![[z/OS]](ngzos.gif)
![[MQ 9.2.0 Jul 2020]](ng920.gif)
Using MetroMirror with IBM MQ
IBM® Metro Mirror, previously known as Synchronous Peer to Peer Remote Copy (PPRC), is a synchronous replication solution between two storage subsystems, where write operations are completed on both the primary and secondary volumes before the write operation is considered to be complete. Metro Mirror can be used in environments that require no data loss in the event of a storage subsystem failure.
Supported data set types
- Active logs
- Archive logs
- Bootstrap data set (BSDS)
- Page sets
- Shared message data set (SMDS)
- Data sets used for configuration, for example, in the CSQINP* DD cards on the MSTR JCL
Using zHyperWrite with IBM MQ active logs
When a write is made to a data set that is replicated using Metro Mirror, the write is first made to the primary volume, and then replicated to the secondary volume. This replication is done by the storage subsystem and is transparent to the application that issued the write, for example IBM MQ.
This process is illustrated in the following diagram.
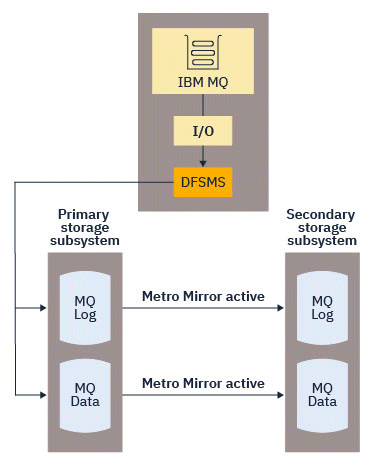
Because both writes to the primary and secondary storage subsystems need to complete before the write returns to IBM MQ, use of Metro Mirror can have a performance impact. You need to balance this performance impact against the availability benefits of using Metro Mirror.
The IBM MQ active logs are most sensitive to the performance impact of using Metro Mirror. IBM MQ allows use of zHyperWrite with the active logs to help reduce this performance impact.
zHyperWrite is a storage subsystem technology that works with z/OS® to reduce the performance impact of writes made to data sets that are replicated using Metro Mirror. When zHyperWrite is used, the write to the primary and secondary volumes are issued in parallel at the Data Facility Storage Management Subsystem (DFSMS) level, instead of sequentially at the storage subsystem level, thereby reducing the performance impact.
The following diagram illustrates zHyperWrite being used for the active logs, and Metro Mirror being used for the other IBM MQ data set types. Note that if a zHyperWrite write fails, DFSMS will transparently reissue the write using Metro Mirror.
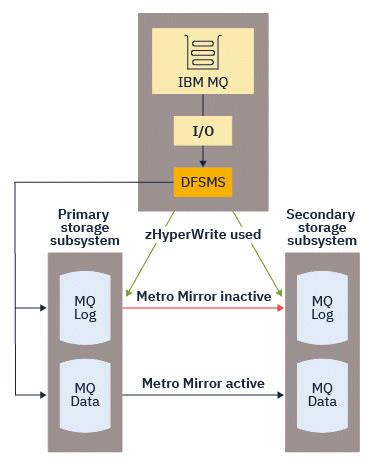
zHyperWrite on IBM MQ, is supported only on the active log data sets.
- Configure IBM MQ to use zHyperWrite, and
- The active logs need to be on zHyperWrite capable volumes
- Enable the volumes for Metro Mirror, and the volumes support zHyperWrite
- Ensure that the volumes are HyperSwap enabled
- Specify HYPERWRITE=YES in the IECIOSxx parameter
If all the preceding conditions are met, then writes to the active logs are enabled for zHyperWrite.
- IBM MQ does not require that all active log data
sets are on zHyperWrite capable volumes.
If IBM MQ detects that some active log data sets are on zHyperWrite capable volumes, and others are not, it issues message CSQJ166E and carries on processing.
- IBM MQ checks whether active log data sets are
zHyperWrite capable when the data sets are first opened.
Log data sets are opened either at queue manager start up, or when dynamically adding using the DEFINE LOG command. If the log data sets are made zHyperWrite capable while a queue manager has them open, the queue manager will not detect this until it has been restarted.
Copy %Full zHyperWrite DSName
1 4 CAPABLE MQTST.SUBSYS.MQDL.LOGCOPY1.DS001
2 4 CAPABLE MQTST.SUBSYS.MQDL.LOGCOPY2.DS001