
InfoSphere® MDM provides a number of different methods for maintaining the quality of your party data, and provides services that maintain a single and accurate record of each party across your enterprise.
The concept of suspected duplicate processing represents the broad category of activities related to identifying persons or organizations that are likely duplicates of each other. Each time a person's or an organization's data changes, there is a possibility that the entry in InfoSphere MDM for that person or organization is, in fact, a duplicate of another person or organization.
Maintaining high quality data is critical to all InfoSphere MDM solutions. To achieve this, it is very important that each enterprise considers how to orchestrate its people, processes, and technology to work together to manage data assets. The InfoSphere MDM suspected duplicate processing functionality can be a key piece of your larger data governance strategy.
Suspected duplicate processing is the process of searching for, matching, creating associations between and, when appropriate, merging data for existing duplicate party records in the system. Duplicate party records are known as suspect parties or suspected duplicates.
InfoSphere MDM suspected duplicate processing builds the single version of the truth for a particular party by taking suspected duplicate records provided by numerous source systems. This processed, accurate record is sometimes referred to as the golden master or golden record.
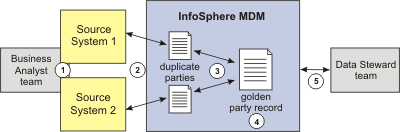
- Party data in source systems is profiled and analyzed.
- Party data is loaded into InfoSphere MDM and cleansed.
- Suspected duplicates are searched and matched.
- Suspected duplicates are linked. Golden records can be automatically created.
- Data stewards review suspected duplicates and create golden records.
Suspected duplicate processing can be a complex process, despite seeming straightforward on the surface. The complexity of the suspected duplicate processing process is driven by the fact that many organizations lack trusted information. Information is often incomplete, out of date, or inaccurate, so before you can determine how to find the duplicate party records in your enterprise, you need to figure out the topology of the data in the systems that will be contributing to your master data store. This can be done by profiling and analyzing the systems in order to better understand the nature of the data.
- Searching and matching – Identifies and determines which suspect categorization each candidate match belongs to.
- Survivorship – If there is a close enough match between two parties, each party will be allocated a score and corresponding suspect categorization. In many cases, a suspect record will be created. In the case of a guaranteed match, the information might simply be merged to form a single, golden record.
- Search and inquire for parties marked as suspected duplicates.
- Merge parties together (a process known as collapse).
- Split parties apart.
- Mark or unmark parties as suspected duplicates.