Architecture for IBM Cloud Pak for Data
IBM Cloud Pak® for Data is a modular platform for running integrated data and AI services. Cloud Pak for Data is composed of integrated microservices that run on a multi-node Red Hat® OpenShift® cluster, which manages resources elastically and runs with minimal downtime.
Cloud-native design
Many companies are embracing cloud concepts because they need reliable, scalable applications. Additionally, companies need to modernize their data workloads to use hardware effectively and efficiently.
By bringing together numerous data and AI services, Cloud Pak for Data enables you to reduce the cost and burden of maintaining multiple applications on disparate hardware. It also gives you the ability to assign resources to workloads as needed and reclaim those resources when not in use.
With a single, managed platform, Cloud Pak for Data makes it easier for your enterprise to adopt modern DevOps practices while simplifying your IT operations and reducing time to value.
Run on OpenShift
- An on-premises, private cloud cluster
- Any public cloud infrastructure that supports Red Hat OpenShift
For specific information about supported Red Hat OpenShift versions and installation types, see System requirements for Cloud Pak for Data.
Cloud Pak for Data leverages the Kubernetes cluster within Red Hat OpenShift for container management.
Cluster architecture
Cloud Pak for Data is deployed on a multi-node cluster. Although you can deploy Cloud Pak for Data on a 3-node cluster for development or proof of concept environments, it is strongly recommended that you deploy your production environment on a larger, highly available cluster with multiple dedicated control plane and worker nodes. This configuration provides better performance, better cluster stability, and increased ease of scaling the cluster to support workload growth. The specific requirements for a production-level cluster are identified in Hardware requirements.
In a typical production-level cluster, there are three control plane nodes and three or more worker nodes. Using dedicated worker nodes means that resources on those nodes are used only for application workloads, which improves the performance of the cluster.
It is also easier to expand a 6+ node cluster, because each node has a specific role in the cluster. If you expand a 3-node cluster, the cluster has a mix of dedicated nodes and mixed-use nodes, which can cause some of the same issues that occur in a 3-node cluster. If you expand a 6+ node cluster, each node has a dedicated purpose, which simplifies cluster management and workload management.

- Distributes requests between the master and proxy nodes
- Securely isolates the master and compute node IP addresses
- Facilitates external communication, including accessing the management console and API or making other requests to the master and proxy nodes
The control plane nodes schedule workloads on the worker nodes that are available in the cluster.
A production-level cluster must have at least 3 worker nodes, but you might need to deploy additional worker nodes to support your workload.
This topology is based on the minimum recommended requirements for a production-level cluster. However, you could implement a different topology. Refer to the Red Hat OpenShift Container Platform documentation for other supported cluster configurations.
Modular platform
The platform consists of a light-weight installation called the Cloud Pak for Data control plane. The control plane provides a command-line interface, an administration interface, a services catalog, and the central user experience.

If you plan to install multiple instances of Cloud Pak for Data, you must install the control plane in each project (namespace) where you want to install Cloud Pak for Data. The control plane enables you to coordinate and interact with the services that are deployed in the project.
Common core services
Several Cloud Pak for Data services require similar features and interfaces. To streamline the platform, these features are provided by the Cloud Pak for Data common core services. These services are installed once in a given project (namespace) and can be used by any service that requires one or more of the features.
The common core services provide data source connections, deployment management, job management, notifications, projects, and search.

The common core services are automatically installed when you install a service that relies on them. If the common core services are already installed in the project (namespace), the service will use the existing installation.
If a particular feature is provided by the common core services, it is indicated in the documentation by the following label:
Common core services
Integrated data and AI services
- AI
- Analytics
- Dashboards
- Data governance
- Data sources
- Developer tools
- Industry solutions
- Storage

You can select the services that you want to install on the control plane. For more information, see Services and integrations.
For example, if you are concerned with data governance and data science, you might install several AI services and analytics services, data governance services, and developer tools that support the developers and data scientists who are using Cloud Pak for Data. In addition, you might want to deploy an integrated database to store the data science assets that you generate using Cloud Pak for Data.
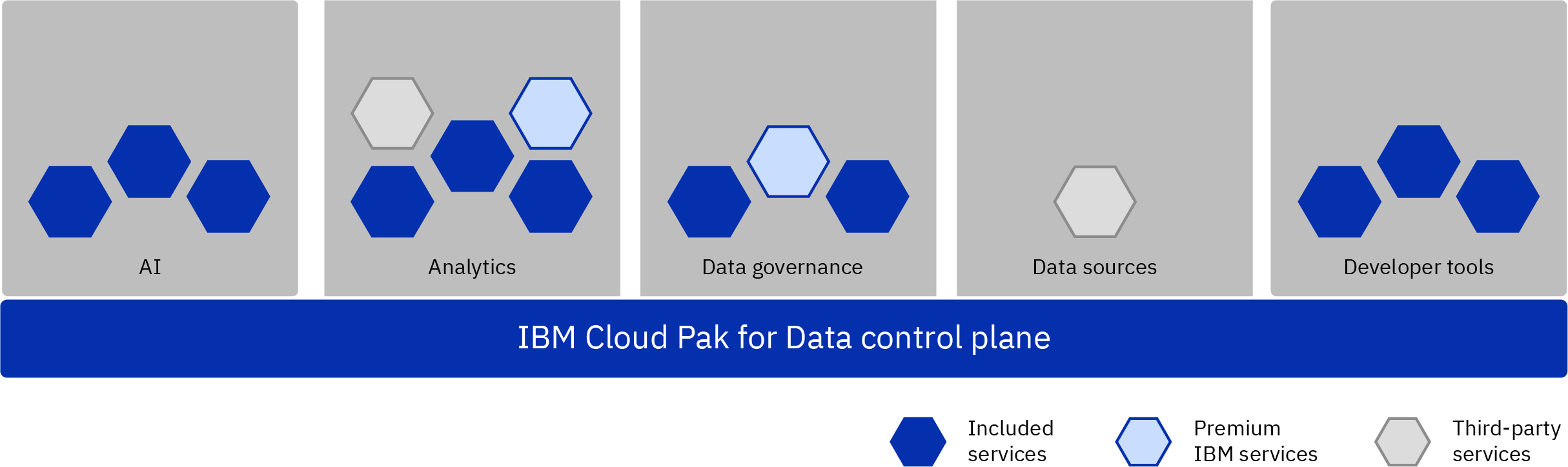
The number of services that you install and the workloads that you run for each service determine the resources that you need. You must ensure that you have the minimum resources required by each service. Work with your IBM Sales representative to ensure that you have sufficient resources for your expected workloads.