ストーリーを読み解くのにかかったのはたった1週間
前回の「ストーリーを科学的に読み解く」では論文で使われる積分の演算部分をWatson APIに置き換えShape(グラフの曲線のこと)を検出するところに力点を置いたことで、ストーリーの解析が容易になったことを説明した。今回はその仕組みやシステム構成について簡単に説明して行きたいと思う。
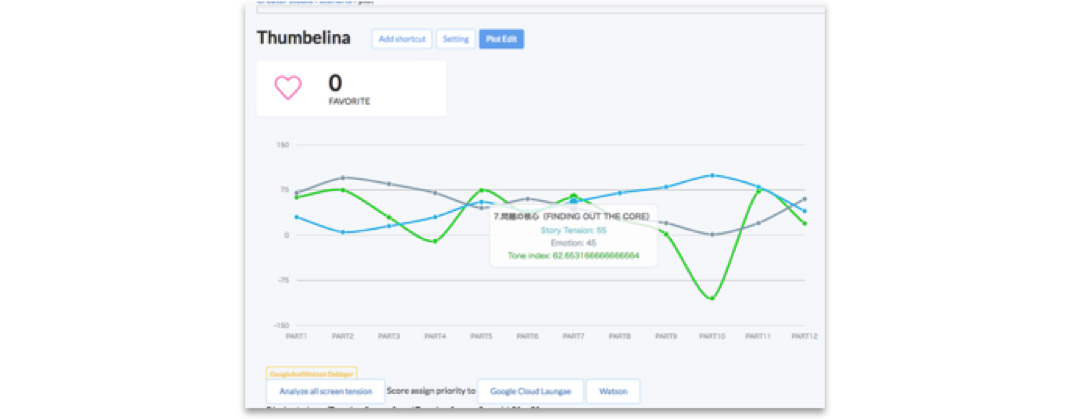
まず、本題に入る前に結果を先に予めお見せしたい。アンデルセンの名作「おやゆび姫(英題:Thumbelina)」を解析した結果がいかのようになる。
本システムでは、単純に文章をコンピュータに入力すれば出るわけではなく、一手間加えたことによって誰でも簡単にグラフを出力することが出来るような仕組みづくりをおこなった。
一手間とは、まずは時系列毎にシーンをある程度分解して横に並べるという処理をする。段落で区切っても問題ない。次にキャラクターを設定する。AIのシステム都合上「代名詞」は取得できないため、一度名詞に置き換える。そうすることでStoryのメタ的な判定をすることが可能となった。
重要なのは、データの抽象化を先に行うことで、人間のメタ認識に対応しているという点にある。また、キャラクターというものは登場シーンで異なる属性を持つという点に気をつけなければ正確な判定はできなかった。例えば、おやゆび姫で言えば、上記のグラフの緑の線のShapeがPart10で大きく下がっているが、このシーンはモグラと結婚させられるところだ。
当初、思ったようなパラメータの検出をしてくれなかったが、同シーンに登場している野ネズミのおばあさんに着目した。野ネズミのおばあさんはこの一つ前のシーンまではおやゆび姫にとって、まさに親のような存在だった。
ところがモグラと結婚させられる瞬間、おやゆび姫は彼女のことを面倒な存在=敵として認識したと考え、野ネズミ2という新キャラクターが登場したと仮定した。これにより人間が受け取った印象とグラフがほとんど一致し、いかにキャラクターを理解すことが解析にとって重要であることを私たちは理解した。
さて、本システムはマルチクラウドで実装されている。IBM Watsonだけではなし得ず、必要な機能を必要な分だけ他社のサービスや機能を利用するシステムを採用した。
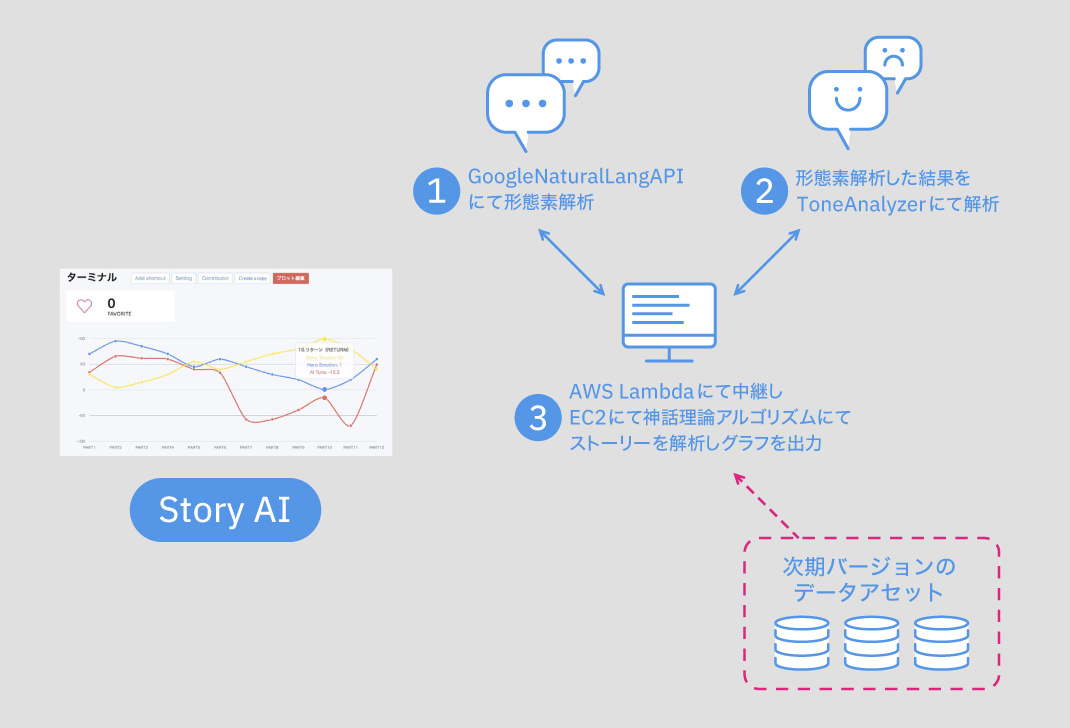
構図としては以下のとおりだ。

システムのシーケンスとしてはこのようになる。EC2のRuby on Railsサーバーからユーザーが投稿した文章とキャラクターのデータを元に、一度GoogleのAPIで形態素解析したあと、IBM Watsonにデータを渡し感情値を返す。その後Railsが稼働するサーバー上で戻り値を使いシーン毎に判定しグラフにマッピングする。
