Cache IBM Z data pattern
Improve application response time and scalability by storing optimized copies of IBM Z® data. Free compute resources and increase throughput by offloading application logic to the caching layer, especially for read-heavy applications.
Overview
← Back to Application modernization patterns
The surge of new digital applications is driving huge growth in data access. Those new applications typically run read-only queries of up-to-date data, but aren’t necessarily associated with generating revenue for the organization. Examples of such applications include mobile banking, retail online browsing, and insurance open enrollment. The characteristics of those applications can make them difficult to plan for and size:
- High, unpredictable volume
- Massive, sharp spikes in activity
- Updates are possible, but aren’t propagated back to the source (read-only)
- Expensive to maintain
- Complex to implement
- Often compromised data currency
- Prone to instability
Historically, to address those challenges, organizations used several methods to extract data for use on other platforms. It didn’t matter whether the applications were analytic or simple query-type access, the typical approach was to take the data off platform. Organizations used that approach because website developers who were accessing the data were sometimes unfamiliar with the mainframe and because of concerns that too much read-only activity might conflict with operational applications.
Traditional incremental copy and ETL approaches are unpredictable and can be associated with data latency. By using general-purpose incremental copy and ETL technologies, you can limit efficiency and performance improvement opportunities. Data extraction and incremental copy from IBM® Db2® for z/OS® can use considerable resources, increase software-related costs, and compete for the same resources that are used for operational processing.
As these applications are often customer facing, the data must be up to date—only moments behind a transactional system. This requirement drives the need for more complex application logic that ensures data currency. On top of the processes to refresh the read-only data store, some organizations use customized code to ensure this consistency. Doing so adds more complexity, instability, and cost to many environments. The following diagram shows the common approach to new, highly intensive read-only applications:

Many IT organizations consider these applications necessary to support customer service but want to minimize their associated cost. Yet, as these applications are often customer facing, the data must be up to date and data access must be resilient.
Solution and pattern for IBM Z®
Caching support on IBM Z improves application response time by storing copies of data that is on IBM Z. IBM Z offers several products that implement variations of this pattern. The IBM Db2 Analytics Accelerator, IBM Z Digital Integration Hub, IBM Db2 for z/OS Data Gate, IBM Z Table Accelerator, and IBM® Data Virtualization for z/OS with Cache Option include an implementation of the cache. Some of the products include a synchronization component to maintain the cache.
This table indicates the appropriate solution based on the application needs of data access type:
| Data access type | Db2 for z/OS | Db2 Analytics Accelerator | Db2 Data Gate | IBM Z Table Accelerator |
|---|---|---|---|---|
| Operational processing on rapidly changing data | Y | N | ||
| Ad-hoc analytic processing on data that is stored in the Accelerator via Db2 for z/OS | Y | N | ||
| Access to Db2 for z/OS (and other) data that is outside of IBM Z | Y | N | ||
| High speed access to relatively static data from within IBM Z infrastructure (CICS, Cobol, etc.) | Y | |||
| Offers general processor offload | (requires zIIP) | Y | Y | Y |
The two main differentiators of the cache are as follows:
- Pull versus push maintenance of the cache. In push maintenance, the cache is always kept in-sync with the source regardless of actual use. Pull maintenance involves a lazy update and invalidation of the cached values based on access.
- Cache data structure. The data structures of the cache are optimized for the consumption pattern, such as columnar or in memory. The cache itself might also contain derived or precomputed results.
This table summarizes the key differentiators among the available options:
| Description | Db2 Data Gate | Db2 Analytics Accelerator | Data Stage | Data Virtualization | Change Data Capture |
|---|---|---|---|---|---|
| Use case | Use IBM Z current and consistent IBM Z data on modern platform | Accelerate analytical queries on Db2 for z/OS | Automating ETL | Data integration, virtualization, make IBM Z data accessible and consumable for new users | Stream data from data sources into data lake and warehouses |
