Technical Blog Post
Abstract
Identifying meaningful tokens with IBM Content Analytics Studio
Body

Jane Singer works in the IBM Content Classification development team in the Software Labs in Jerusalem Israel. Jane leads the L3 support team for Content Classification. She has also worked in the OmniFind Enterprise Search L2, QA for Case Manager and Content Navigator mobile teams. She has written multiple DeveloperWorks articles and is the author of IBM Classification Module: Make It Work for You.
Extracting meaningful bits of information from large bodies of unstructured text is sometimes referred to as “finding the needle in the haystack.” Often, finding these needles means that the context of the token needs to be analyzed. Implementing parsers that pick out these concepts can be quite complex.
However, some tokens are recognizable by their internal character makeup. Extracting them is therefore more straightforward, since there is no need to analyze the surrounding context. For instance phone numbers, social security numbers and product ID numbers are often distinctive to the eye and can be easily extracted.
In the upcoming IBM Redbooks publication, IBM Content Analytics with Enterprise Search: Discovering Actionable Insight from Your Content, this is just one of the techniques described for extracting new meaning from your free text documents. Have a look at Chapter 11 for more ideas on how to use IBM Content Analytics Studio (ICA Studio) to extract more information from your IBM Content Analytics and Enterprise Search collections.
In ICA Studio you can create a new annotation type based on character makeup, using the Character Rule resource. These rules can include both explicit and abstract descriptions of the characters. By exporting the annotator to IBM Content Analytics Miner or Enterprise Search, you can add these new facets to the index and recombine with other product features.
For example, a code may be made up of both letters and numbers such as ID003543.
Or in some cases, characters and punctuation marks need to be explicitly defined in the format.
For instance US phone numbers contain parentheses, hyphens and spaces as well as digits:
1-800-345-5436
1.866.222.1818
(201) 465-3543
The character rules are stored in rule databases. To create such a rule set in ICA Studio:
- Under you Resources folder, right-click on the Character Rules folder and choose New Character Rules database.
- Name and create the database.
- Double-clicking on the CharRules icon will open the database and the rule editor.
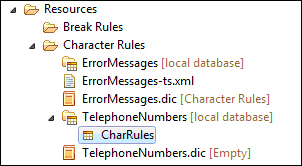
Let’s build an annotator to recognize the (201) 354-2343 format. In the rule editor add the character type Character Sequence and edit it:
- In the Selection tab, open the Type list and choose the Character Sequence type. Click Add.
- Expand the features and right-click on Covered Text. Choose Edit cover text.

- Enter the punctuation value and click OK.
| Note: You can insert multiple characters into the character sequence. For instance the closing parentheses followed by a space can be a single character token. |
- To enter the digits, from the Type list choose the Digit character type and click Add.
| Note: There is an extensive list of useful token types in the Type list: currency signs, decimal numbers, lower-case, etc. There are also a number of different punctuation types. |
- For each of the digit types you add, you can define how many times the digit type will repeat. This can be an exact number, or a range. Right-click on the digit icon and select Repeats -> Advanced. In this dialog you can control the number of times the character type can appear.
When you have entered all the characters (digits and punctuations) create the new annotation:
- In the Annotations tab select all the annotations by using ctrl-click.
- Right-click on any annotation and select Insert Annotation.
- Name the new annotation by appending the name to the class prefix:
com.mycompany.IT.USPhone
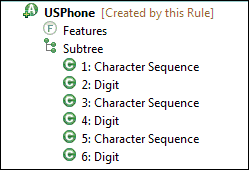
You can create multiple rules to recognize other valid telephone number formats (+1-201-454-5467, 212-456-4564, etc.) and assign them all to the USPhone type.
When you add this rule database to your annotator, all phone numbers recognized by your rules will be annotated by the same USPhone class.
The annotator can then be exported to the search/analytics server and be used as a field/facet in your IBM Content Analytics with Enterprise Search collection.
For more information download the upcoming IBM Redbooks publication and have a look at Chapter 11, IBM Content Analytics with Enterprise Search: Discovering Actionable Insight from Your Content.
Additional references
For IBM Content Analytics with Enterprise Search related BLOG posts, see:
- Unlock the hidden value of your unstructured content and gain new business insight: Really ? For us ?
- Identifying meaningful token with IBM Content Analytics Studio
- Add your insights to user queries - Query expansion and document ranking
- IBM Content Analytics - Import and Export OOTB (Out Of the Box)
For IBM Redbooks publication, see:
- IBM Content Analytics with Enterprise Search: Discovering Actionable Insight from Your Content (coming soon!)
UID
ibm11281094