SPSS Modeler ヒモトク
第5回 多品目の時系列予測結果の加工 – IBM SPSS Modelerスクリプトによる分析作業の効率化
2016年03月07日
カテゴリー SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
多品目の時系列予測結果の加工(ループ処理+リストのパラメータ展開+横持ちから縦持ちへの変換)
先ほどは入力データがあらかじめ集約されたレポートでしたが、レポートでなくても縦持ちに変更したい場合があります。例えば、対象品目の多い時系列 モデルの出力をグループ化する(横持ちで出力される予測値を縦持ちにして、予測値とそのアイテム名をリスト化する)というような場合です。
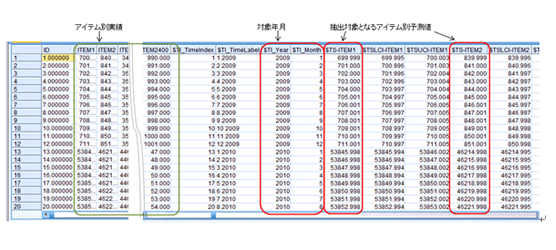
製品の需要予測で同時に複数のアイテムを予測すると、下図のようにアイテム別に予測結果が出力されます。ところが、後続処理で予測結果をDBに保存 したい場合、DBではテーブル内の特定のフィールドにアイテム名と予測値を挿入する設計になっているため、予測値一つ一つにアイテム名を付けるようにデー タを並び替える必要が出てきます。
そこで、この並び替えにスクリプトを利用します。各対象品目の値とアイテム名をエクスポートする処理を繰り返す、つまり、対象品目をリストから読み込んでループ処理を行うことで対応できるのです。
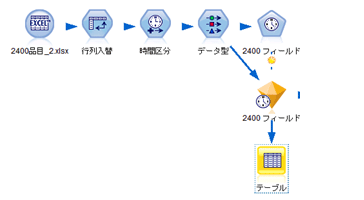
処理概要
今回のケースでは、2400アイテムの需要予測を行います。時系列モデルノードを使用して、2400アイテムの需要を一度に予測します。すると、下 図のようにアイテム別実績と予測値「$TS-」、確信度の上限・下限で計算された予測値「$TSU-」・「$TSL-」が出ます。
ここで出力された予測値を年月別アイテム別に縦持ちにしてDBへ保存します(実績値は対象外)。そこで、先ほどの「横持ちデータから縦持ちに加工」 の処理が利用できますが、厄介な点が2つあります。1.アイテムリスト作成において、ストリームの途中であるためフィールド名がそのままアイテム名に使用 できない点と、2.抽出対象フィールドが連続していない点です。今回は、この2点への対処方法に焦点を当てます。

1. ストリーム&スクリプト:アイテムリスト作成
予測値のフィールド「$TS-ITEM1」から「$TS-ITEM2400」まではスクリプトでパラメータ設定をしてループ処理させたほうが効率的 です。これらのフィールドはいずれも先頭に「$TS-」がついていますので、アイテム名を取得するには、これを除外したものを利用できそうです。(実績値 のフィールド名をそのまま使っても良いですが、事前の加工段階で除外されるケースもありますので、ここでは予測値のフィールド名を利用します。)
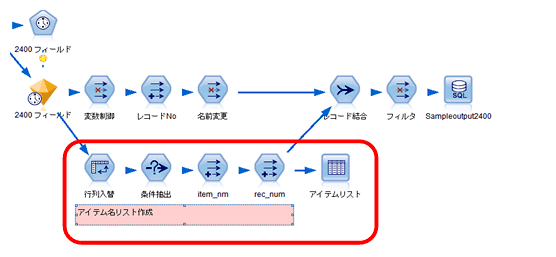
まずは、行列入れ替えをしてフィールド名リストを作成します。

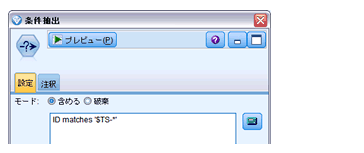
ここから、対象となるフィールドのみ抽出します。関数「matches」を使います。
フィールド「item_nm」を追加し、値に「ID」フィールドから「$TS-」を除外したものを入力します。
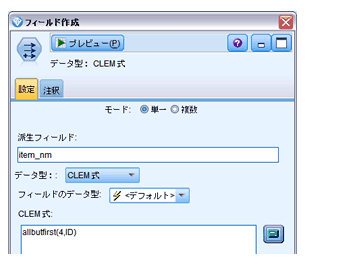
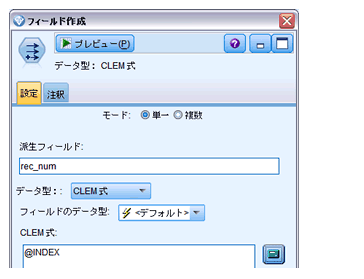
さらに、元データと結合させるために「rec_num」フィールドを追加し「@INDEX」でレコード件数を追加します。後で結合キーとして使います。
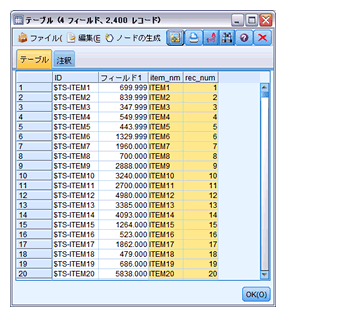
下記の通りアイテム名リストが出来ました。
2. ストリーム&スクリプト:抽出対象フィールドの設定
対象年月の「$TI_Year」と「$TI_Month」は直接指定します。
予測値「$TS-」は選択、確信度の上限・下限で計算された予測値「$TSU-」・「$TSL-」は対象外とします。(手動で、モデルナゲットを設 定すればあらかじめ「$TSU-」・「$TSL-」フィールドは除外できますが、モデル構築時・再構築時には必要な情報かもしれませんし、自動化設定の度 にわざわざ修正するのも面倒です。)そこで、スクリプトを使用してフィルタノードの設定を行います。
