Design Thinking
The Science Behind IBM’s Data Science Design
February 20, 2018 | Written by: Arin Bhowmick
Categorized: Analytics | Data Science | Design Thinking
Share this post:
Data science is a rapidly evolving discipline that leverages an ever-widening array of tools and capabilities to learn and exploit. Because of such inherent complexities surrounding adoption, integration and support, the work of the data scientist can be daunting.
That complexity is one of the reasons IBM several years ago set out to bring clarity and uniformity to the otherwise disparate data discovery and analytics process. The goal: create a solution that leveraged the best capabilities available, in an integrated, collaborative platform that was easy to access and use. With it, everyone from data scientists to business analysts would be able to not only tackle the discipline, but conquer it.
Along the way, we learned a lot about the role of data scientists; their challenges, their tools of choice, and how they valued certain processes and functionalities over others.
But, first a little background. Up until the time IBM rolled out the popular Data Science Experience, if someone wanted to engage in data science, he/she would have to search the web, review components like Jupyter notebooks, or development platforms like Scala and r, big data tools like Hadoop, and much more – and then learn how to use them.
Not unexpectedly, the wide variety of tools and programs led to relatively slow adoption, challenging integration, and cumbersome support.
In addition, our research showed that once up and running, most data scientists’ workflows were often fragmented, requiring them to toggle between a variety of workspaces and tools to complete a job. For example, they might use Data Shaper to clean data, Jupyter for modeling and MatPlotLib for visualization. These tools support a linear process, but data scientists’ workflows are more cyclical — like this:
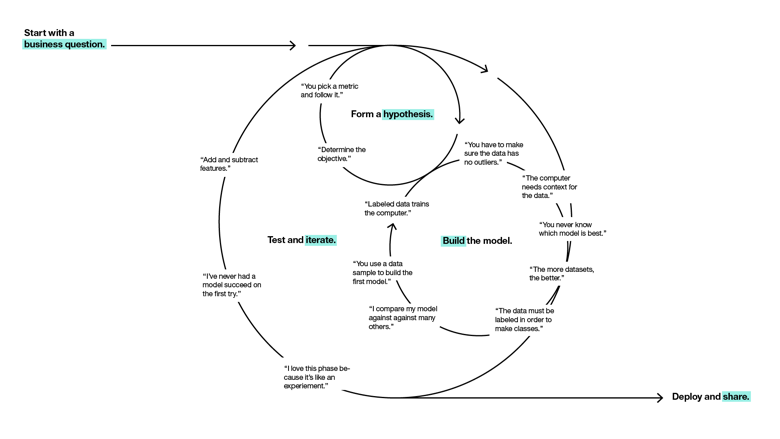
When we launched the Data Science Experience in 2016, users for the first time had a solution that integrated the most sought-after development, notebook and analytics tools, in a simple-yet-scalable web-based platform. It also enabled users to connect live with IBM for any and all support. It was a breakthrough in this fast-evolving corner of the tech industry. In 2017 we rolled out a “Local” version for organizations to install behind their firewalls in their own data centers.
In addition to the aforementioned goals, the vision for Data Science Experience was that it would accommodate the agile workflow, simplify the experience of working with data, and bring all the tools into a unified data ecosystem.
As Caroline Law, Design Lead at IBM, said, “The Data Science Experience is a beautiful manifestation of the power of user research to understand our users’ needs, challenges and motivations.”
In particular, the design team in charge of the ideation of the solution identified some of data scientists’ biggest needs, including the ability to collaborate with fellow data scientists and learn from each other; the ability to share algorithms and exchange data analysis techniques; and the ability to publish the results of their work and collaborate with peers across neighboring disciplines – people like data engineers who can help them prepare data and business analysts who can translate their insights into data-informed decisions.
The design team also wanted the experience to be easy to use and accessible for companion sites built for data engineers, system administrators and other user personas. They started work on building the ultimate data ecosystem, an environment that would intuitively connect related data functions and allow easy collaboration.
In the process of designing Data Science Experience, IBM’s San Francisco design team also developed interface frameworks that are now used and applied across IBM.
One example: Cognitive Assistance for Data Scientists (CADS) suggests, tests, and deploys machine learning models for you, so you don’t have to be an expert data scientist to build cognitive applications.
IBM Data Science Experience, in function and form, helps simplify the data science universe. Today, Data Science Experience is one of the premier data science systems available on the market, with thousands of users worldwide.
The diligence and restless pursuit for innovation of the IBM Cloud design team is paying off and its work recognized. Last fall, the Data Science Experience won the prestigious 2017 Red Dot design award. And this week it was announced that the iF International Forum Design, GmbH, has given the IBM Data Science Experience its iF Design Award 2018 in the Communications — Software Application category.
And though such recognitions are well received, it’s what the designs enable people to do that keeps us driving into the future.

Vice President, Design, IBM Hybrid Cloud

AI in 2020: From Experimentation to Adoption
AI has captured the imagination and attention of people globally. But in the business world, the rate of adoption of artificial intelligence has lagged behind the level of interest through 2019. Even though we hear that most business leaders believe AI provides a competitive advantage, up until recently, some industry watchers have pegged enterprise adoption […]

Putting Diversity to Work in Data Science
Gender diversity of data scientists has been cited as an issue by many sources. According to The Burch Works Study of Data Scientists, only 15% of data scientists are female and the percentage of females in data scientist manager roles (<10%) is much less than that of early professionals (> 20%). This data is consistent […]

Watson Anywhere: The Future
(Part 3 in a Series) There’s a paradox in the world of AI: While it’s the largest economic opportunity of our lifetime (estimated to contribute $16 trillion to GDP by 2030), enterprise adoption of AI was less than 4% in 2018. A recent Gartner survey said that the 4% in 2018 has now grown to […]