Assessing the state of the system
The first thing to do when an abnormal condition occurs is to take the pulse of the overall system and get a feel for how much or how little of the system is operational and how much of it is rendered 'out of service' by whatever the external stimuli was that caused this condition.
- Is this system still performing work?
Determine if system is still operational. Often times, a system can be operational, but because of overload or inappropriate tuning, or both, the system is not completing tasks quickly and is attempting to do work that is indeed failing.
The litmus test for each of these questions will be specific to the nature of the deployed solution.
- What special error handling support is built-in to the application?
If there is a lot of automated retry and various support logic, then the application itself might shield some errors from manifesting the IT operator.
These conditions must be known and documented for reference by the recovery team.
- Check to see if the server is at least running.
Do you see the PID or get a positive feedback from the deployment manager via the administrative console?
- Check to see if there are locks in the database(s) or any unusual
database traffic. Most databases will have facilities to look at locks. Depending on the deployment topology, there maybe multiple databases.
- Process database (BPMDB)
- Performance Data Warehouse database (PDWDB)
- Common database (CMNDB)
- Cell-only configuration database (CMNDB)
- Check to see what the status of the messaging system is. Check for events or messages in the following locations:
- Business Process Choreographer Hold and Retention Destinations
- Number of failed events
- Number of messages on the solutions module destinations
- Check to see if the database is functioning.
Can you perform some simple SELECT operation, on unlocked data in a reasonable amount of time?
- Check to see if there are errors in the database log.
If the database is not working properly, then recovering the database (so that it can at least release locks and perform simple selects) is vital to system recovery.
If the messaging system is not working properly, then recovering the messaging subsystem, so that it can at least be viewed and managed, is also vital to system recovery.
From these basic procedures and health check kinds of activities, start to look at some specific situations. Patterns will be described, specifics will be given and insights as to what is going on under the covers will be provided.
Realize that this situational analysis is a read-only activity. While it provides vital information from which to determine the appropriate recovery actions, it should not change the state of the system under review. It is impossible to predict and provide prescriptive actions for all possible causes of a system outage. For example, consider the following decision tree:
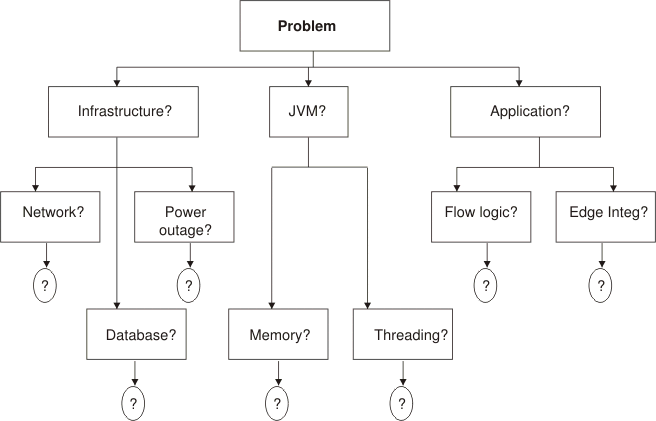
There are many broad categories to investigate in the event of an unplanned outage. These broad categories will have sub categories and so on. Defining prescriptive actions for each node and the subsequent node will depend on the results of each investigation. Because this type of relationship is difficult to convey in a document form, using a support tool such as IBM® Guided Activity Assist to interactively walk you through the investigative and decision making process is recommended. As you progress from the top to each child node, it is important to conduct the appropriate level of situational analysis.