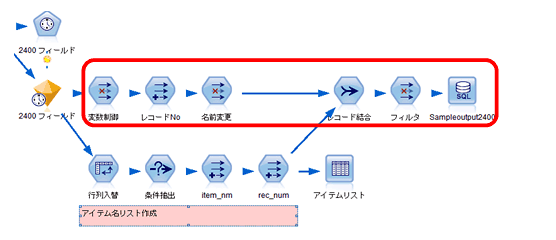
アイテムリストにある「ID」が抽出対象フィールド名と一致しますので、その値を1つずつ読込み、値が一致するフィールド名をフィルタノードで「選択」します。ここでのポイントは、tablenodeオブジェクトのパラメータ「output」です(設定方法は3章参照)。また、あらかじめフィールドノードで「すべてのフィールドを削除」に手動で設定しておきます。下記にループ処理のスクリプトを挙げます。
/* 「変数制御」フィールド選択ループ処理 */
var p
set p=1
var last_row
set last_row=アイテムリスト:tablenode.output.row_count – 1 /* フィールド選択ループ処理を最後の行まで実行する*/
execute ‘アイテムリスト’ /*後続の「アイテムリスト:tablenode.output」処理が有効になる*/
for p from 0 to ^last_row
set p=^p+1
var Cnm
set Cnm = value アイテムリスト:tablenode.output at ^p 1 /* アイテムリストの最初のフィールド「ID」を1行ずつ参照 */
set 変数制御:filternode{
include.’$TI_Year’ = true /*対象列を選択*/
include.’$TI_Month’ = true
include.^Cnm = true
}
endfor
3. ストリーム&スクリプト:結果のエクスポート
最後に1.と2.をレコード結合し、フィルタノードでDBのテーブルに合わせたレイアウトに加工後、DBへエクスポートします(設定方法は4章参 照)。これで、今回必要なループ処理ができます。(DBへの負荷が気になる場合は、一旦CSVファイルにエクスポートしてからDBへ投入しても良いでしょ う。)
スクリプト全体は下記の通りです。
/* 「変数制御」フィールド選択ループ処理 */
/* 変数宣言 */
var p
var last_row
var Cnm
/* パラメータ設定*/
set 変数制御:filternode.default_include = false
execute ‘アイテムリスト’ /*後続の「アイテムリスト:tablenode.output」処理が有効になる*/
/*エクスポート用テーブル作成&対象1列目のデータエクスポート*/
set Cnm = value アイテムリスト:tablenode.output at 1 1 /* アイテムリストの最初のフィールド「ID」を1行目のみ参照 */
set 変数制御:filternode{
include.’$TI_Year’ = true /*対象列を選択*/
include.’$TI_Month’ = true
include.^Cnm = true
}
set p=1
set レコードNo:derivenode.formula_expr= ^p /*アイテムリストとレコード結合するため*/
set 名前変更:filternode{
include.’$TI_Year’ = true /*対象列を選択*/
include.’$TI_Month’ = true
include.^Cnm = true
include.’レコードNo’ = true
new_name.’レコードNo’= ‘rec_num’ /*結合キー名に変更(スクリプトでは同じノード名が使えないためここで合わせる)*/
}
set フィルタ:filternode{
new_name.’$TI_Year’ = ‘Year’ /*エクスポート先と同じ列名に変更*/
new_name.’$TI_Month’ = ‘Month’
new_name.^Cnm=’item_num’
include.rec_num = false /*不要な列を除外*/
include.’フィールド1′ = false
}
set Sampleoutput2400:databaseexportnode.write_mode = Create
