Considerations for backup and restore
A Red Hat OpenShift cluster is focused on delivery containerized workload. Each application is built from self-contained containers, which are orchestrated by Kubernetes. As part of that orchestration containers are scaled up and down or moved between cluster nodes (pods). From a Kubernetes perspective, application instances can be re-created at any time within any cluster.
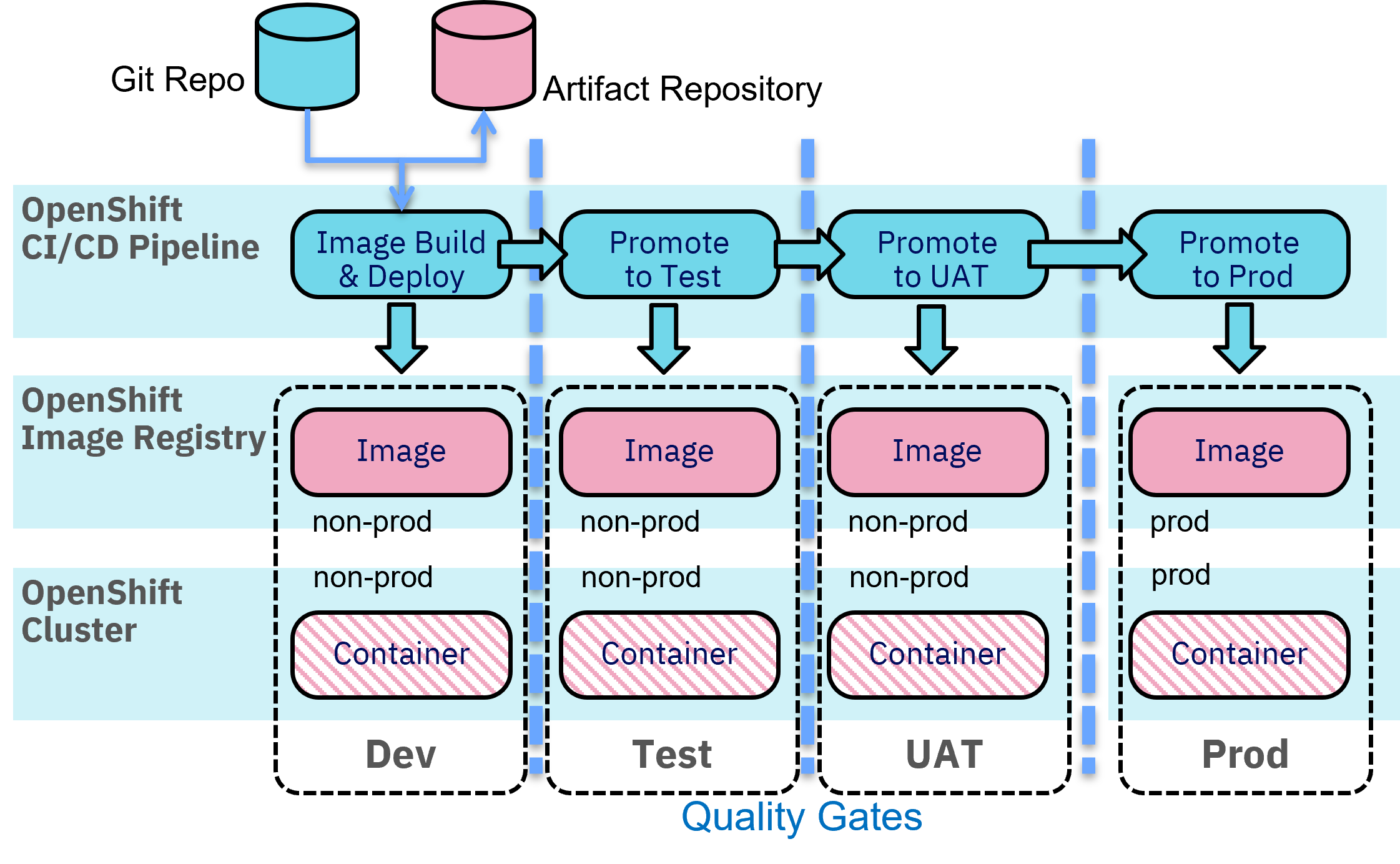
This implies that an automated and reproducible CI/CD pipeline is established. Such a pipeline is not only used to bring new code updates into a production environment, but also re-create a production environment as needed. For example, if there is a data center disaster.
