
How Cloud data sharing works
This topic describes how the Cloud data sharing feature works in the IBM Spectrum Scale™ cluster.
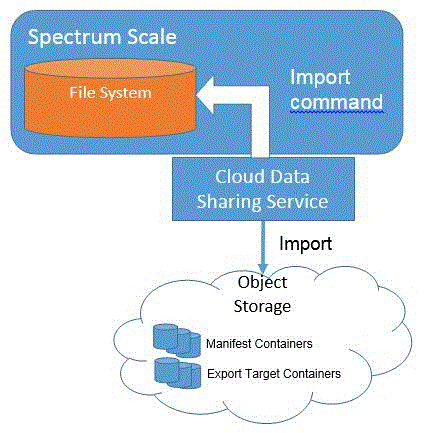
Data can be imported directly by providing a list of objects to be imported in the command itself or by providing a pointer to a manifest which contains the list of objects to be imported. The files are imported and placed in a target directory in the file system. Since the files are not yet present in the file system, there is no way to use the policy engine to initially import the files. There is, however, a way to import only the stub of the file and then use the policy engine looking at the file stub information to import the data subset that is of interest (and delete the stubs not of interest).
How to be aware of and exploit what data has been shared
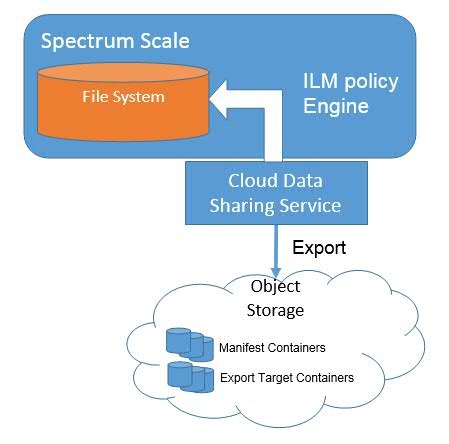
A manifest may be kept which lists information on objects that are in cloud storage available for sharing. When the Cloud data sharing service exports files to object storage, it can be directed to add entries on what it exported to a manifest. Other applications generating cloud data can also generate a manifest (more on that in the next section). The location of where the manifest is stored and when it is exported to be looked at is the decision of the application – it is not automatic. A typical time to export the manifest to object storage is in the same cron job as the policy invocation immediately following the policy execution completion so that it represents all the files exported by that policy run.
A manifest utility is available that can read a manifest and provide a comma separated value output stream of all the files in the manifest, or a subset of those files as provided by some simple filtering. This manifest utility is written in Python and can run separately from the cloud data sharing service most anywhere python can run. The utility is also built into cloud data sharing and can be used to get input for import operations.
Currently, there is no way to receive asynchronous notification of updates to what has been shared – the containers where the manifests reside must be polled.
How a native cloud storage application can prepare a set of objects for sharing
There is a simple way for native cloud storage applications or other generators of cloud object data to generate a manifest. The manifest utility can build the manifest from a list of objects that it is passed.
