Product Documentation
Abstract
This document describes a typical workflow for using Classification Workbench to create and fine-tune a knowledge base for IBM Content Classification Version 8.8.
Content
Overview
Typical workflow
Preparing sample data
Creating a knowledge base project by importing content
Cleaning the content set
Configuring fields for natural language processing
Training and testing a knowledge base
Creating a hierarchical knowledge base
Assessing and optimizing knowledge base performance
Note: These are instructions for creating a knowledge base by using categorized sample content in Classification Workbench. Other methods and tools for configuring classification are also available, such as defining keywords and phrases, building rules in decision plans, and using the Classification Quick Start Tool. Refer to the Content Classification information center for complete documentation.
Before you create a knowledge base, you define a set of categories and gather sample data (such as emails and documents) that is representative of the data that you expect to classify using IBM Content Classification. Then you use Classification Workbench to analyze categorized content items and create statistical models of each category by a process known as training. These category models form the basis of the knowledge base. When you use an IBM Content Classification knowledge base to classify new content, the content is compared to the category models, the best matches are found, and an automatic action is taken (such as moving documents into appropriate folders).
Related links:
IBM Content Classification Component and Configuration Quick Tour
- Gather and optionally pre-categorize sample data. This data will form the basis of a content set. If necessary, convert the data into a format that is recognized by Classification Workbench.
- Create a knowledge base project in Classification Workbench by importing the sample data.
- Edit and categorize content items, if necessary.
- Create and analyze a knowledge base, and generate analysis results.
- Evaluate knowledge base performance by viewing reports and graphs.
- Based on reports and graphs, improve knowledge base performance by editing the content set and retraining, as required.
- Publish the knowledge base to the Content Classification server and administer by using the Management Console.
Figure 1. Knowledge base development

IBM Content Classification learns to classify by using categorized sample content. You collect and organize sample content before you start working with Classification Workbench. Then you import the sample content set, such as documents or emails in folders, into Classification Workbench and then create a knowledge base.
Supported data formats include XML (extensible markup language), PST (Microsoft® Outlook folder), and CSV (comma separated values). You can also import emails and binary files such as Microsoft Word documents, PDF documents, and HTML documents from file system folders.
Importing categorized content
If your sample content is already organized into categories, Classification Workbench can use those categories to build a knowledge base. For example, your data might consist of email messages that are stored in folders, where each folder represents a category, that is, the topic of the messages in each folder. When you import this data, the folder names are automatically used as category names. You can maintain and refine this categorization using various Classification Workbench features and techniques.
Importing uncategorized content
You must assign categories to content items to build a knowledge base. The tools and techniques that you use depend on whether you already have a set of categories, that is, a taxonomy.
When you know the taxonomy, you can use various tools in Classification Workbench to assign categories to one or more content items after they are imported. When you do not know the taxonomy, you can find categories in your content by searching for text strings or finding patterns that might be indicative of categories. You can also use the Taxonomy Proposer application that is included with Classification Workbench to discover new categories in an uncategorized or partially categorized content set.
Importing content from IBM FileNet Content Manager
To import documents into Classification Workbench from an IBM FileNet® Content Manager repository, run the Content Extractor command-line tool. The Content Extractor converts documents in IBM FileNet Content Manager into XML format. You can then import the XML output into Classification Workbench.
If your documents are already classified in IBM FileNet Content Manager folders or document classes, you can create a knowledge base with a structure of categories that reflects the structure of folders and document classes in IBM FileNet Content Manager. Content Classification can use this knowledge base to automatically classify documents into appropriate IBM FileNet Content Manager folders or document classes.
Importing content from IBM Content Manager
You can create a knowledge base with a structure of categories that corresponds to item types or attribute values in IBM Content Manager. Content Classification can use this knowledge base to classify items by automatically setting appropriate IBM Content Manager item types or attribute values.
To import items into Classification Workbench from an IBM Content Manager repository, run the Content Extractor command-line tool. The Content Extractor converts items in IBM Content Manager into a content set in XML format. You can then import the XML output into Classification Workbench to build a knowledge base or test a decision plan.
