MRM TDS format
The Tagged/Delimited String format (TDS) is the physical representation of a message that has a number of data elements separated by tags and delimiters.
The TDS physical format is designed to model messages that consist of text strings, but it can also handle binary data. Examples of TDS messages are those that conform to the ACORD AL3, EDIFACT, HL7, SWIFT, or X12 standards. The TDS physical format allows a high degree of flexibility when defining message formats, and is not restricted to modeling specific industry standards; therefore, you can use the TDS format to model your own messages.
TDS message characteristics
There are a number of features of text string messages that are common to many formats. This is an overview of the main features that are supported by the TDS physical format:
The following diagram shows an example data message with each of its components labeled.
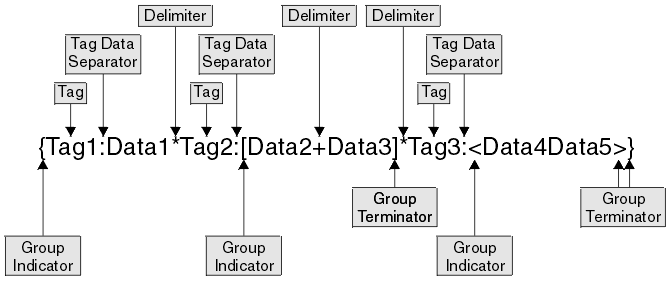
- At the top level, each data value has a tag associated with it, each tag is separated from its data value by using a tag data separator of colon (:), and the data values are separated from each other using the asterisk delimiter (*).
- The group indicator for the message is the left brace ({) and the group terminator is the right brace (}).
- The data values
Data2andData3are in a substructure in which there are no tags, and each data element is separated from the next using the plus delimiter (+). The group indicator for this substructure is the left bracket ([) and the group terminator is the right bracket (]). - The data values
Data4andData5are in a substructure in which the values are fixed length, and are therefore not separated by a delimiter. The group indicator for this substructure is the less than symbol (<) and the group terminator is the greater than symbol (>).