Analytics
IBM SPSS Statistics Versie 27: Wat is er bijgekomen?
24/06/2020 | Written by: Robin van Tilburg
Categorized: Analytics
Share this post:
IBM SPSS Statistics, het bestaat al een tijdje, maar het is nog steeds going strong!
Op 16 juni is de nieuwe versie van IBM SPSS Statistics, V27, beschikbaar gekomen met weer nieuwe mogelijkheden, variërend van verbetering in de gebruiksvriendelijkheid tot extra functionaliteit, zoals Power Analysis.
Deze blog geeft een korte beschrijving van de vernieuwingen, meer uitgebreide informatie kan worden gevonden. Deze video geeft ook een goed overzicht.
Extra functionaliteit voor de basisversie
De ‘Statistics base’ versie is nu standaard uitgebreid met de modules ‘Data preparation’ en ‘Bootstrapping’.
‘Data preparation’ helpt de gebruiker met het automatisch detecteren en verhelpen van problemen in de datakwaliteit, het valideren van de data aan de hand van kwaliteitsregels, het vinden van een optimale ‘binning’ en anomaliedetectie. Hierdoor wordt de datapreparatiestap verkort, waardoor het daadwerkelijke onderzoek sneller uitgevoerd kan worden.
‘Bootstrapping’ is een techniek om de accuraatheid van statistische waarden te achterhalen. Dit wordt gedaan door middel van resampling en kan onder andere goed ingezet worden voor het omgaan met kleine steekproeven, om uitspraken te doen over de onbekende waarden in de populatie.
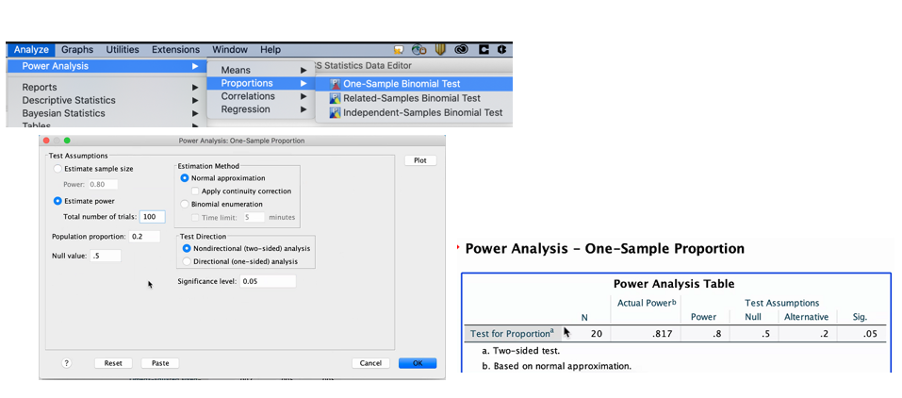
Nieuwe functionaliteit: Power Analysis en Weighted Kappa
‘Power Analysis’ is een techniek die zeer bruikbaar is in de voorbereiding van een onderzoek. De analist kan hiermee berekenen hoe groot een steekproef moet zijn om een bepaalde significantie te bereiken. Dit kan uitgevoerd worden vóórdat de data verzameld gaat worden en is daarmee een enorme hulp in het (kosten)efficiënt plannen en uitvoeren van onderzoeken. Binnen de SPSS Statistics V27 ‘base-edition’, zijn er 11 methoden beschikbaar.
De Weighted Kappa is een uitbreiding op Cohen’s Kappa, die gebruikt wordt om de consensus tussen beoordelaars te bepalen. Waar Cohen’s Kappa kan vooral goed gebruikt kan worden bij nominale variabelen, daar kan de Weighted Kappa ook goed op ordinale variabelen worden toegepast.
Procedureverbeteringen
Bij de (in de ‘Base-versie’ beschikbare) procedures One-sample t-test, Independent-samples t-test, Paired samples t-test, One-way analysis of variance (ANOVA), custom contrasts in one-way (ANOVA) is nu de mogelijkheid toegevoegd om de ‘Effect Size’ weer te geven.
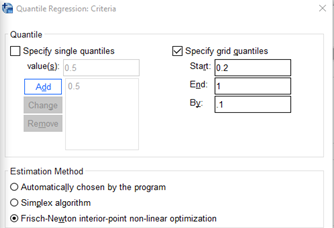
De Quantile regression-fuctionaliteit (beschikbaar sinds versie 26) is verder uitgebreid, waaronder verbetering van de dialoogbox.
Aan de ‘MATRIX’-omgeving zijn de volgende mogelijkheden toegevoegd: Random variable generation functions, Probability distribution functions (PDFs), Noncentral probability distribution functions (NPDFs), Significance functions for chi-square and F distributions en Noncentral cumulative distribution function (NCDF) for Beta distributions.
Gebruiksvriendelijkheid
Ook het werken met IBM SPSS Statistics is met V27 nog gebruiksvriendelijker gemaakt. De interface is uitgebreid met een zoekfunctie die het zoeken binnen de procedures, help topics en syntax commando’s vereenvoudigt. Daarnaast is er autorecovery toegevoegd, om het verlies van resultaten tijdens afgebroken sessies te verminderen en er zijn verbeteringen aangebracht in de output-mogelijkheden, zoals een nieuwe bubble-chart, en verbeteringen in de chart templates.
Tot zover het overzicht van de laatste verbeteringen met versie 27…
Al met al valt er dus weer wat nieuws te beleven in de wereld van IBM SPSS Statistics…
Wil je IBM SPSS Statistics versie 27 uitproberen? Dat kan! Download de trial hier >
Als je je kennis wil opfrissen of kennismaken met technieken binnen SPSS Statistics, dan raad ik ook de webinars van DASC aan, waarbij er steeds weer een aspect van SPSS wordt behandeld.
Donderdagmiddag 2 juli wordt daar zelfs een online launchparty gehouden (vrij toegankelijk), om de release te vieren en je direct van informatie te voorzien over deze nieuwe versie.

Analytics Client Architect

Datagedreven asset management met IBM Maximo Application Suite en Cloud Pak for Data
IBM heeft zijn Enterprise Asset Management-platform IBM Maximo Application Suite (MAS) voorzien van IBM Cloud Pak for Data: een ondersteunend platform met een raamwerk om allerlei data uit verschillende organisatieonderdelen te combineren. Hoe helpt IBM Cloud Pak for Data organisaties om aanvullende asset management-inzichten uit beschikbare data te verkrijgen? Het aantal intelligente stand-alone en edge […]

IBM SPSS Statistics Versie 27: Wat is er bijgekomen?
IBM SPSS Statistics, het bestaat al een tijdje, maar het is nog steeds going strong! Op 16 juni is de nieuwe versie van IBM SPSS Statistics, V27, beschikbaar gekomen met weer nieuwe mogelijkheden, variërend van verbetering in de gebruiksvriendelijkheid tot extra functionaliteit, zoals Power Analysis. Deze blog geeft een korte beschrijving van de vernieuwingen, […]

Naar intelligente bedrijfsautomatisering met Business Rules en Machine Learning
Veel bedrijven denken dat ze al lang geleden de grote stap hebben gezet in de richting van bedrijfsautomatisering. Technisch gezien klopt dat, lang geleden. De volgende stap in de bedrijfsautomatisering is de daadwerkelijke automatisering van het bedrijf en dat is waar IBM Digital Business Automation voor zorgt door gebruik te maken van technieken als […]