Related links
Preparing data for import
Using the Taxonomy Proposer to discover new categories
Extracting content from IBM FileNet Content Manager
Extracting content from IBM Content Manager
Creating a knowledge base project by importing content
A Classification Workbench project is a container for building a knowledge base for IBM Content Classification. The following procedure describes how to create a project and import the sample data that you have prepared.
To create a knowledge base project:
- Start Classification Workbench: Click Start > Programs > IBM Content Classification 8.8 > Classification Workbench.
- On the Open Project window, click New.
- On the New Project wizard, type a project name, set the project type to knowledge base, enter a description (optional), and click Next.
- Select the Create a project by importing a content set option and click Next.
- Select the content set format in which your data is stored and click Next. Depending on the format, you can navigate to folders or files, configure filter settings, and so on. See the following links for descriptions of supported data formats:
Files from a file system folder
XML files
CSV file (comma separated values)
PST files
Classification Workbench Content Set
- Click Finish.
A progress bar is displayed, indicating that data is being imported.
When the import process is complete, the system automatically generates a content set file (project_name.cor) based on the imported data. The Field Definitions panel displays all pre-defined fields and their properties, and the Categories panel shows all categories that were identified in the content set. You use this content set to create and analyze a knowledge base by using the Create, Analyze, and Learn wizard.
Cleaning the content set
A clean, well-categorized content set used to create a knowledge base will maximize system performance. Cleanup involves removing unwanted strings (or entire content items) that would negatively impact knowledge base training and performance.
Ensure that the items in each category remain representative of the type of content that you expect Content Classification to classify in the future. Optimal results are achieved when your content set contains data that is as close as possible in content and structure to the real data that the system will classify.
Content items should include the same noise (that is, imperfections, misspellings, extraneous text, and so on), as the items that the system will encounter. If you find that removing noise (for example, a fixed pattern) improves knowledge base performance, and this same pattern will appear in real data, create a custom preprocessing script to filter the noise out of incoming data before it gets classified.
The extent to which you need to clean your content set depends on the state of your data upon import. In most cases, a content set will require some degree of cleanup. For example, an organization plans to use Content Classification to classify news articles. They build a content set by collecting and importing a number of sample news articles from the Internet. Along with the main body text, the imported Web pages include extra, seemingly unnecessary text (for example, headers, sidebars, or copyright information) that is unrelated to the news articles' content. If this extra text will not be included in actual news articles that they plan to classify, it should be removed. If they expect to classify news articles with similar text, they should leave it in. However, if they find that the extra text reduces classification performance, they should create a custom script that filters out the text before the news articles are classified.
Related link
Categorization and cleanup techniques
Configuring fields for natural language processing
In Classification Workbench, each content item is defined by one or more fields. You can view the list of fields for your content set on the Field Definitions panel.
You must configure the content type attribute of one or more fields that contain meaningful text, that is, text which you expect Content Classification to analyze. The content type determines how content is analyzed and classified by Content Classification's natural language processing engine. Typically, a field containing meaningful text is a good candidate for specifying the content type, such as a field that contains the body text of a document or the subject text of an email message.
Tip: Do not specify a content type for fields that contain non-textual values (for example, account numbers, telephone numbers, and so on) or non-meaningful text (for example, a field containing administrative comments about each content item). In some cases, the best classification results are achieved when the content type is set only for the most relevant fields.
To set the content type for meaningful fields in your content set:
- On the Field Definitions panel, right-click a field name and select Edit Field.
- Set the Content type property to one of the following options:
- Body - For email environments only: select this option for fields that contain the main body text.
- DocTitle - Select this option for fields that contain document titles.
- PlainText - Select this option for fields that contain textual content. This option is recommended for Enterprise Content Management (ECM) environments.
- Sender - For email environments only: select this option for the "Sender" or "From" field that contains an email address.
- Subject - For email environments only: select this option for a "Subject" field that contains the subject of an email message.
