By Neil Shah, Jordan Comstock, and Erin Farr
Introduction
This is part 2 of our Apache Spark on z/OS blogs. If you didn't have a chance, take a look at part 1.
The Problem
Wouldn't it be nice if we could have a list of all the error messages (messages that end with an "E" are classified as eventual action or what I call error messages, messages that end with an "A" are action messages etc...) that occurred in the z/OS SYSLOG? Yes, we have IBM zAware and IBM Tivoli System Automation for z/OS, so we are getting alerted when errors messages appear on the console. But, as a systems programmer, it would be really neat (or maybe it will give me more sleepless nights) to see all the error messages. I could write a REXX EXEC to find the error messages, but it would be cumbersome and probably slow. Why not use Apache Spark on z/OS? z/OS Spark has the ability to process large amounts of data in parallel and in memory. Java and scala allow for advanced expression matching, though perhaps you are not a java or scala programmer? Well then today is your lucky day... we did it for you.
The Solution
SYSLOG is a fixed-width format which includes fields such as record type, request type, route codes, system name, date and time, job ID, and MPF flags in addition to the message text. Within the text of each message is a message ID, which is a string of letters and numbers that identifies the meaning of the message. The last letter of the message ID is its type code, which classifies the messages into categories. Type codes which are of particular interest include “E” for messages where the operator must eventually perform an action, though are commonly referred to as "error messages", “A” for messages where the operator must perform an action, and “S” for severe errors.
In order to filter out only the messages with these type codes, the log data can be processed using Spark. To do this, a Spark application can be built and then submitted to Spark using the spark-submit command. I built the application using the Scala IDE for Eclipse on my local workstation, after which the jar file can be moved to the remote system using FTP. The application was built with Apache Maven, which builds a jar file that includes any dependencies that the project may have. For more details on setting up this build environment, see our previous blog here. This blog will focus on the code logic in case you want to update it to suit your needs.
The first step in the application is to create the Spark context and SQL context, which are the main entry points into Spark. The next step is to load the data into an RDD (Resilient Distributed Dataset), which is a partitioned collection of data that can be operated on in parallel. The SYSLOG data is received by the application through z/OS UNIX standard input (stdin), and parallelized to create an RDD. The first line of the data set, which holds no data (in our case we have a line header), can be discarded by filtering based on length. Additionally, each line was wrapped with the index of the line within the overall data set in order to preserve the order of the data.
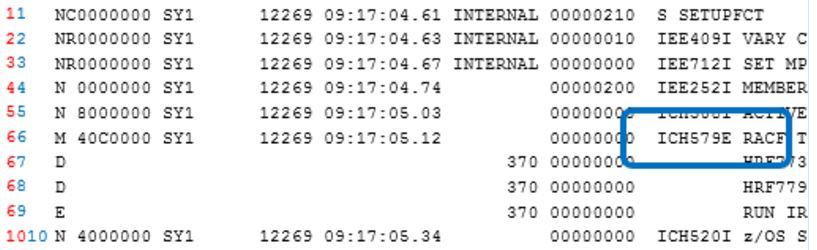
The trickiest part about analyzing SYSLOG data is that many of the messages span multiple lines. We want to share all lines of a message when filtering, even if only one line has the type code we want, so that we have the full context of the message. For example, Figure 1 has sample SYSLOG output showing a message ID "ICH579E". This is a multi-line message due to the "M" in the first column, and "D" and "E" in the subsequent rows. (Note that the message text is truncated on the right, for readability.) To retain each multi-line message, each line of the data was wrapped with the index of line number of the message, as annotated by the blue numbers in Figure 1. For multi-line messages, only the first line contains the date and time of the message, while all subsequent lines have that field empty. Therefore, each line with a date and time was wrapped (internally) with its index, while the lines with an empty field were wrapped with the index of the last line which did have the date and time, as indicated by the red numbered annotations in Figure 1. In this way, lines that are part of the same message are grouped together and identified with the same number.
Figure 1 – Sample SYSLOG data annotated with code logic and truncated for readability
Next, the lines of data are split based on the widths of the SYSLOG fields so that they can be separated into different columns. This data is converted into a Spark DataFrame, which is a table structure that allows data to be accessed using SQL queries. The DataFrame columns are named with the name of the fields to allow for easy access. All of the preceding steps can be seen in Figure 2.
Figure 2 – Parsing data and storing in a DataFrame