分析サーバーは常時使われるわけではないため、サーバーレス型を採用し時間単位で利用することでコストを抑えている。Story AIのEC2インスタンスからAWS Lambdaに仕込んだIBM WatsonとGoogleのNode.jsライブラリを呼び出す仕組みだ。
ここで、なぜWatsonとGoogleをそれぞれ使っているのかというと、それは形態素解析の精度の問題にある。初期の実装では当時IBM WatsonにあったAlchemyという形態素解析APIを利用していたが、これがGoogle Natural Lang (GNL)APIと比較して私が分析しようとしていた分野の言葉では精度が悪かった。例えば、窓という単語があったとするとAlchemyでは「OS」、GNLでは「Thing」として返ってきた。これは、Watsonに覚えさせた基礎データがニュースで、Googleが自然言語検索結果だった可能性が高い。このように会社ごとに方式が異なるので返り値も異なってくる。
同様に、Tone AnalyzerのようにGNLでも感情値を返すことは可能だ。しかし、GNLでは幸福値的な扱いなので、アップサイドとダウンサイドしか存在しない。ところが、Tone AnalyzerはJoy(楽しい)、Anger(怒り)、Fear(恐怖)、Sadness(悲しい)、Disgust(嫌悪)と5つの感情が返ってくる。より細かい感情が返ってくるほうが精度の高い判定ができると考え、IBM Watsonを選択することにした。
また、Tone Analyzerにも問題があった。英語しか解析できないのである。そこで、一度、Google翻訳と人間の翻訳でどのぐらいパラメーターに差があるのかを検出してみた。その結果はQiitaにてまとめているが、明らかにシンメトリー的な構造を取っているようにみえる。
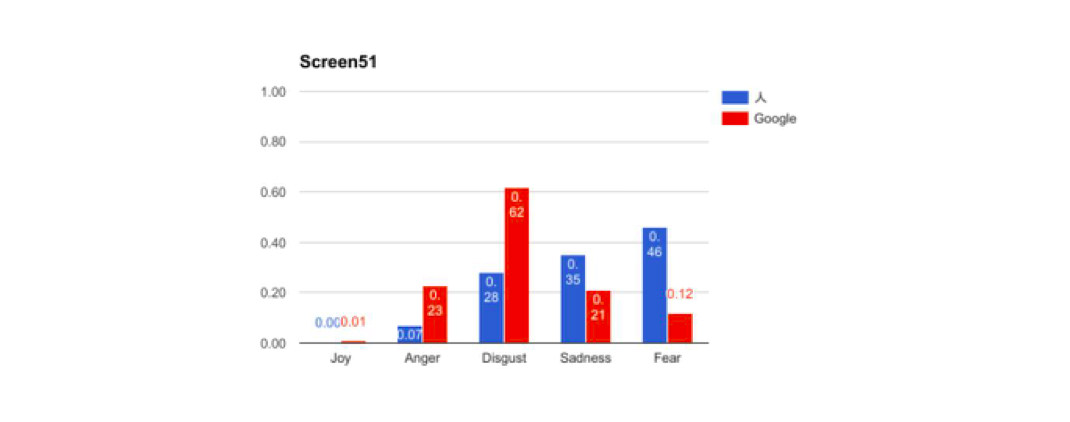
つまり、これは書いた人間の属性によって選択する単語が異なるため起きていることではないかと仮説を立てた。同様にGoogle翻訳もプログラマが組んでいるため、当然のごとく人間の恣意的な部分が影響してくると思われる。
私達のテストで使った英文はネイティブに近い思考を持っている高学歴の20歳前半の女性が翻訳したものだ。Google翻訳は想像だが、エンジニアの男性が組んだものではないかと考えた。実際に、ベストセラーコードという書物でも、同様の男女差による感情の差分が存在することが語られている。
そうなると、明らかな男性と女性の違いのようなものが見受けられたが、これは母数がもう少し必要である。そのため、検証する必要があるなと調査を深めようかと思っていたが、どうやらIBM Watsonに実装されたNatural Lang Understandingが日本語対応したことで、その悩みも解決しそうである。