Related links
Field properties
More about natural language processing
Training and testing a knowledge base
The training process in Classification Workbench uses a categorized content set to create statistical models of each category that will make up the knowledge base. The testing process simulates how content items are classified by Content Classification by using the trained knowledge base and returns suggested categories (also known as matches). The returned categories are compared to the categorization information that is a part of each item in the testing set. The differences between the expected category results and the actual results form the basis for evaluating the knowledge base.
Typically, you use Classification Workbench to create and analyze a knowledge base in a single process by using the Create, Analyze, and Learn wizard. The main content set is divided into two parts. The first part, known as the training set, is used to create the knowledge base. The other part, known as the testing set, is used to analyze the performance of the knowledge base when classifying data.
Figure 2. Splitting the content set for training and testing
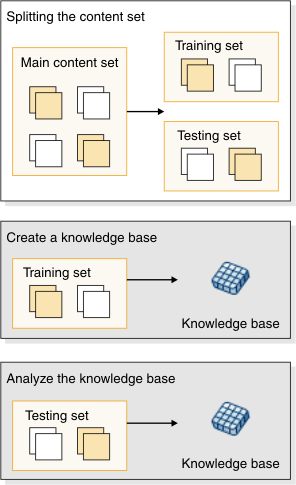
Classification Workbench can divide the main content set in various ways as indicated by the options on the Create, Analyze and Learn wizard. Each option will yield different results by creating and analyzing with different sets of items.
Before proceeding
- Verify that your content set has at least one field that is designated as the categories field. The data type of this field must be set to classification.
- Verify that all content items are categorized (that is, a category name is specified in the designated category field for every content item).
- Verify that the content type field property has been correctly set for each field with meaningful text.
- Verify that you are viewing all items in the content set window that you want to use to create and analyze a knowledge base.
To create and analyze a knowledge base:
- On the toolbar, click Create, Analyze and Learn (F9).
- Select one of the Create and Analyze knowledge base options and click Next.
- In the Knowledge Base area, select Create new knowledge base, deleting any existing knowledge base in this project.
- In the Automatic reporting area, select the Create Summary Reports option to generate reports. You can click Select Reports to specify the reports that you want to generate.
- Click Next, accept the default analysis option values, and then click Finish to start creating and analyzing the knowledge base. This can be a lengthy process, depending on the number of items in your content set, their length, the number of categories in your project, and the available processing power and memory in your system. When the process is complete, click OK on the status window. Reports are displayed in a browser window. You can analyze the results using the system's graphical diagnostics.
Note: Some items might not be processed during the create and analyze process (for example, if the body field is empty). For more details, refer to the project log at the bottom of the main window.
Related links
Knowledge base building overview
Creating and analyzing a knowledge base
Procedures for creating and analyzing a knowledge base
Creating a hierarchical knowledge base
By default, a knowledge base consists of a flat list of categories. In some situations, it is recommended to create a hierarchical knowledge base that contains sets of nodes and categories at different levels of the knowledge base tree. You use the Knowledge Base Editor, an application that is embedded in Classification Workbench, to manually create a knowledge base tree structure or modify existing knowledge bases.
Some situations where a hierarchical knowledge base is recommended:
- You want to classify content in multiple languages.
- You want to distinguish between similar categories. You can improve classification performance by positioning two similar categories under the same principal node in a knowledge base tree. See Finding overlapping categories.
- You want to divide a statistical category into several subcategories based on the value of a content field. For example, your content items might have a channel field that is either secure or unsecure. You can create a rule node in a hierarchical knowledge base that directs content items to different sets of categories depending on the field value. See Finding categories determined by external factors.
Example: Hierarchical knowledge bases for multilingual support
When you need to classify content in multiple languages, you create a hierarchical knowledge base where each language appears as a separate branch in the hierarchy with dependent branches of categories. Each language is represented as a node under the root node. Categories that are specific to each language are under the appropriate language node. A simple rule is defined for each language node that directs content items for classification to the categories under each language node.
