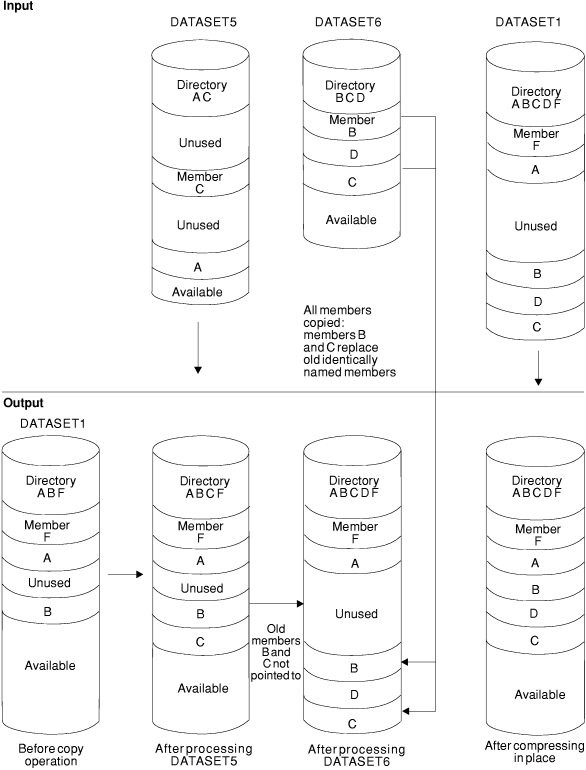
In this example, two input partitioned data sets (DATASET5 and
DATASET6) are copied to an existing output partitioned data set (DATASET1).
In addition, all members on DATASET6 are copied; members on the output
data set that have the same names as the copied members are replaced.
After DATASET6 is processed, the output data set (DATASET1) is compressed
in place. Figure 1 shows the input and output data sets
before and after processing.
Figure 1. Compress-in-Place Following
Full Copy with “Replace” Specified
//COPY JOB ...
//JOBSTEP EXEC PGM=IEBCOPY
//SYSPRINT DD SYSOUT=A
//INOUT1 DD DSNAME=DATASET1,UNIT=disk,VOL=SER=111112,
// DISP=(OLD,KEEP)
//IN5 DD DSNAME=DATASET5,UNIT=disk,VOL=SER=111114,
// DISP=OLD
//IN6 DD DSNAME=DATASET6,UNIT=disk,VOL=SER=111115,
// DISP=(OLD,KEEP)
//SYSUT3 DD UNIT=SYSDA,SPACE=(TRK,(1))
//SYSUT4 DD UNIT=SYSDA,SPACE=(TRK,(1))
//SYSIN DD *
COPYOPER COPY OUTDD=INOUT1,INDD=(IN5,(IN6,R),INOUT1)
/*
The control statements are discussed below:
- INOUT1 DD defines a partitioned data set (DATASET1), which contains
three members (A, B and F).
- IN5 DD defines a partitioned data set (DATASET5), which contains
two members (A and C).
- IN6 DD defines a partitioned data set (DATASET6), which contains
three members (B, C and D).
- SYSUT3 and SYSUT4 DD define temporary spill data sets. One track
is allocated for each on a disk volume.
- SYSIN DD defines the control data set, which follows in the input
stream. The data set contains a COPY statement.
- COPY indicates the start of the copy operation. The OUTDD operand
specifies DATASET1 as the output data set.
The INDD operand specifies
DATASET5 as the first input data set to be processed. It then specifies
DATASET6 as the second input data set to be processed. In addition,
the replace option is specified for all members copied from DATASET6.
Finally, it specifies DATASET1 as the last input data set to be processed.
Since DATASET1 is also the output data set, DATASET1 is compressed
in place. However, if DATASET1 is a PDSE, the compress-in-place operation
will not be processed.
Processing occurs as follows:
- Member A is not copied from DATASET5 into DATASET1 because it
already exists on DATASET1 and the replace option was not specified
for DATASET5.
- Member C is copied from DATASET5 to DATASET1, occupying the first
available space.
- All members are copied from DATASET6 to DATASET1, immediately
following the last member. Members B and C are copied even though
the output data set already contains members with the same names because
the replace option is specified on the data set level.
The pointers in DATASET1's directory are changed to point
to the new members B and C. Thus, the space occupied by the old members
B and C is unused. The members currently on DATASET1 are compressed
in place, thereby eliminating embedded unused space.
 z/OS DFSMSdfp Utilities
z/OS DFSMSdfp Utilities


 Copyright IBM Corporation 1990, 2014
Copyright IBM Corporation 1990, 2014