このようにAPIエコシステムの良いところでもあり、悪いところでもある技術の日進月歩の進化に対し、外部リソースを上手く取り込みながら無駄を省いて効率よく実装していくということに慣れる必要がある。新機能が追加され、それまでの実装が無駄になったと思わず、それも経験でありサンクコストであると思うべきなのだ。
さて、話を戻すとそういった細かい“癖”を調査し、最も自分の出したい結果に近いものをチョイスすることが出来るのがWatsonの良いところだと思っている。ただ、より高度かつ複雑な事をやるためにはやはり自前で特殊な結果データを保有する必要がある。私たちはそれをどう定義したかというと、この折れ線グラフの“波”データ、すなわちフリークエンシー(周波数)自体が機械学習(ML)や深層学習(DL)のための前処理データとなるのではないかと考えた。MLやDLは画像による認識精度が高いわけで、大量に集まったグラフ画像と、著名作品の分析結果グラフからの差分検知こそが最初の顧客の価値になると考えている。
よく、この部分に関して評価されづらく、検出結果から自動でシナリオが生まれ、量産されることを望む方が非常に多いが、冷静になって考えてほしい。そのような魂のこもっていない作品をあなたは読みたいのだろうか? 結局はそういう物語のプロットは過去の作品から切り出して表示させただけの、まがい物にすぎない。AIは人間のオルタナティブではなく、あくまでも人間の可能性を拡張する存在だと思っている。
そのため、私は最近Argument Intelligence、拡張知能とIBMの言い方に習って話している。今はAIと言っているが将来はただの高度化されたプログラムと評価されるだろうし、AIが神と言う名の創造主にはなり得ないと考えている。AIは未だに未来を見せてはくれず、過去の物理法則に従っているだけにすぎない。
これらのように、必要な機能を必要な分だけ無駄なく利用できる“APIエコシステム”の恩恵は果てしないものだと思うし、導入ハードルが低いことで若年層の利用にも役立つ。先日のライトプランの発表も合わせて、無料でどんどん試して本格利用に望んでもらいたいと思う。私はこのように“作るな、使え”の精神でStory AIを強化している。
次回は私達のやり方をより一般化してスモールデータを活用したAIの作り方と上司の黙らせ方を深く追求してみたいと思う。

川合 雅寛
クロスリバ株式会社 代表取締役社長 兼 CEO
1980年2月生まれ、山形県出身。上京後、日立製作所にて電子政府構築、郵政民営化などに携わる。その後、ソフトバンクにて大企業向けのiPhoneを中心としたスマートフォン/G Suiteを中心としたSaaSのセールスエンジニアとして全国を飛び回り、会社のあり方を変えるクラウドを提案する活動に従事。2014年34歳のときに物語(ストーリー)を分析するクリエイティブ業界向けのソリューションを提供するクロスリバ株式会社を起業。