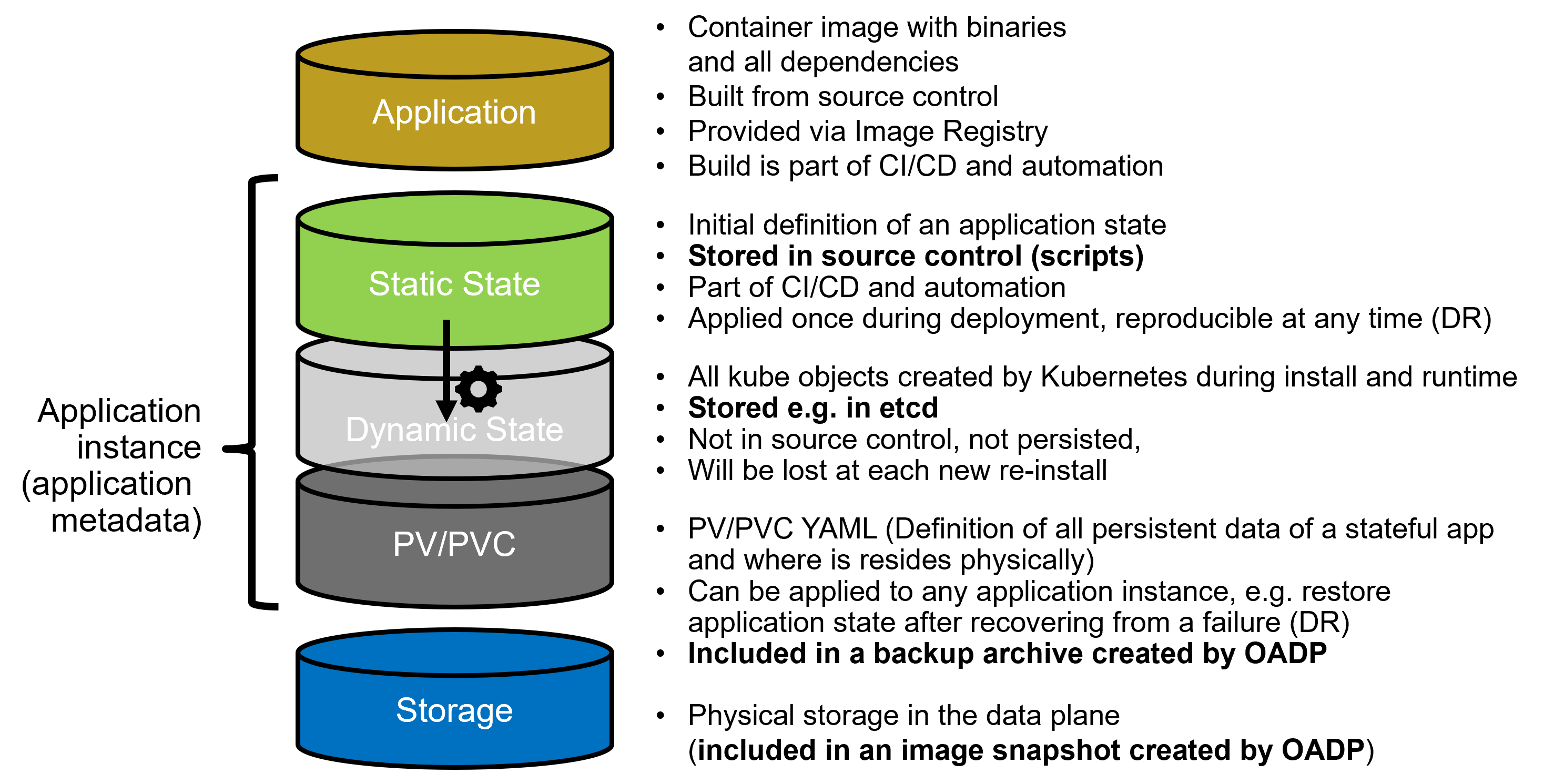
Required pieces of data for a Kubernetes application are:
- Application image with all its dependencies, which is built from a source control system via automated CI/CD and provided via the Image Registry.
- Static state of an application once deployed, which is stored in source control as scripts and part of the automated CI/CD. This initial state is applied once during deployment.
- PV / PVC metadata of persistent storage used by the application.
- Storage, the actual data of the persistent application storage.
- Dynamic state metadata created by Kubernetes during the lifetime of an application image. For example, stored in the cluster etcd database.
It is important to mention that the dynamic state is lost on each redeployment of an application image. Containerized workload will always start as a new image with its static state as defined in the CI/CD pipeline.
As a fundamental best practice in a Kubernetes world, there is no need to back up a cluster or application image, as it will always be possible to re-create that at any time using the CI/CD automation. This is why a solid CI/CD pipeline can also be considered as a key element of a disaster recovery approach for your workload.
Setting up an environment with infrastructure and application workload needs to be a fully automated and reproducible process allowing to restore an environment at any time in any place.
Nevertheless, the one essential thing to backup are the PVs and PVCs used by the application. Those include the precious stateful persistent data of the workload. The backup and restore of PVs (and its metadata) is covered by the Open API for Data Protection (OADP).