Watson Knowledge Catalog overview
Watson Knowledge Catalog is an extension to Information Governance Catalog that provides self-service access to data assets for knowledge workers who need to use those data assets to gain insights.
After you create glossary assets and profile, classify, and curate information assets with Information Governance Catalog, you use Watson Knowledge Catalog to protect and display data assets in a self-service catalog where users can find and prepare data assets.
This diagram shows how Watson Knowledge Catalog and Information Governance Catalog work together to perform complimentary tasks.
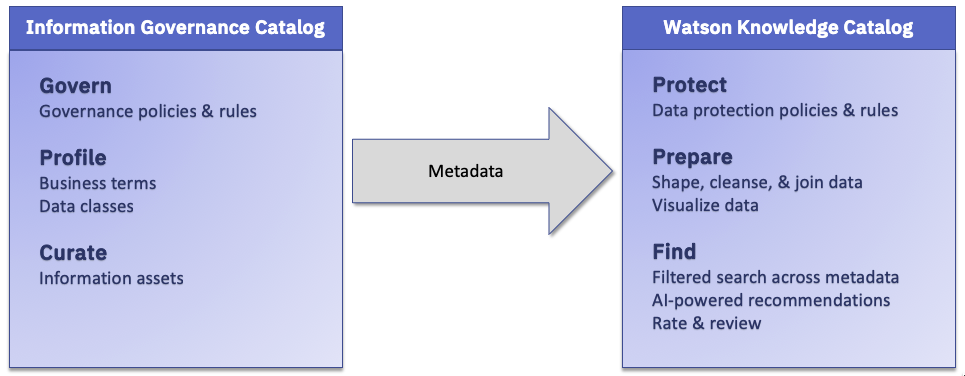
When you set up Watson Knowledge Catalog, the technical metadata from Information Governance Catalog for these types of information assets is shared with Watson Knowledge Catalog:
- Connections to relational databases
- Relational databases
- Schemas
- Tables and columns
The business metadata from Information Governance Catalog for these types of glossary assets is shared with Watson Knowledge Catalog:
- Terms
- Data classes
The actions and capabilities of Watson Knowledge Catalog vary depending on the offering plan. See Offering plans.
Protect data assets
Policy authors can create data protection policies that control access to data in Watson Knowledge Catalog by denying access to data assets or anonymizing data values in columns that contain sensitive data. The rules in data protection policies use Information Governance Catalog glossary terms and data classes. See Data governance.
Find data assets
Users can find and understand data assets in these ways:
- Search with keywords and filters that are based on subject tags and other asset properties.
- Choose from recommended assets that are automatically compiled and customized by machine learning.
- Choose from the most highly rated assets.
- View the previews of asset contents.
- Read reviews about data assets that are provided by other users.
- View the profiling, and lineage of data assets.
See Finding and viewing assets.
Work with data assets in the catalog
Depending on their roles within the catalog, users can work with data assets in the catalog in these ways:
- Rate and review data assets.
- Add data assets to projects to prepare the data.
- Add data assets.
- Edit data asset properties, such as the description.
- Associate business terms and tags to data assets.
See Catalog assets.
Prepare data assets in projects
Users can move data assets to workspaces called projects to acheive specific data preparation goals with a small group of collaborators. Projects provide the Data Refinery tool to manipulate data. Data Refinery is a self-service data preparation tool that you can use to quickly transform large amounts of raw data into consumable, quality information that’s ready for analysis. You can choose operations from menus or enter dplyr R library code in the command line text box.
These features of Data Refinery make it easy to explore, prepare, and deliver data that people across your organization can trust:
- Powerful operations to clean, organize, fix, and validate your data
- Scripting support for the efficient and flexible manipulation of data
- Scheduling and monitoring of data preparation flows
- Profiles for validating your data
- Visualizations for gaining insight into your data
- Data protection policies that anonymize data are enforced
- Support for unstructured data
See Refining data.
Learn more
- Offering plans
- Roles
- FAQs
- Getting started
- Read reviews of Watson Knowledge Catalog
- Write a review of Watson Knowledge Catalog