Preparing canned responses in CSV format
About this task
The CSV file should contain each canned response, and its associated category. For example, if you prepare the CSV using Microsoft Excel (and save the file in CSV format), the first column contains the category name, and the next column contains the canned response:
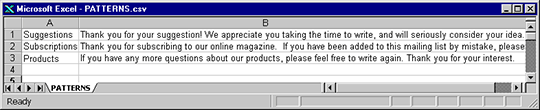
If you use the Find Patterns feature to identify canned responses embedded in content items, you can export the patterns in CSV format, remove any patterns that do not correspond to canned responses, and specify categories for each canned response. For more details, see Finding patterns.