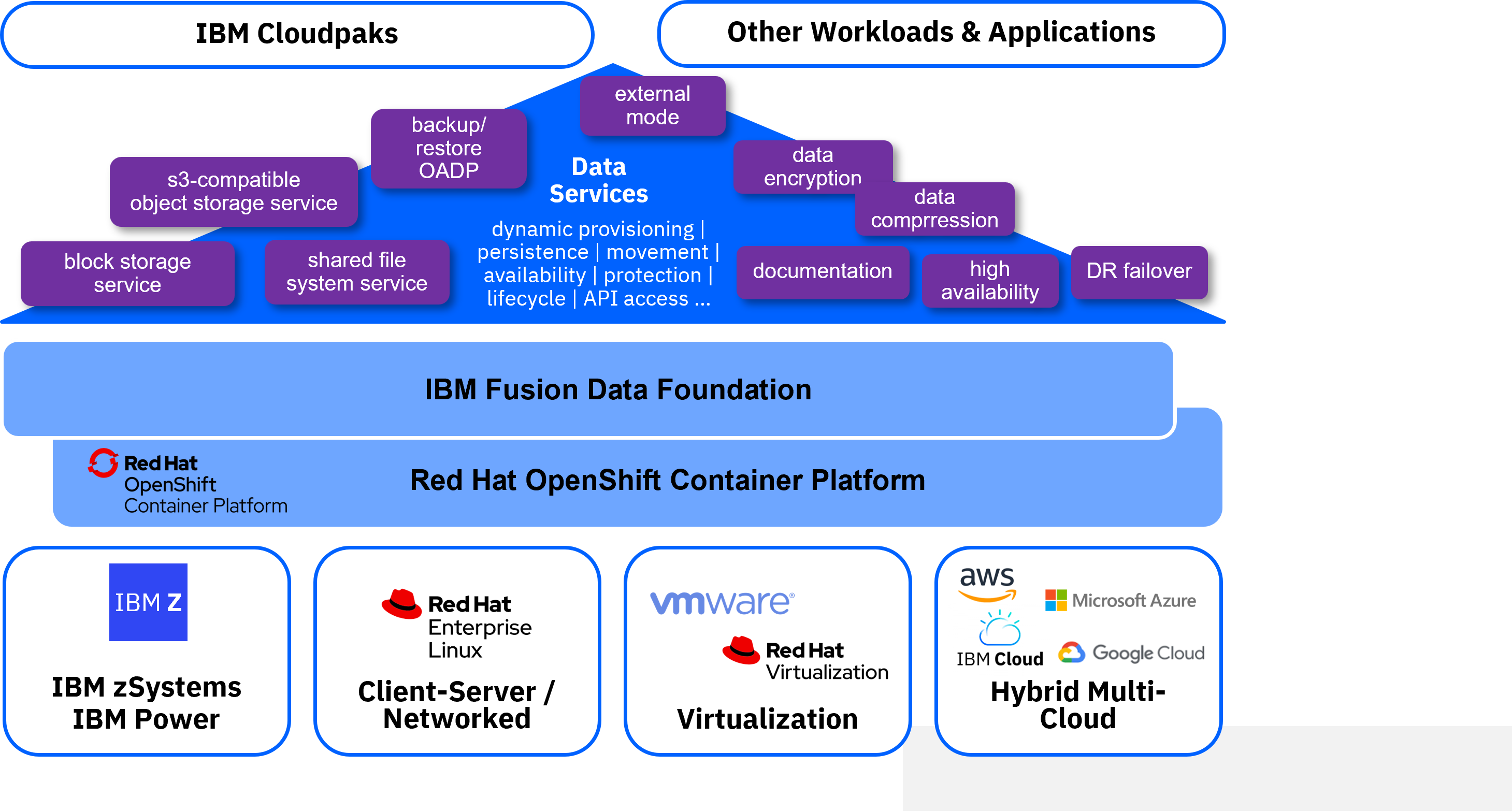
- IBM Fusion Data Foundation, which is also known as Red Hat OpenShift Data Foundation, is based on open source Ceph® storage. The key values of IBM Fusion Data Foundation are ease-of-use and simplicity, as it is based on standard Kubernetes skills and optimized to run stateful containerized applications. IBM Fusion Data Foundation includes a set of storage and data services running in Red Hat OpenShift and abstracting the underlaying physical storage devices. It delivers highly scalable production-grade persistent storage in a uniform way, regardless of where the actual physical storage resides. Fusion Data Foundation works the same on any platform, which makes it perfect for hybrid cloud solutions. It also supports all three relevant storage classes object, file, and block storage. As Fusion Data Foundation is part of the Red Hat OpenShift family, it is nicely integrated into the Red Hat OpenShift ecosystem – both from administration as well as development point of view.
IBM Fusion adds a unified installation and configuration experience on top of IBM Fusion Data Foundation and IBM Storage Scale, featuring a common user experience. IBM Fusion focuses on consumability. For example, it features common operational procedures for disaster recovery or deployment, regardless which storage infrastructure you choose. In addition, IBM Fusion adds services of its own. For example, a backup/restore service, which can protect the data that is stored in the underlying infrastructure.
- While IBM Fusion includes both IBM Storage Scale and IBM Fusion Data Foundation as choice for the underlying storage infrastructure, this document focuses on the later only.
- IBM Fusion is available as software offering, which can be deployed on IBM® LinuxONE and on IBM z/OS Container Extensions (zCX). It is also available as an external hardware appliance, which is branded as IBM Fusion HCI.
- Subscriptions for IBM Fusion Data Foundation can be purchased from IBM as part of IBM Fusion or from Red Hat (branded as Red Hat OpenShift Data Foundation and subscribed from Red Hat). While this document primarily uses the IBM branding IBM Fusion Data Foundation, all content applies to Red Hat’s Red Hat OpenShift Data Foundation as well (unless noted otherwise).
The key characteristics of IBM Fusion Data Foundation are:
- Based on open source and implemented consistently across multiple architectures.
- Enables hybrid cloud portability.
- Dynamic provisioning of extra storage as needed by the application workload.
- Closely integrated with the Red Hat OpenShift ecosystem.
- Abstracts details of a distributed physical storage infrastructure and exposes a single logical storage service.
- Based on a common set of skills and well-known industry best practices.
- Simplifies application development and infrastructure administration by being integrated into the Red Hat OpenShift user experience.
- Supports any kind of data-intensive workload regardless of whether the data is stored as files, block or object storage.
- Can be deployed on IBM Z and IBM® LinuxONE or within IBM z/OS Container Extensions (zCX).
- Part of IBM Fusion, the strategic platform for container native storage.
- The principal role of IBM Fusion Data Foundation is to provide uniformity to any consuming application or Cloud Pak, regardless of where they run. Clients can deploy and consume storage wherever it is needed: regardless of whether it is on premises or in a cloud environment.
- IBM Fusion Data Foundation separates hardware provisioning and administration from software-based consumption by developers. Furthermore, IBM Fusion Data Foundation can deal with all kinds of storage classes.