To determine whether the message ID of a message matches the type code(s) we used regular expressions. Some messages begin with a special character (“*” or '@'), and some messages also begin with a numeric ID. The regular expression was written to be able to match either the presence or absence of those characters before reaching the actual message ID. To match the message ID, a pattern was used which specifies between 3 and 5 letters, followed by between 3 and 5 numbers, and then followed by the type code letter. The type code can be passed as a command line argument as either a single letter, such as “A”, or multiple letters, such as “EAS”, so that the user can choose one or more types of messages to be displayed. A query was issued to the log data to match any entry whose message text matches the regular expression pattern, and the entries were stored in a new DataFrame. This process is shown in Figure 3.
Figure 3 – Matching messages with regular expression

Finally, the multi-line messages need to be reconstructed, so that the lines with matching type codes are not presented without their surrounding information. To do this, the column was extracted from the new DataFrame which held the indices of the starts of each message. Using these indices, the original DataFrame was queried to find any lines that were part of messages with matching message indices. The resulting lines produced a final DataFrame, which was then sorted by index and displayed. The result is a table of messages with type codes that match the user’s request, including multiple lines if the message has them. These final steps are shown in Figure 4.
Figure 4 – Reconstructing multi-line messages

I created the Spark application and ran it with a sample SYSLOG data set using the spark-submit command from z/OS UNIX below:
cat "//'LOGWTR.LOGTS.LOG16296.DATA'" | iconv -f IBM-1047 -t ISO8859-1 | spark-submit --class "com.ibm.log.LogFilteringTypeCode" --master local[4] /u/myuser/LogFiltering-0.0.1-SNAPSHOT-jar-with-dependencies.jar A
If you want to run this as a batch job, here is an example:
//STEP1 EXEC PGM=BPXBATCH,REGION=0M
//STDOUT DD SYSOUT=*
//STDERR DD SYSOUT=*
//STDPARM DD *
sh export JAVA_HOME=/usr/lpp/java/J8.0_64 &&
export SPARK_HOME=/usr/lpp/IBM/Spark &&
export SYSLOG=LOGWTR.LOGTS.LOG16296.DATA &&
PATH=$JAVA_HOME/bin:$PATH &&
export PATH=$PATH:$SPARK_HOME/bin &&
export IBM_JAVA_OPTIONS="-Xdump:none -Dfile.encoding=ISO8859-1" &&
cat "//'$SYSLOG'" |
iconv -f IBM-1047 -t ISO8859-1 |
spark-submit --class "com.ibm.log.LogFilteringTypeCode"
--master local[4]
/u/myuser/LogFiltering-0.0.1-SNAPSHOT-jar-with-dependencies.jar
A
//*
The "cat" command reads the data from the specified dataset LOGWTR.LOGTS.LOG16296.DATA and sends it to the iconv command through the shell pipe ( "|" ) so it can be converted from EBCDIC (IBM-1047) to ASCII (ISO8859-1) before sending to our Spark application, which is invoked with spark-submit. Spark expects the data in ASCII because it's compiled as ASCII. The application is run with the letter “A” as a parameter so that action messages will be displayed. Figure 5 shows several lines of output from our Spark application, where each message displayed is an action message. The output contains several multi-line messages, where the first lines contain the message ID ending in “A”, but the other lines are presented so that the full message can be read without being cut off.
Figure 5 – Sample output

Just in case you aren't up for writing a Spark scala application, we've provided the jar file (and the source) for you at SYSLOG Filtering with Apache Spark.
Finally, in case you have questions, there is a forum on Developerworks just for z/OS Spark!
Happy filtering!
About the authors
Neil Shah is a z/OS Systems Programmer for IBM Global Technology Services.
Jordan Comstock is a co-op on the development team for IBM z/OS Platform for Apache Spark.
Erin Farr is the development Team Lead for IBM z/OS Platform for Apache Spark.