| Is data copied or kept in place? | Copy | Copy In place if Accelerator on IBM Z |
Copy | In place/in memory | Copy |
| If copy, what is the typical latency? | 1-10 seconds | 1-10 seconds | Hours/days | No copy | Depends (30 seconds for WH, 1-10 for OLTP) |
| Query performance expectation | Depends on target | Optimized for transactions and analytics (HTAP) | Depends on target data store | Data is moved/re-accessed on every query | Depends on target |
| Data ownership and access control | Target store | Db2 on z/OS | Target store | Source | Target store |
| zIIP eligibility | Integrated synchronization zIIP eligible | Integrated synchronization zIIP eligible | Depending on the workload | High percentage of workload is zIIP eligible | Lower zIIP eligibility rate (about 50%) |
| Addresses data transformation requirements? | N | In database transformation | Y | Y | Y |
| Data access type | Read | Read | Read | Read/Write | Read |
| Target | IBM Cloud Pak® for Data Db2 or Db2 Warehouse |
Db2 Analytics Accelerator | Data warehouse, data lake, flat files | In-memory virtual tables | Data warehouse, data lake, flat files |
| Continuous replication | Y | Y | N | N/A | Y |
This example shows how the previous approach can be improved:

This example shows an integrated approach to enterprise digital transformation:
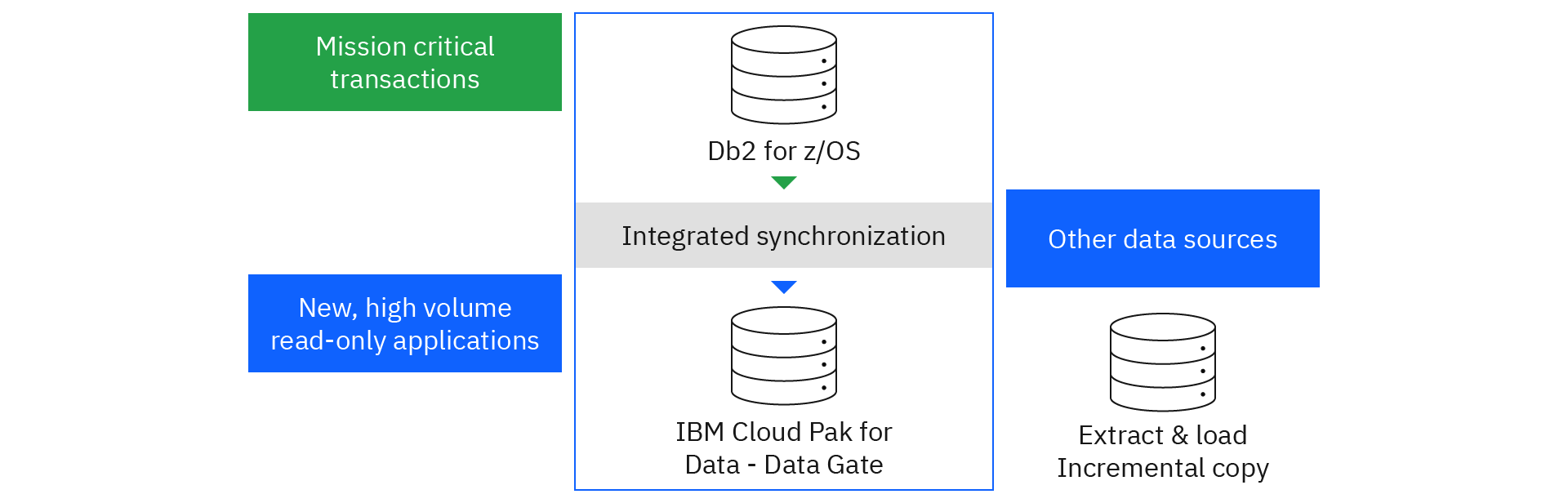
IBM Db2 for z/OS Data Gate can help you with this specific challenge regarding Db2 data on IBM Z. You can derive value faster from data that is generated through mission-critical applications that run on Db2 for z/OS. The solution uses technology to manage the replication and synchronization between the source and target. The source data always remains secure on IBM Z, and all insert, update, and delete actions are completed in Db2 for z/OS. You can define instances of Db2 Data Gate on IBM Cloud Pak for Data and use the IBM Cloud Pak for Data platform to build new applications and analytical models from Db2 for z/OS data without impacting the source system. In this sense, data needs from lines of businesses are fulfilled while transactional workloads on IBM Z remain secure and stable.
You can access Db2 for z/OS data in other ways, such as through z/OS Connect, REST API, and Java® Database Connectivity (JDBC) or Open Database Connectivity (ODBC). But nothing comes close to Db2 Data Gate in terms of performance, simplicity, and cost-effectiveness. Db2 Data Gate eliminates that complexity, providing timely, fast cloud access to your Db2 for z/OS data. Compared with traditional replication methods, Db2 Data Gate performs magnitudes better at a fraction of the CPU cost.
Advantages
Optimizing application performance by accessing cached IBM Z data can provide several critical business benefits:
- Achieves service level agreements (SLAs)
- Improves performance in scenarios where data is read repetitively and at high frequencies
- Provides a good compromise between cost and complexity
- Improves efficiency by avoiding hitting database or other data sources every time for the same request
- Integrated, lightweight data synchronization
- Excellent performance and resiliency
- Lower latency and better data currency
While caching is commonly used to improve application latency, a highly available and resilient cache can also help applications scale. By offloading responsibilities from the application’s main logic to the caching layer, you free up compute resources to process more incoming work. Read-intensive applications can greatly benefit from implementing a caching approach.
Considerations
Applications can tolerate various levels of latency depending upon the nature of the specific application. For example, a data warehouse reporting system that runs a balance sheet and income statement after a close doesn’t need up-to-the-second data. However, a trading application that depends on exact information has no tolerance for latency. In fact, even microseconds might mean a different decision. Algorithmic trading depends on a futures price and the price of a basket of stocks that the option represents. Any significant variation from those prices means that the trade might be unprofitable. The more latency in data, the greater the risk that your decision is wrong.
If you’re leaving the Db2 for z/OS environment, the only security that you can depend on is the security of the target system that the data is being moved to. You need to control database- and application-specific access for that database because none of the security attributes are passed on with the data.
What's next
- Review these related patterns:
- Explore the Application modernization for IBM Z architecture
Contributors
Director and CTO for IDAA, Db2 Data Gate, WMLz and OpenPages IBM
DB2 for z/OS Cloud Enablement IBM
Distinguished Engineer, WW Data and AI for IBM Z Technical Sales and Customer Success Leader IBM