/*エクスポートの保存モードを「上書き」に設定(必要に応じて既存のテーブル削除を設定)*/
execute ‘Sampleoutput2400′
set 変数制御:filternode{
new_name.^Cnm= ^Cnm /*次の処理のためにフィールド名を元に戻す*/
include.^Cnm= false /*次の処理のために選択解除*/
}
set Sampleoutput2400:databaseexportnode.write_mode = Append /*次の処理のためにエクスポートの保存モードを「追記」に設定*/
/*対象2列目以降のデータエクスポート(ループ処理)*/
set last_row= アイテムリスト:tablenode.output.row_count
set p=1
for p from 1 to ^last_row
set p=^p+1 /* 2行目以降のため、p=2から */
set Cnm = value アイテムリスト:tablenode.output at ^p 1 /* アイテムリストの最初のフィールド「ID」の2行目以降を参照 */
set 変数制御:filternode{
include.’$TI_Year’ = true /*対象列を選択*/
include.’$TI_Month’ = true
include.^Cnm = true
}
set レコードNo:derivenode.formula_expr= ^p /*アイテムリストとレコード結合するため*/
set 名前変更:filternode{
include.’$TI_Year’ = true /*対象列を選択*/
include.’$TI_Month’ = true
include.^Cnm = true
include.’レコードNo’ = true
new_name.’レコードNo’= ‘rec_num’ /*結合キー名に変更(スクリプトでは同じノード名が使えないためここで合わせる)*/
}
set フィルタ:filternode{
new_name.’$TI_Year’ = ‘Year’ /*エクスポート先と同じ列名に変更*/
new_name.’$TI_Month’ = ‘Month’
new_name.^Cnm=’item_num’
include.rec_num = false /*不要な列を除外*/
include.’フィールド1′ = false
}
execute ‘Sampleoutput2400’
set 変数制御:filternode{
new_name.^Cnm= ^Cnm /*次の処理のためにフィールド名を元に戻す*/
include.^Cnm= false /*次の処理のために選択解除*/
}
endfor
delete output :tableoutput /* アイテムリストのアウトプットを削除 */
出力結果は下記のようになります。
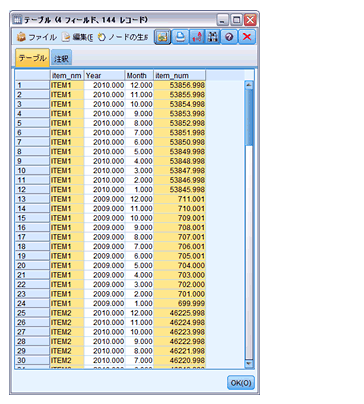
今回使用したtablenode.outputによるリストの読み込みは、複雑で手間のかかるフィルタ設定でも、スクリプトを使うと簡単ですし、自動化処理の幅も広がります。

データ分析者達の教訓 #16- ステークホルダーの高い期待を使命感と創意工夫で乗り越えろ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #15- データ分析は手段と割り切り情熱をもって目標に進め
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちはIBMの河田です。SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を進め ...続きを読む
データ分析者達の教訓 #14- データから導かれる「あたりまえ」を丁寧に見つめ直す
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さん、はじめまして。 昨年末にIBM にJoinし、Data&AIでデータサイエンスTech Salesをしている宮園と申します。 このリレー連載ブログはSPSS Modelerの実 ...続きを読む