Figure 3. Multilingual knowledge base displayed in the Knowledge Base Editor
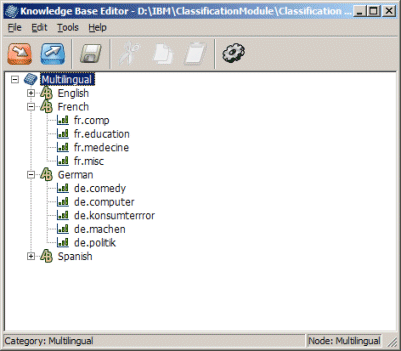
Related links:
Using the Knowledge Base Editor
Assessing and optimizing knowledge base performance
This section summarizes techniques that you can use to assess and optimize the performance of your knowledge base.
Tip: Use the Classification Workbench Workflow Assistant to guide you through the process of evaluating and fine-tuning your knowledge base. For instructions, click the Assess and optimize knowledge base performance link on the Workflow Assistant after you create and analyze your knowledge base.
Viewing summary reports and graphs
Summary reports and graphs can help you assess the overall performance of your knowledge base. To view summary reports and graphs, click Reports on the Analysis menu, or click Reports on the toolbar.
The reports and graphs that you choose depend on the way that you will use Content Classification to classify content. For example, view the Cumulative Success summary reports and graphs if you will use Content Classification to take action on high-scoring categories, such as displaying the top five suggested responses to a call center agent. For another example, if you want to maximize precision or recall (for example, for an automatic email response system using thresholds), view the Total Precision vs. Recall graph. See the following links for descriptions of reports and graphs:
Summary report: Cumulative Success
Summary graph: Cumulative Success
Summary graph: Total Precision vs. Recall
Examining large and important categories
After you review summary reports, you can improve knowledge base performance by carefully examining the largest categories, that is, categories that are assigned to the most items. You should also examine the most important categories, that is, particular categories for which you require high accuracy.
Large and important categories have the most impact on performance. However, the following techniques also apply to smaller or less important categories. Some common types of problematic categories follow:
- Catch-all categories - These tend to be large categories that include multiple intents. In some cases, the performance of catch-all categories is acceptable; however, these categories tend to negatively influence other categories in the knowledge base. For example, a catch-all category called "Fees" might contain numerous subcategories that, when split apart, will improve system performance. In email environments, "spam" is a common catch-all category that reflects many intents (promotions, sale items, and so on).
- No intent categories - These categories do not have associated intents. No intent categories often appear when a response is required that does not relate to the question. For example, a company might have a "No response necessary" category. Remove these categories from your knowledge base. Process no intent categories on the application level.
To find large categories:
- Open the Content Summary report.
- Click twice on the % of Content Set column heading. This action sorts the categories in descending order from biggest to smallest. Categories that are associated with the most items are at the top of the list. Troubleshooting large categories first will have the most impact on the overall performance of your knowledge base.
Viewing category reports and graphs
Similar to the summary reports and graphs, Classification Workbench provides reports and graphs to analyze and troubleshoot specific categories. To view category reports and graphs, click Reports on the Analysis menu or click Reports on the toolbar. Then click the Category Reports and Tables tab on the View Reports window.
The category reports and graphs that you choose to view depend on the way that you will use Content Classification to classify content. For example, view the Cumulative Success category reports and graphs if you will use Content Classification to take action on high-scoring categories, such as displaying the top five suggested responses to a call center agent. For another example, if you want to maximize precision or recall (for example, for an automatic email response system using thresholds), view the Precision-Recall vs. Threshold category graph.
See the following links for descriptions of category graphs:
Category graph: Cumulative Success
Category graph: Precision-Recall vs. Threshold category graph
Improving knowledge base performance
You can begin improving knowledge base performance by finding and removing irrelevant patterns from your training set. It can also be helpful to identify categories that are determined by an external factor, and to find overlapping categories.
Perform these steps sequentially. Before making changes, save a backup of your knowledge base project
Finding patterns in content items
You might want to clean your content set further by removing recurring text strings (for example, patterns such as email headers and footers) to improve knowledge base performance. Use the Find Patterns feature to identify recurring text strings in content items.
