This sample classification workflow illustrates how IBM® Content Classification automatically classifies documents into IBM FileNet® Content Manager.
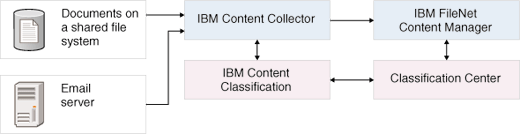
Through the Classification Center, IBM Content Classification combines statistical, text-based analysis methods (knowledge bases) with rule and keyword-based analysis methods (decision plans) to classify content in IBM FileNet Content Manager. You can set the destination folders, document classes, and document properties. Depending on rules in your decision plan, documents can be automatically declared as records when they are classified, which enables them to be managed by IBM Enterprise Records document retention and compliance policies.
In the Classification Center, you can review the classification decisions. If necessary, you can select different actions and reclassify the content. The system learns from your selections and improves future classification decisions.
If you use IBM Content Collector, content can be classified by IBM Content Classification when it is captured by IBM Content Collector. IBM Content Classification returns information that helps IBM Content Collector determine the appropriate action to take. For example, IBM Content Collector might archive a document or email into an IBM FileNet Content Manager folder or document class.