Remember that the content set must be representative of the data that you expect Content Classification to classify in a production environment. If removing a fixed pattern improves knowledge base performance, and this same pattern will appear in production environment data, use a custom preprocessing script to filter out this text string from the incoming data before the data is classified by Content Classification.
Finding overlapping categories
Categories overlap when Content Classification does not perceive a clear difference between them. Use these features to find overlapping categories:
- The Knowledge Base Data Sheet provides a list of overlapping categories. You might want to unite two overlapping categories, define the categories more distinctly, or position the two similar categories under the same principal node in the knowledge base tree.
- The Stealing/Stolen table provides insight into which categories are perceived to be similar by Content Classification. This table shows categories that are "stealing" items and having items "stolen" from each category.
- The Possibly Stolen filter identifies items that are being stolen by another category. Sort by the Categories column and compare it to the Match1 column. Some items might be consistently categorized into the wrong category, which possibly indicates overlapping intents.
- The Content Item Scoring category graph shows "stray" content items that do not appear in their expected areas of the graph. For example, several dark (maroon) points might appear near the upper portion of the graph where light (blue) points are expected. Double-click these items to view them and note their categories. If several of these stray content items belong to a different category, this might indicate that the categories are similar and they should be combined.
You can improve knowledge base performance by carefully redefining each of the categories, recategorizing content items, and retraining the knowledge base.
Begin investigating the reasons why categories overlap by reading their descriptions or associated standard responses (if available). Next, review the text of items assigned to each overlapping category.
For example, if you find that categories A and B overlap, begin by reviewing items originally assigned to category A that received the highest scores in category B. Then, review items assigned to category B that received the highest scores in category A.
If two separate categories are the same and were split by mistake, combine them into one category.
Advanced users: If two categories are similar but you still want to keep them separate, use the Knowledge Base Editor to create a statistical hierarchy by placing each category under the same principal node. If two categories can be distinguished according to an external factor and not by the text, add this factor to the item as a field. Then, define a knowledge base rule that checks the value of this field.
Finding categories determined by external factors
In some cases you can improve the performance of your knowledge base by identifying categories that can be determined by an external factor that is not dependent on text analysis.
For example, a company’s knowledge base has a category and associated response that should always be assigned to an incoming email inquiry if the sender is not in the company database. This category is assigned regardless of the content of the message.
In another example, a company’s knowledge base is designed to handle balance transfer inquiries received from both secure and unsecure channels. Channel security is an external factor that determines which categories are returned. This company's knowledge base includes a Balance Transfer category with a principal rule node below it that branches into Secure and Unsecure nodes. Each node has unique associated answers.
To find categories determined by external factors:
- View the Knowledge Base Data Sheet. This report provides a list of categories that might be determined by external factors. Check whether each category can be determined by an external factor by reading its description or canned text response (if available) or by viewing some of its content items.
- You can add a field to your content set that contains the external data. Then write a knowledge base rule that determines which conditions must be met for the category to be assigned.
- In some cases, it might be more appropriate to add an application-level rule which identifies and acts on a content item before it reaches your Content Classification-based system.
Threshold analysis
Thresholds are percentage values associated with categories in the knowledge base that can be used by Content Classification applications to determine whether to take automatic actions, such as classifying documents into appropriate locations in a repository, or declaring emails as records.
If you plan to set thresholds for categories in your knowledge base, you can use the Threshold Calculator in Classification Workbench to:
- Choose an optimal threshold based on scores that is explicitly calibrated for automation.
- Experiment interactively with different thresholds to determine the best balance between precision and recall.
- Choose a threshold that matches your desired cost ratio.
The Threshold Calculator is populated with the Content Item Scoring graph. Each point on the graph represents a single item in the content set. The threshold level is represented as a horizontal line that provides immediate visual feedback on how many content items exceed the specified level. See the related links for examples and workflows.
Related links:
Threshold Calculator
Setting thresholds
Was this topic helpful?
Document Information
Modified date:
17 June 2018
UID
swg27020839